Zugegeben: Ich hatte nicht damit gerechnet. Ich hatte nicht gedacht, dass die neue Bildersuche von Google tatsächlich genau so funktionieren würde, wie es in der Ankündigung und den ersten aufgeregten Berichten klang. Ich hatte Google vielleicht die Dreistigkeit zugetraut, aber nicht die Dummheit.
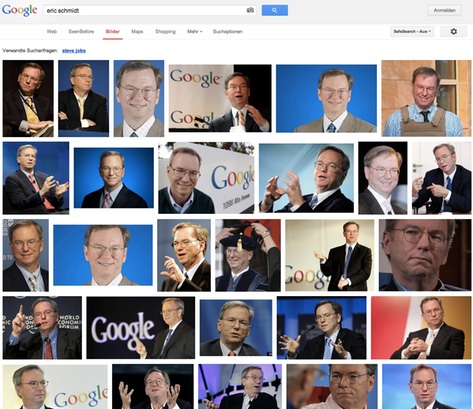
Bislang führte ein Klick auf eines der kleinen Vorschaubilder in der Übersicht immer auf die Seite, auf der das Original zu sehen war. Jetzt führt er zu einer Anzeige des Bildes innerhalb der Suche. Der Nutzer muss also die Ergebnisseite gar nicht mehr verlassen, um sich die Bilder in voller Größe anzeigen zu lassen.
Bisher:
Neu:
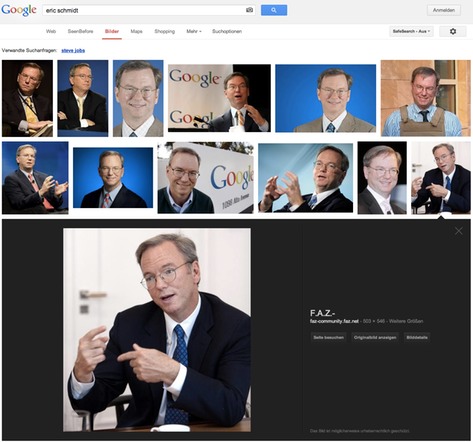
Man kann mit der Tastatur einfach durch die gefundenen Bilder blättern, ohne Google verlassen zu müssen. Das ist zweifellos sehr praktisch. Google hat die Bildersuche für die Nutzer und für Google optimiert. Die Interessen der Urheber und Rechteinhaber spielten dabei erkennbar keine Rolle.
Wenn Google behauptet, dass die Änderung auch den Seitenbetreibern zugute kommt, ist das offenkundiger Unsinn. Google verweist darauf, dass nun gleich vier Links vom Suchergebnis zur Quellseite führen. In Tests habe sich zudem gezeigt, dass mehr Leute vom Ergebniss zur Quelle klicken. „Wir können erkennen, dass durch das neue Design bei einer typischen Suche durchschnittlich ein höherer Click-Through-Wert erzielt wird als früher“, sagt Google-Sprecher Kay Oberbeck.
Was er dabei ignoriert: Bislang war es in vielen Fällen gar nicht nötig, zur Quelle durchzuklicken, die Seite wurde ohnehin angezeigt, mit all den Informationen oder Anzeigen, die sie im Original umgeben. „Durchklicken“ bedeutet bei der alten Bildersuche bloß, die Seite aus dem Rahmen zu befreien, neben dem rechts noch die Google-Informationen angezeigt wurden. Bei der neuen Bildersuche bedeutet „Durchklicken“, die Originalseite überhaupt zum ersten Mal zu sehen bekommen. Diese beiden Werte miteinander zu vergleichen, ist sinnlos und dient bloß der Propaganda.
Dass Fotografen nach ersten Auswertungen feststellen, dass ihre Seiten von der neuen Bildersuche wesentlich weniger Besucher bekommen, ist absolut plausibel.
Genau genommen kopiert Google übrigens die Bilder nicht, es bindet sie nur von der fremden Seite ein. Auf dieselbe Weise liegt das folgende, mutmaßlich urheberrechtlich geschützte Bild zum Beispiel nicht auf meinem Server, sondern ist einfach nur von der Quelle eingebunden:

Das ist technisch ein Klacks, aber aus guten Gründen verpönt und ändert nach meinem Verständnis auch nichts bei der Beurteilung der Frage, ob das Vorgehen von Google legal und legitim ist.
Der Bundesgerichtshof hat 2010 die alte Bildersuche für rechtmäßig erklärt, musste dafür aber auch schon einige Verrenkungen vornehmen. Die neue Form, die die vollständige Anzeige urheberrechtlich geschützter Werke ermöglicht, hat keinen entsprechenden Schutz verdient.
Vorige Woche wurde noch spekuliert, dass die Bildersuche in Deutschland aufgrund der Rechtslage und der öffentlichen Debatte anders aussehen könnte. Doch über Google.com ist sie längst auch aus Deutschland und auf deutsch in der urheberfeindlichen Form zugänglich.
Mit der Diskussion um ein Leistungsschutzrecht für Presseverleger hat der Streit um die Google-Bildersuche eigentlich nichts zu tun, denn beim Leistungsschutzrecht geht es ja gerade nicht um die Anzeige ganzer Werke, sondern kleiner und kleinster Ausschnitte daraus. Aber in einem wichtigen Punkt gibt es natürlich doch einen Zusammenhang: Google verhält sich hier in exakt der rücksichtslosen und dreisten Weise, die die Verleger und andere Kritiker dem Konzern sonst (nicht immer zu recht) vorwerfen. Und hier passt sogar die vom Oberverlagslobbyisten Christoph Keese sonst gerne falsch verwendete Metapher vom Lichtschalter: Seiten können nur entscheiden, ob ihre Fotos in der Bildersuche auch im Original angezeigt werden — oder gar nicht.
Diese neue Bildersuche zu einem Zeitpunkt zu starten, zu dem Google so unter kritischer Beobachtung steht, zeugt von einem außerordentlichen Maß an Dummheit.
Ich hab die neue Suche noch nicht und bin mir auch nicht sicher, ob ich das ganz so schlimm finde, vermutlich, weil ich nicht betroffen bin.
Wenn die Bilder aber nicht kopiert werden, sondern nur eingebunden, sollte es kein großes Problem sein, Bilder, sobald sie in der Google Bildersuche in groß angezeigt werden, durch etwas anderes zu ersetzen, z.B. einen Hinweis darauf, dass man doch bitte die Seite zum Bild aufsuchen solle.
Sehr schöner Beitrag! Es vergeht kaum ein Monat, in dem die nicht irgendeine Änderung vornehmen…da soll noch jemand durch blicken. Mal sehen, ob es damit noch Probleme gibt. Was die Gema bei You-Toube kann nun also bald auch bei der Bildersuche passieren!?
Die Überschrift ist, um im Sprachstil zu bleiben, einfach saudumm. Für mich als Nutzer ist die neue Bildersuchfunktion einfach genial, weil viel benutzerfreundlicher. Würde der Title heißen „Wie die neue Google-Bildersuche Urherber verletzt“ hätte ich den Post auch gerne zu Ende gelesen und die neue Bildsuche aus einem anderen Blickwinkel betrachtet. So verschenkt der Artikel einen möglicherweise für die Sache Interessierbaren, weil es einfach oberfläch, dreist und dumm getitelt ist. In meinen Augen keine seriöse Berichterstattung.
Ich frage mich, warum Google das tut? Ist es Dummheit oder Arroganz? Oder eine teuflische Kombination aus beidem?
Hatte zuletzt über die LSR-Kampagne gebloggt. Bleibt – leider – aktuell: „Das LSR ist blöd, Google aber auch“ http://sensatzionell.blogspot.com/2012/11/lsr-google.html
Und wie beim Leistungsschutzrecht wird hier vergessen, dass das Fremdeinbinden von Bildern per htaccess verhindert werden kann. Ich glaube sogar, dass man die Bild-Indexierung über die robots.txt ausschalten kann.
Hauptsache erst mal eine Unterschriftenaktion losgetreten. Jeder der da unterschreibt, kann sich also nicht mehr über die Verlage aufregen – man ist schließlich genau so schlau.
@Jürgen Messing: Es wäre auch viel „benutzerfreundlicher“, wenn man alle Texte direkt bei Google lesen und sämtliche Filme direkt bei YouTube ansehen könnte.
Aha, Google zeigt die Folterinstrumente. Wenn sie das mit den News-Seiten auch so machen, haben die Verlage bald weniger Werbeeinnahmen. Oder verstehe ich das falsch?
@Hendrik: Ja, man kann das über die robot.txt ausschalten. Lichtschalter, ein, aus, Keese, s.o.
@Hendrik
Super Lösung und das dann für jede Suchmaschine. Google begeht hier Urheberrechtsverletzungen und ich als Content-Anbieter muss für Abhilfe sorgen?
Hmmm, ich hab so eine Suche nicht – bei mir wird nach wie vor die „alte“ Suche angezeigt.
Ich wäre aber ein typischer Betroffener . Als Fotograf und Bildgestalter fände ich das schon mehr als nur unschön, wenn man direkt meine Bilder sehen und herunterladen kann, ohne auch nur einen Klick auf meiner Homepage hinterlassen zu haben …
So praktisch das für den „normalen“ Benutzer sein mag, für mich (als einer der von seinen Bildern lebt) ist das mehr als nur unfair und ob das Rechtens ist, wage ich zu bezweifeln …
@jko: Auf google.de gehen -> unten rechts auf google.com klicken -> Bildersuche
@5 Es geht ja hier nicht darum, dass man die Bilderindexierung auch ausschalten kann, sondern dass google hier den impliziten Vertrag (Content gegen Traffic) bricht.
Genau das ist ja was google immer behauptet.
Ich bin ein Fan von google Produkten und sehe bei google news z.B. klar eine Leistung von google fuer die Verlage, aber bei der Bildersuche kann man nun entweder aussuchen, gar nicht gefunden zu werde oder das google die Bilder und Bandweite des Webseiten-Betreibers nutzt, ohne dafuer Besucher zu generieren.
Google hat mittlerweile generell eine Tendenz Dinge selbst anzubieten: In den USA wird zum Beispiel das Kinoprogramm angezeigt ohne, dass man direkt zum Kino durchklicken kann (um z.B. ein Ticket zu kaufen). Statdessen landet man auf einer anderen Seite von google und muss dass das Kino noch einmal explizit googeln …, google-shopper funktioniert aehnlich.
Klar, für den User an sich ist es top. Ich habe selbst auch schon sehr oft drüber nachgedacht wie schön es doch wäre, bräuchte ich nicht mehr extra auf die Seite wechseln um das Bild in seiner vollen Größe zu sehen… aber für die Webseiten Betreiber und die Rechte an sich, ist das schon ein gewaltiger Tritt in den A…. von Google…
@Stefan: Danke für den Hinweis!
@Max: Technisch ist das möglich, tatsächlich bezweifle ich aber, dass sich ein nennenswerter Teil der Nutzer die Mühe machen würde, die Ergebnisseite zu verlassen und sich für ein einziges Bild durch die Quellseite zu wühlen, wenn es einfacher ist, weiter zum nächsten Bild zu klicken. Für die Nutzer ist die neue Suche besser, weil sie schneller zum Ergebnis kommen. Natürlich wäre ein von dir vorgeschlagener Hinweis für die Nutzer kaum weniger umständlich als die alte Bildsuche, aber so lange sich nicht der überwiegende Teil der Websites dagegen auflehnt, sind direkt eingebundene Bilder für die Nutzer deutlich bequemer.
Ich würde außerdem vermuten, dass man als Seitenbetreiber mit solcher Aufmüpfigkeit sein Ranking verspielt, weil Google kein Interesse daran haben kann, dass man seinen Nutzern Steine in den Weg legt.
Vielleicht ist das ja eine blöde Frage, aber: Wurde bei der alten Suche ein Bild ausgewählt, wurde die vollständige Ursprungsseite in einem Frame eingebettet, immer noch auf einer Google-Seite wohlgemerkt. Oder sehe ich da etwas grundsätzlich falsch?
Wenn man jetzt argumentiert, Google mache sich das Bild zu eigen, dann hätten man doch früher argumentieren müssen, Google mache sich den gesamten Inhalt der Ursprungsseite zu eigen. Und genau DAS wäre doch ein super Beispiel für etwas, das unter das Leistungsschutzrecht fallen würde. Oder?
Da muss ich leider Herrn Messing zustimmen. Was hat das mit „dumm“ zu tun? Und dreist ist es nur, weil die amerikanische Sicht der Dinge und ein modernerer Ansatz zum Urheberrecht verfolgt wird? Aus „unsrer“ konservativen Sicht bzgl. Copyright und Internet (Bspl. Verlage, Gema, … ) ist das alles natürlich höchste verwerflich. Die Frage ob es vielleicht praktikabel und sogar besser ist, stellen sich die meisten nicht. Ich bin selbst als Fotograf tätig und beschäftige mich aus diesem Grund auch mit dem Recht am eigenen Bild. Jeder sollte wissen, dass es in der eigenen Verantwortung liegt, was wie und wo veröffentlich wird. Google für laxen Umgang mit der eigene Privatsphäre verantwortlich zu machen ist kurzsichtig und albern.
@jko
Geh mal auf die Startseite von Google und Klick rechts unten auf „Google.com“ – dann solltest du die neue Bildersuche zu sehen bekommen.
Das „Hotlinking“ von Google hat übrigens noch andere Nebeneffekte: So kann man die Bilder nämlich beim Aufruf austauschen. Hatte dazu vor einigen Tagen ein Video gemacht: https://www.youtube.com/watch?feature=player_embedded&v=qoy6mq5idBA
Ist leider inzwischen auf Grund der Weiterleitung so nicht mehr nachvollziehbar, aber dafür wird das Bild jetzt als solches direkt in der Bildersuche angezeigt: http://bit.ly/TyNztW
Grüße
Pascal
Alles was dem User dient, dient in der Folge auch den Anbietern. Man muss sich nur darauf einstellen.
Man kann in Zukunft mit der Bildauswahl eine Abgrenzung zumWettbewerb schaffen. Bilder und deren Qualität werden wieder wichtiger.
Das ist nur zu begrüßen. Der einzige Nachteil daran ist, die Anbieter müssen schon wieder denken und innovieren. Aber auch das ist kein wirklicher Nachteil. Es trennt die digitale Spreu vom digitalen Weizen und belohnt die, die es auch verdient haben.
Und wer mit Unterschriften-Sammlungen versucht die Zeit anzuhalten, wird sehen, dass der Abstand zu denen, die sich den Veränderungen positiv stellen, schnell größer – schnell zu groß wird.
Schön, wenn die Bildersuche und vor allem die Probleme damit „nur“ urheberrechtlicher Natur wären oder „nur“ eine Frage der Privatsphäre – dass dem nicht so ist, zeigen erste Rückmeldungen bezüglich „Einbrüchen“ bei Traffic und Adsense aus dem Webmasterworld-Forum. Eine Linkliste und Zusammenfassung möglicher Schritte gibt’s hier:
http://blog.heikerost.com/photos/google-bildersuche-re-design-und-urheberrecht/ (24.01.2013)
und
http://blog.heikerost.com/photos/imagesearch_drittbilder/ (31.01.2013)
Heike Rost sprach es schon an. Auch „die Amerikaner“ beschweren sich schon massiv eben über fehlenden Traffic und ausbleibende Einnahmen.
Btw: Bing führte eine neue Bildersuche schon Mitte/Ende 2012 ein, mit dem selben Ergebnis.
>Alles was dem User dient, dient in der Folge auch den Anbietern. Man muss sich nur darauf einstellen.
Das ist ein cooles Argument. Was will der User? Alles kostenlos und direkt und ohne Werbung. Und das nützt natürlich den Anbietern…
für den Website-Betreiber ist es doch nicht schwierig, den Referrer zu prüfen und das Bild ggfs. nicht auszuliefern oder mittels 301/302-Redirection zu erzwingen, dass die Startseite zu dem Bild aufgerufen wird. Alternativ könnte er statt Redirect auch 404 liefern.
Viele Daily-Comic-Seiten machen das so, damit man nicht den Comicstrip allein aufruft, sondern die gesamte Seite mitsamt Werbung.
Bing ist vermutlich hierzulande noch nicht größer aufgefallen, Stichwort Marktanteil.
Man kann sich als Rechteinhaber aussuchen, ob die Bilder bei Google indexiert werden oder nicht. Man kann sich nur nicht aussuchen, WIE sie indexiert werden. Was daran von Google dreist oder gar dumm sein soll, bleibt mir unklar.
Ja, das hat sich so ziemlich jeder gedacht, als die Bildersuche angekündigt wurde. Bing hat sich den Rant auch schon abgeholt. Die zeigen jetzt immerhin den Inhalt der Webseite an, aber so richtig toll ist das auch nicht.
Grüße, Alex.
Wo ist denn das Problem: Der Lichtschalter-Vergleich ist auch „dumm“, denn ich kann verhindern, dass das Original angezeigt wird und trotzdem Google noch meine Bilder indiziert und wie bisher anzeigt.
@20. Heike Rost: Das empfinde ich gerade als Vorteil aus User-Sicht. Man kann viel gezielter klicken und diese ganzen Heißluftklicks fallen weg. Wenn das bei allen so ist, ist es auch kein Problem. Und die Werbetreibenden werden auch froh sein, wenn sich die Zahlen auf ein seriöses Maß reduzieren.
Wenn der erste die neue Suche kreativ nutzt, ist es für alle anderen ein Problem. Also nicht in eine technische Abwehrhaltung verfallen, sondern angreifen und kreativ werden.
Es ist doch nur eine Frage der Zeit, bis man in Google News nicht mehr nur die Snippets, sondern den gesamten Artikel wird lesen können. Das wird nicht heute, nicht morgen, aber ziemlich sicher übermorgen geschehen. Niemand hätte damit gerechnet, dass Google die Bildersuche in dieser Weise verändert, genau so, wie niemand daran glaubt, dass komplette News-Artikel in Google eingebettet sein werden.
Wir sehen das ja schon an der Knowledge-Graph-Box, die in vielen Fällen schon die Informationen auf der Ergebnisseite bieten, die man eigentlich gesucht hat. Niemand muss sich mehr extra auf eine Wetter-Seite begeben müssen. Schon jetzt klickt man nur noch in Ausnahmefällen auf den Link zu imdb.com, denn wenn man den Titel eines Films oder den Namen eines Regisseurs, Schauspielers eingibt, erhält man umfassende Informationen bereits „auf Google“.
Das ist alles nur der Anfang.
@Heiko Rost
hier noch nicht, in den USA schon.
@Tom, #17: Warum es dumm ist steht im letzten Absatz. Vielleicht lesen Sie den Artikel mal zuende?
Sagen wir es so: Mich als Hobbyseitenbetreiber freut diese Änderung sogar. Ich zahle jeden Monat meine 5€ für den eigenen Server aus eigener Tasche und versuche auch nicht die 1,5 Biere wieder durch Werbung oder ähnliches wieder zu erwirtschaften. Vielen anderen Urhebern wird es ähnlich gehen – jeder, der seine Bilder bei kommerziellen Bloghostern, Flickr & Co veröffentlicht, verdient damit keinen Cent.
Ich hatte sogar schon mal überlegt, ob ich die Bildersuche einfach aussperren soll. Darüber kommt nur unqualifizierter Traffic – Leute, die eben schnell ein Bild wollen, um das irgendwo in einem Forum zu posten oder es sonstwie zu nutzen, die aber an den eigentlichen Inhalten nicht interessiert sind. Im letzten Monat ging ein Gigabyte Traffic bei mir drauf, weil irgendein russisches Forum ein Bild hotlinked hat. Das ist ok, Traffic ist genügend da, aber mir als Seitenbetreiber bringt das nichts.
Ansonsten: Irgendwie habe ich kein Mitleid mit Seitenbetreibern, die wegelagernderweise Leute, die eigentlich nur ein Bild suchen, mit Werbung zuspammen. Da gibt es Seiten, die sind gar unglaublich – und wer sein Geschäftsmodell auf Google aufbaut, ist eben auch von Google abhängig.
@22 Joachim Graf: Die Klickzahlen sind überall so dramatisch aufgeblasen, dass eine Nivellierung dem ganzen System gut tut.
Und so lange die meisten Angebote keinen Grund liefern, für sie zu bezahlen, darf man sich nicht wundern. Zudem haben die Inhalteanbieter den Markt zumeist selbst versaut.
Jetzt raus aus der Schmoll- und Kampf-Ecke und kreativ mit der Situation umgegangen und alles wird für alle besser. Irgendwann kann man das Geheule der Branche auch nicht mehr hören. Es gibt genug gute Ideen im Markt. Man muss sie auch einfach mal angehen.
So wie Google jetzt. Hätten die sich vor Jahren auf Stillstand und Kampf reduziert, gäbe es die nicht mehr. Nein, sie haben ständig innoviert und die Pace gemacht. Jetzt bitte nicht sagen, die sind ja auch so groß und können sich das leisten. Die haben das auch schon gemacht, als sie klein waren und sich das nicht leisten konnten. Deshalb sind die jetzt so groß.
@Hendrik
Nein, das ist praktisch eben nicht möglich. Theoretisch könnte man das über eine Abfrage des UA auf „googlebot-images“realisieren – das wäre dann aber Cloaking; eine Technik die Google in seinen Richtlinien ausdrücklich verbietet.
@32 MS: Ich sehe da auch Chance für mehr Qualität.
Herr Kremer hat bestimmt auch eine tschakka-Lösung für das rechtliche Problem die diese Bildersuche mit sich bringt.
Gerade was Bilder mit Personen anbelangt.
Die Aufregung ist auch nicht notwendig. Google ist eine AG und macht demzufolge, was eine AG machen will/muss in Punkto Profitabilität, innerhalb des rechtlichen Rahmens.
Von Ethik, Good Will und Benefits für irgendwelche Parteien zu reden oder in alten Zeiten zu schwelgen ist reine Zeitverschwendung.
Ihr abschliessender Satz drückt das im Wesentlichen aus.
@36 JMK: Hat er nicht.
Aber wenn man sich an den Problemen aufhält, wird man links und rechts von denen überholt, die eher den kreativen Umgang mit einer neuen Situation und eigene Vorteile suchen, anstatt sich auf schlechten Umgang und die eigenen Nachteile zu konzentrieren.
Sie werden die Dynamik nicht stoppen. Aber die Dynamik könnte irgendwann Sie stoppen. Und wer weiß, von dem die Ideen dann waren…:-)
Ich verstehe grad gar nicht, warum alle die neue Funktionsweise als Vorteil für den Suchenden sehen. Mir geht durch das ausschließliche Anzeigen des Bildes nämlich der Kontext des Bildes verloren. Aber wer nur nach lustigen Katzenbildern sucht, dem reicht das wahrscheinlich.
Da hier ja wieder ein paar Kommentatoren meinen, sie hätten wenig Mitleid mit den Urhebern, weil sie sich einfach der neuen Zeit („digitales Zeitalter“) anpassen müssen:
Was will man mit neuen Geschäftsmodellen, wenn einem ein Konzern den Content und damit das Geld vor der Nase wegschnappt? Da kann man noch so viele Flattr-Buttons auf seiner Site haben, wenn dort niemand mehr vorbeischaut.
All die neuen Geschäftsmodelle, die uns Silicon Valley via ein paar Netzaktivisten predigt, beruhen darauf, seinen Content kostenlos zur Verfügung zu stellen. Man solle sich vom „alten“ Geschäftsmodell verabschieden, dass eigentlich nur darauf beruhte, dass jemand, der Content konsumiert, ihn auch bezahlen sollte. Wer das heute noch fordert, wird als jemand abgestempelt, der gegen die „Freiheit des Internets“ ist.
Es ist schon reichlich perfide: Google gräbt als nun Urhebern den Traffic ab, die dann irgendwann ihre eigene Site schliessen können. Wie praktisch, dass Google dann gleich Ausweichmöglichkeiten bietet, wo man seinen Content hochladen kann.
Vor noch nicht all zu langer Zeit dachte ich, Google wäre unbesiegbar und unzerstörbar. Nun bin ich der Meinung, dass sie irgendwann daran zu Grunde gehen werden, dass die Content-Quellen austrocknen.
Wir kennen die Quartalszahlen von Google. Währenddessen:
http://www.businessinsider.com/the-state-of-media-employment-2013-1?op=1#ixzz2Jlul3jsY
Ich tue mich etwas schwer, wenn ich einerseits gegen das LSR bin, dann aber jammere wenn mein Content „missbraucht“ wird.
Ja, es ist etwas anderes, aber eher graduell, als prinzipiell. Ich glaube nicht, dass Vorschriften hier irgendeinen Sinn haben, denn gerade Bilder sind noch viel internationaler als Texte in einer Landessprache, viel internationaler als deutsche Gesetze.
Es wird also nur sinnvoll sein eine intelligente Lösung zu finden. Es würde sich anbieten, beim Aufruf durch Google ein gleiches aber hochgerechnetes Bild zu verlinken, das wesentlich größer ist. Größer 5MB z. B. Ich vermute, dass Google da irgendwo eine Grenze setzt, oder rechnen sie jedes Bild auf eigenem Server auf eine passende Größe um. Ansonsten werden User die Google-Bildersuche bald nicht mehr sinnvoll nutzen können.
Naja, da wird schon jemandem ein kluger Trick einfallen.
Mir würde es gefallen Google Werbung in das Bild zu packen. Das hätte Charme.
Es ist technisch relativ einfach, den Zugriff auf eigene Bilder für fremder Domains zu sperren. Bisher wird das eher selten gemacht. Google gibt jetzt eine Motivation, eine solche Sperre einzurichten.
Es soll ja Websiten geben, deren Betreiber keinen unbegrenzten Traffic gemietet haben. Bei denen fallen Kosten dafür an, dass ihre Bilder auf Googles Seite anzeigen werden.
@41: Es ist eigentlich gar nicht so schwer: die User waren mit der alten Bildersuche auch zufrieden, genau so, wie die Urheber überhaupt nichts dagegen hatten. Wieso muss man nun etwas mit der Brechstange (es wurde vorher niemand informiert oder gefragt) ändern, was einer Seite schadet? Es wird immerhin von zum Teil erheblichen Traffic-Einbrüchen berichtet!
Es ist nun mal tatsächlich so, dass man nicht alles machen _muss_ was technisch möglich ist. Rein technisch gesehen, könnte Google noch viel mehr Features realisieren, das den Urhebern schadet.
Die Ideologie, die Google und andere „Silicon-Valley-Konzerne“ antreibt, wird hier beschrieben:
http://www.newstatesman.com/sci-tech/internet/2012/12/jeff-jarvis-clay-shirky-jay-rosen-invasion-cyber-hustlers
@Andreas Roedl
„Google wäre unbesiegbar“
Googles Geschäftsmodell ist auch von Smartphones und Tablets bedroht. Wenn nicht mehr über den Browser gesucht wird, sondern über „Apps“, dann sieht man die Werbung bei Google nicht mehr.
Ich finde die neue Suche prinzipell Klasse, wenn ich wirklich immer nur nach Bildern suche.
Ich bin aber häufig gerade wenn ich Infos für Refarate oder Vorträge gesucht habe häufig über die Bildersuche gegangen, da ich fest gestellt habe wenn ne Folie schon gut aussieht ist häufig auch der Inhalt der Seiten gut.
Jetzt muss man aber immer doppelt klicken um überhaupt auf der Seie zulanden.
Es dürfte doch überhaupt kein Problem sein das so ein zu richten das man zwar immer auf die Seiten kommt aber trozdem noch mit den Pfeiltasten zur nächsten springen kann.
Nur mal so als Gedankenexperiment:
Was wäre denn, wenn die Bilder von der Googlesuche aus in einem eigenen (neuen) Browserfenster/tab aufgerufen würden? Dann ständen die Bilder auch „alleine“, jedoch unter der Adresse des Anbieters. Das wären schlich Deep-Links.
Wäre das ebenso „verwerflich“?
Das mag jetzt möglicherweise etwas netzfremd klingen, aber mal ganz ehrlich – wie nutzt ihr die Bildersuche? Wenn ich ein Bild suche, dann geht es mir um das Bild (zu welchem Zweck auch immer). Hat sich jemand in der „alten“ Suche nach auffinden eines Bildes wirklich den Text und die Seite um das drumherum angesehen? Ich nicht. ;-)
@Andreas Roedl
Natürlich muss _man_ nicht alles machen, was technisch möglich ist. Nur ist das ein anderes Thema. Es geht hier darum was Google macht, und wie man das Beste daraus macht. Den Versuch Google zu ändern kann man unabhängig davon machen, nur löst das kein gegenwärtiges Problem.
Ich habe mir die neue Suche angesehen, der Blättereffekt auf dem iPad gefällt mir sehr. Ich finde den unten eingeblendetem Link für mich eher klickmotivierend, als die alte Darstellung.
Es wird schwer sein, valide Zahlen über veränderte Zugriffe zu bekommen. Ein „wird von erheblichen Traffic-Einbrüchen berichtet“ ist Hörensagen. Solche Berichte gibt es immer und dauernd bei allen Veränderungen.
Taj, so ist das mit dem Internet: Man kann einfach Bilder über ihre Original-Adresse anzeigen. Wäre das eine Urheberrechtsverletzung, wäre jeder dran. Der Browser kopiert nämlich standardmäßig alle Bilder auf die eigene Festplatte und zeigt sie bei Bedarf erneut von dort an. Man kann dieses Verhalten als Webseitenbetreiber beeinflussen, was z.B. bei Bildern, die sich schnell ändern, gemacht wird, damit kein altes Bild angezeigt wird. Man kann auch verhindern, dass Bilder in die Bildersuche kommen. Man kann aber auch laut schreien und sich Gesetze von politisch Verantwortlichen Stricken lassen, die noch weniger Ahnung haben, als man selbst.
Wenn ich mein Bild nicht in der Bildersuche wünsche, benutze ich die robots.txt, um das zu verhindern. Wenn ich aber in der Suche auftauchen will, kann ich mich beklagen. Das ist ja ungefähr so, als würde ich einen Stapel Fotos aus dem Fenster werfe und jeden bedrohe, der eins aufheben will. Wenn ich das nicht will, schmeiß ich sie nicht aus dem Fenster.
@Stephan
Selbst wenn du den Text auf den Seiten nicht gelesen hast warst du auf der Seite drauf und hast es eventuel auch von der Seite des Urheber herruntergeladen.
Aber eben von der Seite des Urhebers und nicht von Google
[…] nun auch der Journalist Stefan Niggemeier an, der die Optimierung der Bildersuche von Google “dreist und dumm” nannte. Aber warum […]
@Simon
Das ist jetzt ganz genauso.
Google kopiert die Bilder nicht aus seine Server. Jedenfalls bekommt man auch jetzt keine Kopie zur Ansicht.
Finde das gut. Leute die nicht wollen das ihre Bilder in der Suche auftauchen können ja die Bildersuche von Google deaktivieren. Seiten die bei externen refferer die Bilder austauschen straft Google hoffentlich mit heftigster Abwertung der Seite ab. Denn das wäre einfach Kundenunfreundlich. Video kommt vermutlich als nächstes dran. Bing.com macht es ja vor die haben das alles schon seit Ewigkeiten.
@48 Christian Schulz: Ganz Ihrer Meinung!
@Dexter
Ja du lädst sie bei Urheber runter aber gehst nicht auf seine Seite
Ich habe eine kleine US-amerikanische Seite mit vielen Bildern. Seit auf images.google.com die neue Bildersuche gelauncht wurde, sind die Bilderklicks um 90% eingebrochen. (restliche SEO-Visits und andere Metriken konstant).
Egal, wie man das rechtlich sieht: Googles Aussage, daß MEHR Klicks generiert werden, ist für meine (kleine, nicht kommerzielle) Seite absolut nicht zutreffend.
Ich werde tatsächlich die Bilder aus dem Google Bilderindex de-indizieren. Es gibt für mich keinen Grund, Google irgendwelche Bilder zur Verfügung zu stellen, wenn ich dafür noch nicht einmal Visits bekomme…
Über Google kam in letzter Zeit kein qualifizierter Traffic mehr auf meine Website. Einige kamen über Facebook, oder auf andere Art als direkte Empfehlung von Mensch zu Mensch. Wenn ich Google komplett aussperre, dürfte das kaum einen wirtschaftlichen Nachteil für meine Website haben. Bitte nicht verallgemeinern, das kann für andere ganz anders aussehen.
Ich bin auch nicht über Google auf diesen von mir sehr geschätzten Blog gekommen, sondern über Facebook und wenn es nicht Facebook gewesen wäre, hätte auch ein RSS-Feed geholfen.
Für meine eigenen Recherchen kann ich konsequenterweise neben Google auch andere Suchmaschinen verwenden, die es ja zum Glück noch gibt. Es liegt an uns, ob wir die Vielfalt im Netz erhalten oder quasi-Monopole unterstützen.
Statt:
– User sucht Bilder -> Google zeigt ihm veröffentlichte Bilder von Anbietern und verweist auch auf die Quelle, d.h. den „Originalkontext“
soll es also wieder so sein (wie vorher):
– Nutzer sucht Bilder -> Google findet Text mit eingebetteten Bildern
Wo soll beim neuen System der Schaden liegen? Wenn jemand explizit nach Bildern sucht, interessiert er sich nicht für den Text da rundherum. Falls er das doch tut, kann er auch jetzt noch leicht auf den Link zur Webseite des Anbieters klicken.
Der Denkfehler von SN ist, das er meint, es entstände ein irgendwie gearteter Nutzen daraus, dass der Nutzer textliche Inhalte auf den Schirm bekommt, welche er nicht sehen will. (Bzw. ein Schaden, wenn die ungewünschten textlichen Inhalte nicht zu sehen sind)
Also: Es wird im alten System ein Seitenabruf beim Anbieter erzeugt,der im Grunde _völlig wertlos_ (auch für den Anbieter!) ist, da vom Nutzer ungewollt. Es handelte sich um reine Zeit- und Energieverschwendung.
Im übrigen lässt sich die eingebettete Anzeige von Bildern (so wie es Google wohl macht) von Anbieterseite aus ganz wunderbar steuern.
Den einzigen unterschied das Google meine Bilder einbindet und nicht selbst verlinkt ist, dass ICH auch noch fuer deren Traffic aufkommen muss. Nein danke!
Also entweder bin ich zu doof oder ich weiß auch nicht, bei mir zeigt er die neue Ansicht nicht an, auch wenn ich über die englische Seite gehe. Da hab ich immer den halbtransparenten Layer über der Webseite, in der das Bild angezeigt wird. Hat Google quasi schon auf die Kritik reagiert oder ist das alt? Oder was kommt da? Weil sonst finde ich die Diskussion auch entsprechend aufgeladen.
@58: „Wo soll beim neuen System der Schaden liegen? Wenn jemand explizit nach Bildern sucht, interessiert er sich nicht für den Text da rundherum.“
Man verliert den Anreiz, mal eben auf den Knopf „diesen Rahmen entfernen“ zu drücken. In der bisherigen Bildersuche wurde mit einem Klick auf das Bild die Website im Hintergrund geladen und das Bild überlagert. Die meisten User haben dann doch noch den Google-Rahmen entfernt um den Kontext (weitere Bilder, Beschreibung, Urheber) zu sehen. Die ganze Handhabung wurde umgedreht, aber das wird ja hier auch im Artikel erwähnt.
Ich finde es übrigens sehr merkwürdig, dass die Bedenken der Urheber mit einer verbalen Handbewegung vom Tisch gewischt werden. Wenn Urheber sagen, das würde ihnen schaden, dann würde ich ihnen auch erst einmal glauben. Es scheint in dieser Zeit „in“ zu sein, Opfer lächerlich zu machen und das Verhalten des Täters zu verharmlosen.
@Heiner Schäfer
„Über Google kam in letzter Zeit kein qualifizierter Traffic mehr auf meine Website.“
Was soll mir das sagen?
Was hat „über Google“ für eine Aussagekraft zur Bildersuche?
Was ist „qualifizierter Traffic“?
Das mit den Traffic kann Dutzende Gründe haben, nur warum sollte es die in D noch nicht veränderte Bildersuche gewesen sein?
Ein echtes Problem mit der alten Bildersuche scheint mir, dass ich das Bild manchmal nicht sehen kann, weil es unter dem „Rand“ versteckt ist. Jedenfalls auf dem iPad.
Übrigens: seit wann wird Deep-Linking von Bildern verteidigt? War man nicht einmal der Meinung, dass es nicht die feine englische Art ist? Dabei spielt es keine Rolle, ob man das Bild nun mit einem oder 20 Links zur Originalseite verziert.
Man stelle sich vor, wie hier die Verharmloser reagieren würden, wäre es nicht Google, sondern irgendein No-Name-Anbieter, der das veranstalten würde. Da Google uns aber (scheinbar) mit kostenlosen Content beglückt, drückt man gerne ein Auge zu.
»Dreist und dumm« sind hier leider auch sehr viele Kommentare!
Und wie verrottet muss man mental sein, um ALLES aus der Perspektive bequemer Benutzung zu behandeln?
Vielleicht sollten mal die kreativen Leute, die das Internet mit INTERESSANTEN Inhalten füllen, einen Boykott starten. Wenn der bequeme Benutzer dann lauter schwarze Seiten sieht, kommt möglicherweise doch der eine oder andere Gedanke hoch.
Ciao!
@Christian Schulz
ich sehe gerade auch, dass ich einen Gedanken übersprungen habe. Es ging mir um die Frage, ob ich Nachteile habe, wenn ich meine Bilder Google nicht mehr zur Verfügung stelle.
Google.de benutzt nach wie vor die alte Bildersuche, vielleicht ja aus gutem Grund.
Es ist klar dass solch eine Funktion Wasser auf die Mühlen der Leistungslügner Keese & Co. darstellt, aber dass man jetzt auch von der „eigenen“ Seite her darauf einprügeln muss… boah ne. Typisch links, irgendwie. Konzentriert euch mal auf den echten Feind :)
@64: „Vielleicht sollten mal die kreativen Leute, die das Internet mit INTERESSANTEN Inhalten füllen, einen Boykott starten. Wenn der bequeme Benutzer dann lauter schwarze Seiten sieht, kommt möglicherweise doch der eine oder andere Gedanke hoch.“
Du weisst bestimmt schon, was dann passieren wird. Google wird Tafeln einblenden, auf denen suggeriert wird, die bösen Urheber würden ihren Content sperren. Im Falle von Fotos könnten sie es wie bei YouTube machen und einblenden, dass die „VG Bild-Kunst nicht die Rechte eingeräumt hat“ – muss ja nicht den Tatsachen entsprechen. Man kann sich gewiss sein, dass eine Kampagne gestartet wird, die nicht Google, sondern die Urheber schlecht dastehen lässt.
So weit sind wir schon.
@61: Es ist aber gleichzeitig auch in, dass die Urheber wegen irgendwelcher völlig banalen Lappalien herumweinen. Siehe LSR.
Du solltest auch nicht vergessen, dass es sich hier um eine Kampagne von ganz bestimmten Leuten handelt und dass sich extrem viele Urheber bei dem Thema entweder zurückhalten oder dass es ihnen schlicht und einfach egal ist, weil sie mit den Bildern eh kein Geld verdienen. Hier agiert – ja wer agiert da eigentlich? Die verlinkte Iniative „Verteidige Dein Bild – Initiative gegen die neue Google Bildersuche“gibt genau eine Person als Initiator an. Und das war’s. Ich weiß noch nicht mal, wer dahinter steckt – kann aber sagen, dass mir das als mit in der Bildersuche gelistetem Urheber vollkommen wumpe ist.
@Heiner Schäfer
Ah, dann verstehe ich! :-)
Aber wie sollte Dir ein Nachteil entstehen? Der wird hier doch eher darin gesehen, dass Google nicht mehr dem Deal „Content gegen Traffic“ folgt.
@66: „boah ne. Typisch links, irgendwie. Konzentriert euch mal auf den echten Feind :)“
Wer wäre denn der echte Feind? Etwa Urheber, Verlage, Labels?
Hier handelt es sich zwar um eine andere Werkart (Musik), aber man kann all das hier ohne grosse Probleme auf Bilder und Texte übertragen:
http://thetrichordist.com/2012/04/15/meet-the-new-boss-worse-than-the-old-boss-full-post/
Ich glaube manchmal, dass einige Menschen mal ihre Feindbilder von vor zehn Jahren „updaten“ sollten…
Ohne aktiviertes Javascript (z. B. per NoScript) hat die Bildersuche auch bisher schon immer direkt auf die Bilder verlinkt statt auf die Seite, in die sie eingebunden sind. War für mich immer ein guter Grund, Google während der Bildersuche kein Javascript zu erlauben.
@Andreas Roedl #63:
„Täter“, „Opfer“ – ojemine!
Es wäre ja nicht mal illegal, wenn Google DeepLinks auf die Bilder verwendet. Im Gegenteil, illegal wäre es, eigene Kopien anzulegen.
Was den Traffik angeht:
Die neue Sucher verringert(!) den Traffik auf Anbieterseite, indem es ungewünschten (und somit unnützen Traffik) vermeidet.
Text und Bild sind zwei getrennte Dinge. Jedes hat eine eigene Adresse (URI).
http://www.stefan-niggemeier.de/blog/wp-content/schmidt_bildersuche_alte.jpg
Es ist erstaunlich, wie schwer es manchen Zeitgenossen fällt, Zusammenhänge neu zu denken.
Vielleicht kann mir mal einer der Jammerer hier erklären, was es für einen Sinn es hat, bei einer Bildersuche Bild-Textmischmasch statt Bilder als Resultat zu bringen.
Es ist einfach nur die Gewohnheit, die das „normal“ erscheinen lässt.
@Dexter
Das wird nun schwer zu verstehen: die meisten Bilder die in Googles Bildersuche auftauchen sind Bilder die in einem Kontext stehen. Das sind Bilder die eben nicht dazu ausgelegt sind dass sie in einer, wie bei google üblich, konfusen Ergebnisliste auftauchen.
Wer nur nach Bildern sucht kann doch auch bei Flickr, Getty, 500px etc. pp. danach suchen.
@72:
„Es wäre ja nicht mal illegal“
Nicht alles, was nicht illegal ist, ist automatisch richtig. Deshalb ja auch Gesetzesinitiativen in diese Richtung.
„Die neue Sucher verringert(!) den Traffik auf Anbieterseite, indem es ungewünschten (und somit unnützen Traffik) vermeidet.“
Das wird die Seitenbetreiber aber freuen, dass der Traffic und gleichzeitig damit auch die Page-Impressions „vermieden“ wird!
„Text und Bild sind zwei getrennte Dinge. Jedes hat eine eigene Adresse“
Danke für die Aufklärung! Wusste ich noch gar nicht…
Aber wieso sollen Autoren nun besser gestellt sein als Fotografen? Wieso denn nicht einfach die kompletten Texte bereits auf den Ergebnisseiten anzeigen? Das würde doch nur Nutzen bringen! Weniger „Traffic“ und somit weniger PIs auf zum Beispiel Verlagsseiten! Erkennst du das Problem? Immer noch nicht?
„Es ist erstaunlich, wie schwer es manchen Zeitgenossen fällt, Zusammenhänge neu zu denken.“
…
Nur mal so ne Frage: wurde da nicht neulich geklagt, weil jemand die Vorschau auf ein Bild bei Facebook „eingebunden“ hat?
Für das Bild bestand nur das Recht dieses auf der Original-Seite anzuzeigen (soweit ich mich daran erinnere).
Jetzt ist es aber doch bei jedem iStock- oder sonstigem gekauften Bild so, dass man dies nur auf der Seite verwenden kann für die auch die Rechte erworben wurden. Wenn dem so ist, ist das aber nicht mehr „innerhalb des gesetzlichen Rahmens“ – jetzt mal ganz davon abgesehen was ich davon halte…
Muss ich jetzt als Seitenbetreiber dafür sorgen, dass das Bild nicht irgendwo sonst erscheint (robots.txt, etc.) oder ist der, der das Bild einbindet dafür verantwortlich?
(für mich ist derjenige für den Schuss verantwortlich, der den Abzug zieht – nicht derjenige, der die Waffe herstellt)
Kann ich auf die Suchergebnisse von Leuten/Firmen verzichten, die nicht geindext werden wollen? Ja. Es bleibt reichlich übrig.
Eventuell hat das sogar eine reinigende Wirkung.
„How much?“ said Arthur.
„None at all,“ said Mr. Prosser.
(D.Adams – HHGG)
Wenn nun auch Kreative wie z.B. Fotografen ihren Lebensunterhalt aus Werbung und Traffic beziehen, dann sind doch die Werke bzw. Bilder/Fotos selbst bloße Makulatur und überflüssige Datenlast.
Gretchenfrage:
Werbevermittler oder Kreativschaffende?
Verdienst via Content oder Traffic?
Und weniger Traffic ist vor allem bei volumenabhänigen Surftarifen sehr wünschenswert.
Es wird bei aller Diskussion gar nicht angedacht, dass es nur ein Schritt ist, den Google auf dem Weg zur Gewinnmaximierung geht. Abgesehen, dass der traffic, also die Kosten beim User bleiben, ist doch das Ziel von Google den User auf den Seiten von Google zu halten und nicht etwa auf Abwege zu bringen und wo anders Umsatz zu generieren.
Der nächste Schritt wird sein, dass die Suchergebnisseite bei der normalen Textsuche nicht verlassen werden muss.
Irgendwann wird der User den Webseitentext, so wie jetzt die Bilder angeboten bekommen und kann dann oben rechts links unten auf Adsensanzeigen klicken. Mann probiert es einfach aus, wie weit man gehen kann. Wenn geklagt wird, dann schaut man mal. Wenn verloren wird – die Portokasse macht es, wenn nicht um so besser. Google ist ein Konzern und alles was dort getan wird hat als Hintergrund die Gewinnmaximierung, nichts anderes zählt, langfristig nur Gewinn.
Auch das LSR betrifft indirekt das Urheberrecht, auch wenn hier mehrfach etwas anderes behauptet wurde. Aber da waren es die bösen Verlage, die die Wahrung ihrer Verwertungsrechte einforderten, jetzt sind es die Künstler und Webseitenbetreiber.
Die Zukunft wird so aussehen, dass jeder kleine Webmaster,der über Google Besucher erhalten will, seinen Wegzoll in Form von Adwordszahlungen abzuliefern hat.
Google überschreitet hier eindeutig eine Grenze. Das „Don’t be evil“ kann man jetzt nicht mehr glauben. Auch wenn ich prinzipiell dem Urheberrecht in der jetzigen Ausprägung kritisch gegenüber stehe, dies hier hat nichts mit fair use, Zitieren oder Verlinken zu tun. Auch nicht mit Suchen und Finden.
Hier werden geschützte Werke eindeutig aus ihrem Rahmen herausgerissen und sich von einem Fremden zu Nutze gemacht. Der Traffic wird von den Seiten der Fotografen und Künstler (oder auch Bildagenturen und Rechteverwerter, oder auch Zeitungen) einfach abgezogen und gestohlen.
Das ist eine überschrittene Grenze. Sollte Google dies tatsächlich so in Deutschland handhaben, wird ein Sturm von Abmahnungen über es hereinbrechen. Wie dämlich.
@79: Korrekt. Ein Urheber darf natürlich entscheiden, in welchem Kontext sein Werk genutzt werden darf.
„Verboten werden können auch indirekte Eingriffe, wenn das Werk in einen Sachzusammenhang gebracht wird, der den berechtigten Interessen des Urhebers zuwiderläuft.“
http://de.wikipedia.org/wiki/Beeintr%C3%A4chtigungsverbot
http://www.boehmanwaltskanzlei.de/urheberrecht-medienrecht/urheberrecht/rechte-des-urhebers/urheberpersoenlichkeitsrechte/646-entstellungsschutz
Aber natürlich werden jetzt wieder die von Google (via Netzaktivisten) Gehirngewaschenen ankommen und behaupten, dass dann doch irgendetwas nicht mit dem Urheberrecht stimmt. Diese Paragraphen müssen doch abgeschafft werden, weil sie das vollkommen freie „Remixen“ behindern würden.
Bis dann die Nazi-Band Songs „remixt“ und sich keiner mehr dagegen wehren kann…
@Gähner:
Sie meinen Google ist „unsere“ Seite? „Meine“ Seite? Wie kommen Sie darauf?
Ich sehe jetzt das Problem nicht. Wenn ich zum Beispiel bei Google nach Stefan Niggemeier suche und „Bilder“klicke, finde ich zum Beispiel ein Titelbild vom Stern, auf dem Karl-Theodor Guttenberg abgebildet ist. Klicke ich darauf bekomme ich ein 8 cm hohes Bild einer DINAA4 Seite mit 300*400 Pixeln. Dazu ein Menü:
– Seite besuchen
– Originalbild zeigen (gemeint ist die verkleinerte Kopie des Stern-Titelbildes bei Niggemeier).
– Bilddetails
Ja, wie soll man denn Bildkataloge anders machen? Oder wollen wir bald auch in Bibliotheken ein Leistungsschutzrecht für Verlage einführen, wenn der Bibliothekar zwei Zeilen aus dem Klappentext übernimmt? Ich finde die neue Suche von Google viel effizienter und schneller. Wer nur Angst hat, dass Nutzer im Internet ein Urheberrecht nicht einhalten wollen, sollte keine Bilder ins Internet stellen. Man kann nur auf die Nutzer vertrauen und sollte nicht weinen, wenn Bilder im Internet maschinell durchsucht und katalogisiert werden.
Früher ist vorbei.
Was ich an der Sache so schlimm finde, ist die trickige Logik, mit der Google immer mehr Inhalte vereinnahmt: Mit dem Argument „Benutzerfreundlichkeit“ scheint Google jede Änderung zu eigenen Gunsten duchdrücken zu können. Denn wie man auch hier in den Kommentaren sieht, halten es viele für „Fortschritts- oder Internetfeindlich“, wenn man Google für dieses dreiste Vorgehen kritisiert.
Ich finde die Diskrepanz zwischen der Argumentation „Google ist ein Unternehmen“ und „Google hat einen Markanteil von über 90 Prozent Suchmarktanteil“ unerträglich. So langsam spürt man, was an einem Monopol eben schlecht ist. „Lichtschalter Ein/Aus“ ist bei einem Monopol eben fast gleichbedeutend mit Versenkung.
Falls es interessiert: ich habe anfang des Jahres bereits befürchtet, dass aus der Suchmaschine eine Findmaschine wird: http://www.tagseoblog.de/google-aus-suchmaschine-wird-findmaschine
Und am Ende wird es wieder irgendein Richter sein, der darüber entscheidet, was die Merkmale einer Suchmaschine sind, und vermutlich wird er keine Ahnung davon haben :-(
@Wolfgang Ksoll: Es geht hier nicht vorrangig darum, ob „Nutzer im Internet ein Urheberrecht nicht einhalten wollen“, sondern dass Google das Urheberrecht nicht einhält.
Und wenn man einen Bildkatalog machen will mit Bildern in voller Größe und Auflösung, muss man sich eben die Rechte besorgen. Wenn man die Rechte nicht hat, kann man eine Bildsuchmaschine machen, die nur kleine Vorschaubilder anzeigt — fürs Original muss man dann zum Rechteinhaber bzw. Urheber.
@2 Jane:
Nein, es ist nicht die GEMA, die das bei YouTube kann, sondern YouTube selbst. Denn wenn YouTube die Wahrheit sagen würde, würde dies dort stehen:
http://www.youtube.com/watch?feature=player_embedded&v=ueTq3OvX1Vk
Und dazu ergänzend:
http://www.wecab.info/740-satirische-stern-bilderstrecke-facht-deutschlandweite-diskussion-uber-urheberrecht-an/
@85/Peter: Der wirkliche Spaß daran: Da der Uploader Hans Hafner Musikkomponist und Gema-Mitglied, müsste YouTube jetzt das Video recht schnell wegen gemapflichtiger Musik sperren. Nur so.
Ich denke zunächst muss man die Beurteilung und den Praktischen mit der neuen Bildersuche und die Sorgen um die Zukunft trennen.
Mit der neuen Bildersuche habe ich noch kein Problem. Ich persönlich bin wahrscheinlich eher zu mehr Klicks auf die Originalseite bereit, weil ich eine bessere Auswahl habe, und solange ich die Beschreibung der Quellseite mit angezeigt bekomme bin ich eher zu einem Klick dorthin geneigt, als bei der alten Suche, die mir oft ineffektiv erscheint.
Wenn ich die Bilder nur als Coverflow, ohne Infos und Link zur Quellseite angeboten bekomme, dann empfinde ich auch eine Grenze überschritten. Die Grenze zu einem eigenen Googledienst.
Konsequent zu Ende gedacht kann Google ein Wikipedia mit fremden Inhalten schaffen. Ein eigenes werbefinanziertes „Sub-Internet“ aus fremden Inhalten. Eine Art Meta-CMS. Das scheint auch perspektivisch beabsichtigt.
Ich glaube aber nicht, dass dies funktionieren wird, da so das Interesse fehlt Inhalte zur Verfügung zu stellen, wenn es nicht durch eine neue Infrastruktur gestützt wird.
Positiv könnte man Google dann zu einer Entwicklung als Contentprovider sehen, der Content kauft, um ihn zu vermarkten. Vermarkten durch Beteiligung an den Einnahmen. Die Anbieter erstellen keine Websites mehr, sondern geben nur noch GoogleDocs frei.
Das klingt nicht unattraktiv, erschiene mir aber grauenvoll, weil es dann ein Einheitsnetz wäre. Überspitzt formuliert: kapitalistisch gemachter Sozialismus.
Für Presseverlage könnte das, ohne Google, selbst gemacht m. E. durchaus ein Weg sein das Paywall-Problem sinnvoll zu lösen.
Insgesamt würde es die Vielfalt und Freiheit des Internet zerstören. Das Internet, wie wir es kennen wäre tot.
Ich bin hin- und hergerissen.
Ich war überrascht, als ich das erste Mal die neue Google-Bildersuche benutzte. Ich war so darauf geeicht, dass ich die Original-Website und den Frame mit dem Bild und den Links präsentiert bekomme, dass ich es ersteinmal blöd fand. Dann aber bemerkte ich, dass ich dadurch wesentlich schneller die Bilder finde, die mich interessieren. Das, was ich mit den Bildern mache, unterscheidet sich natürlich nicht, von der Darstellung innerhalb der Bildersuche. Ich bin mir auch gar nicht sicher, ob das alles legal und/oder fair ist, was ich mit den Bildern so mache. Ich habe aber auch vorher i.d.R. der umgebenden Website keine größere Beachtung geschenkt, deshalb vermisse ich sie jetzt nicht.
Für diejenigen, die mit Ihrer Website kein Geld verdienen müssen oder wollen ist die neue Bildersuche wahrscheinlich besser, weil weniger Verkehr aufkommt, der entweder bezahlt werden muss oder die Bandbreite beschneidet.
Für diejenigen, die mit Ihrer Website über „qualifizierte Werbelinks“ verdienen wollen, d.h. sie bekommen Geld dafür, dass jemand auf einen Werbelink klickt und /oder ein Geschäft tätigt, ändert sich durch die neue Bildersuche wenig. Das wird vorher i.d.R. schon nicht passiert sein.
Für diejenigen, die für das Anzeigen der Werbung auf Ihrer Website verdienen wollen, ändert sich alles grundlegend. Ich persönlich halte diese Art der Werbung für überkommen (nicht nur online), verstehe aber trotzdem den Kummer, den das bereitet.
Ich finde die Art und Weise, wie Google die neue Bildersuche einführt, wirklich saudumm und unfassbar dreist. Da bin ich vollkommen einer Meinung mit Stefan. Das hätte man ankündigen und erklären müssen. Mit der Marktmacht hätte man auch eine Antwort auf die Beschwerden der Werbeanzeiger haben müssen.
Ich glaube aber auch, dass sich „im Internet“ einige Dinge mittelfristig ändern müssen, damit es benutzbar bleibt und ein Mehrwert für die Benutzer generiert wird. Sonst wird es nicht mehr benutzt werden. Es muss auf Fragen Antworten liefern, und nicht Hunderte von Variationen der Frage ohne wirkliche Antwort. Momentan verdienen viele Geld damit, Werbung zu den Hunderten von Variationen der Frage anzuzeigen und man findet vor lauter SEO die Antwort nicht. Ich bin auch gerne bereit, für die Antwort zu bezahlen. Nicht, dass ich noch falsch verstanden werde.
Merkwürdig. Zuletzt wurde die Keesesche Argumentation gegen htaccess und gegen Snippets hier immer wieder kritisiert – zu recht, ganz klar.
Die Sachlage hier ist aber doch die gleiche: man kann die Bildersuche per htaccess aussperren, und in den allermeisten Fällen ist ein Bild auf einer Webseite auch nur Teil des Ganzen, also vergleichbar mit einem Textauszug. Wer jetzt so argumentiert wie Keese, macht sich mit dem nächsten ‚Lügen für…’Text etwas unglaubwürdig.
@Andreas Roedl #80:
Hätte deine Rechtsauffassung bestand, so wären auch die angezeigten Ergebnisse der Volltextsuche bei Google illegal. Sind sie aber nicht.
Und wer von „Opfern“ spricht, sollte auch anzeigen können, dass der vermeintliche „Täter“ gegen geltendes Recht verstößt. Alles andere ist Verleumdung und u.U. selbst strafbar.
Ich habe auch meine Probleme damit, dass einzelne (neuartige) Konzerne (Google, Facebook …) die Freiheit des Netzes unterlaufen, indem sie essentielle Dienste zur Nutzbarnmachung des Medium bei sich konzentrieren. Ich finde das gar furchtbar!
Aber man kann diesem Problemen nicht so begegnen, wie das die alten Konzerne – und in diesem Fall auch Herr Niggemeier – sich vorstellen. Es ist für das Gesamtsystem – die menschliche Gesellschaft – sehr suboptimal.
„Das Netz“ ist ein Medium. Ein Vehikel. Ein Transportwerkzeug für Informationen. In der Regel ist damit der Transport der Information billiger als die Erstellung der Informationen selbst. Früher war das andersherum. Und aus diesem (misslichen!) Umstand heraus entwickelten sich historisch Geschäftsgewohnheiten, die die etablierten Inhalteerzeuger (oder sagen wir einfach „Medienkonzerne“) ungerne aufgeben wollen. Verständlich. Aus deren Sicht. Nur ist das mittlerweile sehr kontraproduktiv.
Es gibt da übrigens auch wieder so ein widerliches Neusprech. „Informationsanbieter“. Ich wüsste wirklich nicht, wo das Angebot zu finden ist, wenn jemand Inhalte in ein allg. verfügbares Medium einspeist:
http://de.wikipedia.org/wiki/Angebot_%28Recht%29
Aber es soll wohl vermitteln, dass da von einem (fiktiven) Annehmenden auch eine konkrete Gegenleistung erbracht werden muss …
Was die „Rechteinhaber“ wollen ist in etwa so, als würde jemand auf einem öffentlichen Platz stehen stehen, die neuesten Nachrichten & Geschichten herausbrüllen (meinetwegen in Sponsorenkleidung an einem Werbestand) und erwarten, dass er hernach noch das Recht hat zu bestimmen, wer die Informationen an wen weitererzählen darf.
Solche Vorstellungen sind doch albern, wenn nicht gar blödsinnig oder von immanenter Macht- und Verwertungsgier geprägt. Und m. E. auch widernatürlich und somit langfristig undurchsetzbar.
Nochwas:
Text soll also zwangsläufig zu den Ergebnissen der Bildersuche erscheinen? Wegen dem Kontext und so. Hmm. Demnächst fordern „Informationsanbieter“ dann, dass bei der Google-Volltextsuche gefälligst auch die Bilder von den Webseiten mit erscheinen sollen. Kontext und so …
@Stefan Niggemeier #84:
Der Vergleich hinkt. Google druckt keinen eigenen Katalog mit den Kopien der „Originale“. Google bietet einen Katalog mit den Adressen der „Originale“, die das Sichtungsgerät des Nutzers auch gleich anzeigt.
Also nochmal: Wie wäre es, wenn sich die Bilder ohne Webseitenkontext aus der Googlesuche heraus in einem eigenen Browserfenster/-Tab öffnen würden. Mit der URL des „Anbieters“ in der Adresszeile. Wäre das auch verwerflich?
Google ist kein öffentlicher Wohltätigkeitsverein. Wer seinen Webserver Bilder an jedermann ausliefern lässt wirkt als Überraschter einfach nur dämlich und einfältig. Wer davon so empört ist kann seinen Webserver ja an Leute mit Bildersuche-Referer Werbung ausliefern lassen. Mit ein bisschen Bildung wie das mit dem Internetz funktioniert macht man sich dann auch schwerer zum Affen.
„Text soll also zwangsläufig zu den Ergebnissen der Bildersuche erscheinen? Wegen dem Kontext und so.“
Ja – beispielsweise nach IPTC/NAA-Standard ins Bild eingebettete Informationen zum rechtlichen Status des Bildes. Die werden zwar teilweise eingelesen, aber derzeit weder direkt am Bild eingeblendet noch können sie via Suchmaschine gefunden werden.
(„Witzigerweise“ entfernen diverse Plattformen des Social Web – auch Facebook und Google+/Picasa – sämtliche eingebetteten Informationen aus Bildern. Automatisch, beim Download, fertig.)
Nachtrag (leider funktioniert kommentieren mit dem Link aus irgendwelchen Gründen nicht): „Hat Google uns bei der Bildersuche belogen?“ fragt das Blog von seo united – und liefert die Screenshots der Visitor-Statistik von pixabay mit. Signifikanter Knick in den Kurven zeitgleich mit dem Start der Google Bildersuche.
@Stefan Weierstraß: Es ist eben nicht wie bei der Keeseschen Argumentation pro Leistungsschutzrecht. Erstens geht es hier um Originale, also nicht um Snippets oder Vorschaubilder. Und zweitens gibt es hier nur An/Aus und nicht — wie bei Text — An/Aus/ohne Snippet. In den zwei zentralen Punkten sind die neue Bildersuche und die normale Suche nicht vergleichbar.
Die beiden Vorwürfe von Keese, die bei der Textsuche falsch sind und ins Leere laufen, treffen hier voll zu.
@95 Sobald ein Bild nicht nur ‚mickriges Beiwerk‘ zu einem Text ist, sondern als eigenständiges Werk gemeint ist, wird es doch in den meisten Fällen in zwei Auflösungen existieren: der hohen Originalauflösung und einer verkleinerten Version, die in der Webseite eingebunden sein wird – z.B. als Vorschaubild.
Wenn jetzt per htaccess der Zugriff nur auf die kleine Version gestattet wird, dann entspricht das eben doch der Erlaubnis eines Snippets. Wenn man Snippets nicht erlaubt, bedeutet das im Kontext einer reinen Bildersuche, eben nicht auffindbar zu sein – also Aussperrung per htaccess.
@Stefan Weierstraß: Noch einmal, es geht hier darum, dass sich Google das Recht herausnimmt, urheberrechtlich geschützte Werke im Original anzeigen. Nach der gleichen Logik könnte Google auch meine Artikel auf dieser Seite im Volltext bei sich anzeigen, wenn jemand nach entsprechenden Begriffen sucht. Das wär bestimmt sogar superpraktisch für die Nutzer!
Müsste ich das hinnehmen? Dürfte ich das nicht dreist finden?
@96: Ein Bild kann man als komplettes Werk bezeichnen, ziemlich unabhängig davon, wie hoch die Auflösung ist. Schau dir die Bilder in diesem Blog-Post an. Benötigst du eine grössere Auflösung oder reicht dir das, was du siehst? Würde nicht sogar eine geringere Auflösung vollkommen ausreichen?
Man kann Bilder und Texte nicht so einfach über einen Kamm scheren. Wenn du schon vergleichen willst, dann nimm einen Text und lese ihn dir in einem kleineren Font durch. Du wirst sehen: wie der Text dargestellt wird, ist dabei unerheblich, denn es geht um den Inhalt. So geht es beim Bild um den Inhalt und nicht seine Darstellungsform.
Was wir aber in Zukunft sehen werden, sind eingebettete Wasserzeichen, die den Google-Image-Search-Besucher dazu leider zwingen werden, die eigentliche Site zu besuchen. Daran arbeiten derzeit einige Webmaster.
Es gibt eben Entwicklungen, die nur auf dem allerersten Blick als Segen erscheinen, aber ungewünschte Nebenwirkungen mit sich bringen. Diese sind diese Wasserzeichen und das Aussperren von Google Images. Wozu sollte man in Zukunft noch den Google Image Bot zulassen, wenn der Traffic-Einbruch so deutlich ist, wie im folgenden Bild zu sehen?
http://i.imgur.com/yv6iBCp.png
(Aus dem von Heike Rost erwähnten Blog, der sich hier nicht verlinken lässt)
Google lügt, wenn sie behaupten, dass die neue Bilder-Suche sogar _mehr_ Click-Throughs bewirkt. Traffic-Statistiken lügen nicht!
Hier ist der gewünschte Link: http://www.seo-united.de/blog/google/hat-google-uns-bei-der-bildersuche-angelogen.htm
(Weiß gar nicht, warum das nicht gehen sollte.)
@Stefan Niggemeier
„@Stefan Weierstraß: Noch einmal, es geht hier darum, dass sich Google das Recht herausnimmt, urheberrechtlich geschützte Werke im Original anzeigen. “
Das macht mein Windows auch. Und es speichert im Cache auf der Platte auch noch Bilder. In großen Organisationen speichern Proxies auch Bilder, um den Netzwerk-Traffic niedriger zu machen. Und in den 1990er Jahren wollte die Polizei aus diesem Zwischenspeichern im Cache ein Besitzen machen, dass bei Kinderpornografie nach §184a StGB mit Gefängnisstrafe bestraft werden sollte. Mittlerweile konnten wir die Polizei überzeugen, trotz Frau von der Leyen und Herrn zu Guttenberg, besser den Dreck auf den Servern zu löschen als mit abstrusen Konstrukten heiße Luft zu machen.
Zu Guttenberg noch einmal: Wenn ich bei Google Bilder von Stefan Niggemeier suche, finde ich ein Stern-Titelblatt mit Guttenberg. Aber eben nicht in Originalgröße, sondern als Verkleinerung. Vielleicht ist es ein Zitat. Google schreibt ordentlich hin, wo sie das Bild gefunden haben, wie groß es ist, wo die Quelle liegt, wenn man das Original“ sehen will, das in diesem Fall nicht das Original ist.
Ich halte die ökonomisch-urheberrechtliche Interpretation dieses technischen Vorganges von Google übertrieben. Genauso so, wie eben Keese das LSR begründet, dass die Leute eben nicht mehr zur Quelle gehen, wenn sie bei Google Überschrift und Schnippsel sehen.
Wenn wir so übertrieben weiter argumentieren, dann werden bald in Kiosken keine Zeitungen mehr aus liegen dürfen, weil die Vorbeigehenden ja kostenlos die Titelseiten sehen und lesen dürfen. Bei Stefan Niggemeier kann ich übrigens nicht zum Stern durch klicken und mir das Original online kaufen.
[…] für die Urheber der Bilder stellt dies einen massiven Einschnitt dar. Etliche Fotografen und Blogger äußern sich deshalb auch ablehnend zur neuen Bildersuche von Google und bezweifeln, […]
@100 Wolfgang Ksoll:
Zitat: „Wenn wir so übertrieben weiter argumentieren, dann werden bald in Kiosken keine Zeitungen mehr aus liegen dürfen, weil die Vorbeigehenden ja kostenlos die Titelseiten sehen und lesen dürfen. Bei Stefan Niggemeier kann ich übrigens nicht zum Stern durch klicken und mir das Original online kaufen.“
Deeskalation wäre sehr gut! Sie ist aber auch schwierig! Weil die ganzen Spezialisten eine Existenzberechtigung brauchen. Kreative sind gefragt, die den Karren in eine neue Richtung aus dem Dreck ziehen. Bis dahin dauert es nicht mehr lange, da bin ich mir ziemlich sicher!
„Bislang führte ein Klick auf eines der kleinen Vorschaubilder in der Übersicht immer auf die Seite, auf der das Original zu sehen war.“
Ein „Original“ habe ich auf diese Weise noch nie gefunden. Was ich auf FAZ und Co. regelmäßig finde, sind Bilder in runterkomprimierter Drecksqualität.
“ Jetzt führt er zu einer Anzeige des Bildes innerhalb der Suche. Der Nutzer muss also die Ergebnisseite gar nicht mehr verlassen, um sich die Bilder in voller Größe anzeigen zu lassen.“
Ist doch prima. So bekommen nur die Bilder und damit die Webseiten meine volle Aufmerksamkeit, die mir eine vernünftige Qualität anbieten, im Idealfall lande ich direkt beim Fotografen, der mir Originalqualität verkauft.
Die Webseite http://verteidige-dein-bild.de/ erinnert mich in ihrer Dummheit und Dreistigkeit an den offenen Brief der 51 Tatort-Drehbuchautoren.
Webseiten, denen nach der Einführung der Google-Bildersuche die Besucherzahlen einbrechen, scheinen wohl mit qualitativ ansprechendem Inhalt nicht viel am Hut zu haben.
Wenn ich an Artikeln über „Eric Schmidt“ interessiert bin, nutze ich jedenfalls nicht die Bildersuche, sondern die normale Google-Suche. Welche Webseite das qualitativ geilste Foto zum Artikel anbietet, ist mir in dem Fall eher wurscht.
@103:
„[…] erinnert mich in ihrer Dummheit und Dreistigkeit an den offenen Brief der 51 Tatort-Drehbuchautoren.“
Was war am offenen Brief denn „dreist“? Was war daran „dumm“?
Du scheinst ein ganz grundlegendes Problem mit Urhebern (Künstler, Kulturschaffende und Kreative) zu haben.
„Was war am offenen Brief denn »dreist«? Was war daran »dumm«?“
Dumm: Die Annahme, daß es einen Schwarzmarkt für Tatort-Drehbücher gäbe, in dem sich Raubmordvergewaltigungskopierer verlustieren.
Dreist: Sich von der ARD und damit den Gebührenzahlern einen Haufen Geld für Tatort-Drehbücher in den Arsch blasen zu lassen, ohne daß diese Werke dadurch in den Besitz der Allgemeinheit übergehen.
Ansonsten: http://ccc.de/updates/2012/drehbuchautoren
„Du scheinst ein ganz grundlegendes Problem mit Urhebern (Künstler, Kulturschaffende und Kreative) zu haben.“
Nein. Probleme habe ich nur mit Urhebern, die den Hals nicht voll genug bekommen, die glauben, daß ihnen die Gesellschaft irgendetwas schuldet, weil sie ihr Hobby zum Beruf gemacht haben.
Du hast also nichts verstanden. Verstehe.
völlig richtig, damit schadet google seiner position und den anderen gegnern eines leistungsschutzrechts gewaltig
@98: Das mit der Auflösung hängt doch davon ab, was das Ziel meiner Suche ist. Gleiches Beispiel wie oben schon einmal: wenn ich nur ein Gesicht zu einem Namen suche, dann reicht mir ein niedrig auflösendes Bild, ja. Dann reichte mir aber auch schon das vorherige Suchergebnis. Vergleichbar ist das mit den DPA-Meldungen bei Google News. Da kriegen die Verleger langfristig kein Geld mehr für, nicht weil Google so böse ist sondern weil es sich um Massenware handelt.
Auf der verlinkten ‚Verteidige dein Bild‘-Webseite ist im Gegensatz dazu von ‚hochauflösendem, honorarfreiem Bildmaterial‘ die Rede.
@Jeff:
Dieses Beispiel mit dem Wikipedia-Inhalten bei Google auf der „verteidige-dein-bild.de“-Seite ist ja seltendämlich.
Ich glaube kaum, dass die Wikipedia was dagegen hätte, wenn Google einfach gleich den Artikeltext zeigen würde. Das würde der Wikipedia einen Haufen Geld, (Traffik und Rechenleistung) sparen.
Diese Wir-wollen-Auf-Teufel-Komm-Raus-PageViews-Jammerlappen haben irgendwie nicht kapiert, dass ein Pageview nur dann auch kapitalisierbar ist, wenn die dort gefundene Information auch im Interesse des Besuchers ist. Kein Interesse = Kein Klick-Through auf Werbeflächen oder gar den einen POS = Kein Geld (dafür Kosten).
Und wenn jemand im Netz ein Bild sucht, dann hat er kein Interesse an Text. Ist doch eigentlich ganz einfach und nachvollziehbar.
Es ist festzustellen, dass Google die Welt der digitalen Information völlig anders „sieht“, als die etablierten Informationsdealer des vorigen Jahrhunderts.
Wobei mir die Sichtweise Googles (und zwar nur die Sichtweise) sinnvoller und angemessener erscheint.
BTW: Es ist technisch kein großes Problem, die eigenen heiligen Inhalte nur den Clientanfragen auszuliefern, denen man geneigt ist. So einfach funktioniert die Client-Server-Infrastruktur des Netzes nunmal. Kein Client (z.B. Google) kann von einem Server (z.B. Verlag) Inhaltsherausgabe erzwingen.
Selbst wenn man Google die Bildchen schon zur Indexierung überlassen hat, könnte man sogar (quasi im Nachgang) leicht verhindern, dass diese Bilder auf der Bildersuch-Ergebnisseite erscheinen. Oder die Bildchen mit Werbung ersetzen.
Ich versteh das ganze Rumgeheule „die klauen(!) unsere Inhalte“ wirklich nicht.
@all:
Ihr wisst schon, daß die „neue“ Bildsuche lediglich etwas grössere Vorschau-Bilder anzeigt(i.d.R. jenseits der Originalgrösse) ?!
@110:
„Ihr wisst schon, daß die »neue« Bildsuche lediglich etwas grössere Vorschau-Bilder anzeigt(i.d.R. jenseits der Originalgrösse) ?!“
Du weisst schon, dass es vollkommen egal ist?
Die Google-User sind glücklicher als zuvor, die Website-Betreiber sind sehr viel unglicher als zuvor. Mehr muss man über dieses Thema nicht wissen. Der Content wird auf Google „konsumiert“ und nicht mehr auf der Site derer, die den Content anbieten.
Das hier noch nicht gesehen? http://i.imgur.com/yv6iBCp.png
„Das hier noch nicht gesehen? http://i.imgur.com/yv6iBCp.png“
Das hier noch nicht gesehen? http://pixabay.com/de/service/terms/
„Alle zum Download bereitgestellten Bilder auf Pixabay sind gemeinfrei (Public Domain) entsprechend der Verzichtserklärung Creative Commons CC0. Soweit gesetzlich möglich, wurden von den Bildautoren sämtliche Urheber- und verwandten Rechte an den Bildern abgetreten. Die Bilder unterliegen damit keinem Kopierrecht und können – verändert oder unverändert – kostenlos für kommerzielle und nicht kommerzielle Anwendungen in digitaler oder gedruckter Form ohne Bildnachweis verwendet werden. Dennoch wissen wir einen freiwilligen Link auf die Quelle Pixabay sehr zu schätzen.“
@rgroth: Ich nehme an, Sie meinen „jenseits“ im Sinne von „diesseits“, jedenfalls: Benutzen Sie mal die neue Bildersuche auf einem großen Monitor, ziehen das Browserfenster auf und staunen Sie.
@Jeff: Sie haben nichts verstanden. Pixabay ist hier nur ein Beispiel, an dem sich der Einbruch der Besucherzahlen zeigen lässt, der der Google-Darstellung deutlich widerspricht. Dass Pixabay mit seinen freien Inhalten ein juristischer Sonderfall ist, ändert ja nichts an dieser Tatsache.
@jeff (112): „Alle zum Download bereitgestellten Bilder auf Pixabay sind gemeinfrei (Public Domain)“
Ah. Deswegen bezeugen die Statistiken nicht, dass die Umstellung auf die neue Bildersuche negative Auswirkungen auf den Traffic einer Website haben.
*facepalm*
@Dexter – Kommentar 109
Also meiner Meinung nach hätte Wikipedia durchaus etwas dagegen, wenn google die Inhalte einfach so ohne Hinweis auf die Website einbinden würde. Glauben Sie denn, die Wikipedia-Foundation macht ihre Spendenaufrufe auf der eigenen Seite nur aus Jux und Dollerei.
@chico
Wie kommen sie darauf? Meinen sie die WP hätte etwas gegen die Umsetzung ihrer ureigenen Lizenzbedingungen? (Google nennt übrigens die Quelle)
WP bräuchte weniger Spenden, wäre der Traffik geringer. (WP wird übrigens auch zum Download angeboten)
WP hat explizit das Ziel Informationen verfügbar zu machen, nicht diese zu kapitalisieren. Noch nicht mal diesen einfachen Fakt haben die superschlauen Initiatoren von verteidige-dein-bild verstehen können.
@Dexter
Wenn ich jetzt nicht mit einer absoluten Lese- und Verständnisschwäche geschlagen bin, so scheint es mir doch im Fall der Bildersuche mit Großbild (Großbild gleich viele KB), dass der Traffic bei dem Veröffentlicher bleibt, und Google nur von dem Einbinden der fremden Inhalte ohne eigenen Speicher profitiert.
@114
„Finde und teile brilliante Public Domain Bilder“
Dank Google kann der Dienst diesem Anspruch jetzt noch wesentlich effizienter gerecht werden. Ist es nicht schön?
Die neue Suche vermeidet Traffik, indem (auch für den Besucher) unnützer Traffik (=ungesuchter Text) vom Anbieter nicht mehr übertragen werden muss.
Das angebotene und gesuchte Bild wird in beiden Versionen übertragen.
@jeff, @dexter:
Sagt mal. Seid ihr so oder tut ihr nur so? Wollt ihr nicht das Problem verstehen? So schwer gehirngewaschen und im Rausch des kostenlosen Contents kann man doch gar nicht sein.
Es ist vollkommen egal, ob Pixabay nun PD-Bilder anbietet oder nicht! Abgesehen davon finanziert sich Pixabay durch die eingeblendete Werbung, die ihr wahrscheinlich wegen euren Ad-Blockern nicht sehen könnt! Google zeigt nun die Bilder in hoher Auflösung an und man muss nicht mehr auf die eigentliche Site durchklicken um bedient zu werden! Die Besucherzahlen sind um 70 Prozent gesunken, aber die Bilder werden weiterhin auf Google „konsumiert“.
Pixabay entgehen somit die Einnahmen durch die Display-Werbung. Gerade für solche Sites, die Bilder anbieten und sich durch Werbung finanzieren ist die Umstellung tödlich! Man kann dann die Bilder direkt auf Google betrachten und herunterladen.
Ich weiss nicht, wie ich es sonst noch erklären soll.
@115:
„Ah. Deswegen bezeugen die Statistiken nicht, dass die Umstellung auf die neue Bildersuche negative Auswirkungen auf den Traffic einer Website haben.“
Ob einbrechende Besucherzahlen positiv oder negativ zu werten sind, kann man aus diesen Statistiken nicht ablesen, das hängt vom Geschäftsmodell und/oder den Erwartungen/Kosten der jeweiligen Webseite ab.
Die Lizenzbedingungen von pixabay.com jedenfalls belegen, daß pixabay.com so ziemlich die allerletzte Webseite ist, die sich darüber beklagen darf, daß ein kommerzielles Unternehmen wie Google die Bilder aus dem Bilderfriedhof abgreift und so präsentiert, daß sie gefunden werden.
@104:
„@Jeff: Sie haben nichts verstanden.“
Sie haben die Weisheit mit Löffeln gefressen. Genau wie der Rest Ihrer Pappenheimer. Weiß ich doch.
@Dexter – Kommentar 120
Na mit so einem Insider – ein paar Bytes Text gegenüber dem Traffic, den Bilder verursachen m( – kann ich einfach nicht mithalten und werde mich dazu auch nicht mehr äußern.
@andreas:
Worin besteht also die Leistung von Pixbay, die der Besucher dort (über ihm untergejubelte Werbung?) vergüten soll? In der Speicherung, Zusammenstellung und der Auffindbarmachung der Bilder.
Das Problem: Google kann zumindest den letzten Punkt besser realisieren und tut das auch. Warum auch nicht? Woraus könnte Pixbay den Anspruch ableiten, das Google das unterlassen bzw. auf eine ganz spezielle Art tun sollte?
Was kann Pixbay tun?
– Google den Zugriff schlicht verbieten
oder
– Zwei Versionen der Bilder in auf der Webseite bereitstellen. Google nur den Zugriff auf die wassergezeichneten Versionen gewähren. Menschlichen Besuchern auf diesen Targetpages den Download der Originalversion aus dem anderen Bereich erlauben
@chico:
Es sind nicht nur die übertragenen Bytes, es ist vor allem die Anzahl der Requests pro Page (bei weitem nicht nur eine-eher, was 2 oder 3-stelliges), die Serverlast generiert.
Und erklären sie mir bitte den Nutzen für den Anbieter, wenn dieser genötigt wird, für den Suchenden uninteressanten Content auszuliefern.
Sollte nun ein Anbieter kein Interesse daran haben, dass seine Bilder von Suchenden ausserhalb des Webseitenkontext gefunden werden können, dann kann er doch einfach… (na sie wissen schon)
Sorry für die Ortho. Tablet nix gut schreiben.
Hallo Herr Niggemeier, ich sehe es aus der Sicht des Fotografen, der selber zahlreiche Bilder (auch preisgekrönte), in Galerien veröffentlicht hat und finde die Umsetzung der Funktion genial. Über die Suche „ähnlich Bilder“ kann ich z.B. nahezu alle meine referenzierten Fotos finden und sehe sofort ,ob das Copyright (z.B. Nennung des Autors) gewahrt ist . Die Diskussion erinnert mich an die Leute, die bei Streetview ihr Haus verpixeln lassen. Ist das typisch Deutsch …?
@ Stefan Niggemeier
Eine Bildersuche, also ein Programm, kann nicht dumm und dreist sein. Die Programmierer schon. Aber ich kann den Ärger bei Ihnen, der aus dem Titel hervorgeht, nachvollziehen: Sie haben sich in Sachen Leistungsschutzrecht dermaßen ins Zeug gelegt, um jetzt, inmitten des noch laufenden Kampfes, vom Unternehmen Google selbst einen Tritt ins Kreuz zu bekommen.
Das wird hoffentlich ihre Augen öffnen und sicherlich werden Sie jetzt empfänglicher für die noch folgenden Schritte dieses Monopolisten, dessen erklärtes Ziel (der Link wurde in den Kommentaren schon gepostet) es ist, alle wesentlichen Inhalte des weltweiten Internet auf seinen Seiten zu vereinnahmen. Nach der Bildersuche kommen die Kurz-Videos, gefolgt von gänzlichen TV-Inhalten und ergänzt mit sämtlichen Inhalten aus der Print-Branche.
Natürlich wird es mit allen, die sich im ausreichenden Maße standhaft wehren, entsprechende Vereinbarungen finanzieller Natur geben. Die Spielregeln allerdings bestimmt Google. Und Sie werden erkennen, dass, den Euroraum betreffend, in Frankreich vor kurzem der erste Schritt hinsichtlich der Printinhalte vollzogen worden ist. Herr Keese freut sich im Moment zwar, weil er denkt, dass Google eingeknickt ist. Aber auch nur weil er nicht ahnt, dass sich die franz. Printbranche gerade an Google verkauft hat. Nicht mit den lächerlichen 60 Millionen Euro, nein. Sondern mit der weitergehenden Vereinbarung, Printerzeugnisse zukünftig im Internet zu vermarkten. Nichts anderes nämlich wurde vereinbart, auch wenn es anders kommuniziert wird.
Die ganzen Diskussionen um das Thema LSR und jetzt die Bildersuche sind sehr anstrengend, weil immer die gleichen Argumente kommen, die da u.a. lauten, dass man Google doch aussperren könnte. Klar kann man das, was noch nicht mal Herr Keese bestreitet. Aber es wäre aufgrund des Monopol, das Google mit einem Marktanteil von weit über 90 Prozent unbestritten besitzt, Selbstmord des eigenen Geschäfts im Internet.
Auch Sie, Herr Niggemeier, liefern relevante Inhalte für das Internet. Und auch diese Inhalte werden mittelfristig auf den Seiten von Google abrufbar sein, ohne dass Sie dafür auch nur einen User auf Ihren Seiten vorfinden müssen.
Öffnen Sie Ihren Blick auf die strategischen Wachstumsmöglichkeiten eines Unternehmens wie Google, und Sie werden das selber erkennen.
@ Lothar Reeg
Ähnliche Bilder können Sie mit Google schon seit Jahren suchen, wenn Sie das wollen. Dazu bedarf es keine Contentübernahme durch Google.
Wenn denn dann also die Clickzahlen einer Seite aufgrund der neuen Bildersuche zurückgehen, sieht man dann nicht eventuell den „echten“ Traffic zur Seite?
Bsp:
Ich suche nach einem Bild mit einer Banane.
Alte Suche:
Tausende Bananenbilder zu sehen, ich klicke eins an, Bild öffnet sich auf der entsprechenden Webseite, Rechtsklick, Download, Webseite schließen.
Die Seite an sich ist mir doch relativ egal, oder?
Neue Suche:
Tausende Bilder, ich klicke eins an, Bild öffnet sich direkt, Rechtsklick, Download, Ende.
Aus Sicht des Users der gleiche Vorgang mit gleichem Effekt: Die „hinter“ dem Bild liegende Webseite ist mir egal.
Also wäre bei der alten Suche ein ungerechtfertigter Click gezählt worden.
Und jetzt ganz anders: Wenn Bilder mein Geschäft wären, dann packe ich die doch nicht hochaufgelöst, ohne Wasserzeichen und pipapo, fertig zum Download auf meine Seite, oder?
Ich sehe immer noch die alte Form der Bildersuche. Kann man da etwas verkehrt machen? Browser ist Chrome (mit Opera auch getestet).
In Deutschland ist die neue Suche noch nicht aktiv.
Unten rechtsvauf google.com klicken, dann klappt es.
Ich habe es ja oben schon gesagt, Google istbauf dem Weg zum Contentprovider.
@128:
„Die ganzen Diskussionen um das Thema LSR und jetzt die Bildersuche sind sehr anstrengend, weil immer die gleichen Argumente kommen, die da u.a. lauten, dass man Google doch aussperren könnte. Klar kann man das, was noch nicht mal Herr Keese bestreitet. Aber es wäre aufgrund des Monopol, das Google mit einem Marktanteil von weit über 90 Prozent unbestritten besitzt, Selbstmord des eigenen Geschäfts im Internet.“
Und wer zwingt die Keeses dieser Welt und Dich dazu, Google komplett zu blockieren, wenn man den Google Imagebot auch separat aussperren kann?
User-Agent: Googlebot-Image
Disallow: /HQ-Bilder/
Ui, wie anstrengend.
Dass Bilder in der Originalgröße angezeigt werden ist weniger schlimm für mich. Bedenkenswert dabei finde ich, wie das Ranking zustande kommt! Ich habe mal nach Fotos von mir gesucht, diese finde ich auch ganz oben. Direkt danach kommen aber weitere Fotos von mir –mit dem selben Suchbegriff – die aber in eine andere Seite eingebettet sind.
Der Betreiber der Seite hat ganz ordentlich im Titel und im „alt“ Tag meine Adresse als Quelle angegeben: Warum werden denn nicht diese Bilder unter MEINER Adresse gelistet??? Da macht Google eindeutig etwas falsch!
@ 132 Jeff
Ich würde meine eigene Marktposition und meine Marktchancen ggü. meinen Mitbewerbern verschlechtern.
Vermutlich verstehen Sie das nicht, aber dafür kann ich nichts.
@134:
„Ich würde meine eigene Marktposition und meine Marktchancen ggü. meinen Mitbewerbern verschlechtern. “
Vermutlich verstehen Sie das nicht, aber dafür kann ich nichts.“
Vermutlich verstehen Sie nicht, daß Sie das Verzeichnis, in dem HQ-Bilder liegen, separat aussperren und die Thumbnails weiterhin zulassen können.
Daß die Technik der robots.txt noch zu neu für Sie ist, dafür kann ich nichts. Google auch nicht.
@132: Fehlen dir die grundlegenden kognitiven Fähigkeiten um auch nur halbwegs zu begreifen, worum es hier geht?
Bevor Google mit dieser neuen Bildersuche ankam musste man nichts aussperren. Es war für alle Beteiligten gut so, wie es war. Kaum ein Website-Betreiber hätte im Traum daran gedacht, Google die Indexierung seiner Bilder zu untersagen. Dass viele Betreiber sich nun gezwungen fühlen, diesen Schritt zu unternehmen, ist doch kein gutes Zeichen, oder?
Deine Argumentation dreht sich ständig im Kreis, weil dir mal von den Silicon-Valley-Cyber-Gurus eingeredet wurde, dass „Information“ „frei“ sein sollte. Wenn jeder mit „Information“ (urheberrechtlich geschützte Werke) tun und lassen kann, was er will, dann gewinnt dadurch nicht etwa die Gesellschaft/Menschheit, sondern ein paar wenige Konzerne.
Was Google und Co. seit einiger Zeit veranstalten, ist das Gegenteil von Nachhaltigkeit. Natürlich haben ihre User Spass daran, Bilder und sonstigen Content so bequem wie möglich zu konsumieren. Dieser Bequemlichkeit standen bisher ein paar Dinge im Weg: manchmal musste man auf die Original-Site, manchmal sogar (OMG!) für Content bezahlen und im Grunde ist es das verdammte Urheberrecht, das Google davon abhält, aus einer Suchmaschine ein Content-Provider zu werden.
Nach Ansicht der Cyber-Hustlers[1] ist jeglicher Content nur „Information“ und nicht etwa ein Werk, in das jemand viel Geld und seine Persönlichkeit gesteckt hat. Für sie besteht kein Unterschied zwischen einem Katzenvideo und einem Musikvideo. Der Macher bekommt unabhängig vom Produktionsaufwand (Zeit, Geld, Kreativität) die selbe Vergütung: 120 Euro pro einer Million Views. Es ist ja letztendlich nur ein Video-Stream, kein Werk, sondern nur „Information“. Dass das fünfminütige Handy-Video in der Herstellung nahezu nichts, das Musikvideo jedoch einen sechsstelligen Betrag gekostet hat, interessiert sie nicht.
Und so ist es auch mit allen anderen Werkarten: wie kann sich jemand darüber aufregen, dass Google Image Search ein paar verwackelte Urlaubsbilder an sich reisst? Bild ist Bild ist Information! Silicon Valley hat nie Content produziert und kann nicht nachvollziehen, dass es auch Bilder gibt, die hochwertiger und in der Produktion teurer sind als ein Schnappschuss. Auf den 1,2(?) Millionen Google-Servern ist jedes Bit gleich viel wert. Dort wird nicht unterschieden, ob ein Bild „billig“ oder „teuer“ ist.
Dazu kommt, dass Silicon Valley einen irrationalen HASS auf Kreative, Kulturschaffende und Künstler hat, den sie in ihrem Grössenwahn nicht einmal mehr zu verbergen versuchen. Es war immer schon ein Kampf zwischen Nord- und Südkalifornien. Dies hier ist einer der bekanntesten VCs/Inkubatoren:
„Kill Hollywood“
http://ycombinator.com/rfs9.html
Man will Hollywood (Film-Branche) „killen“, man will Nashville (Musik-Branche) „killen“, man will New-York (Print) „killen“ und irgendwie scheint mir, man will zuerst die Fotografen „killen“. Es geht ständig nur um „Disruption“, weil man der Meinung ist, dass sich ständig alles verändern muss – der Veränderung willen.
[1] http://www.newstatesman.com/sci-tech/internet/2012/12/jeff-jarvis-clay-shirky-jay-rosen-invasion-cyber-hustlers
In wenigen Jahren werden einige – vielleicht auch du – aufwachen und sich fragen, wie sie damals so blind sein konnten. Andere hingegen wissen sehr genau, welches Spiel in Kalifornien gespielt wird.
Für Seitenbetreiber sollte es – sofern sie das wollen – ein Klacks sein, die direkte Verlinkung technisch zu unterbinden. Oder nicht?
Der Traffic-Rückgang durch die neue Suche ist im Übrigen nicht nur plausibel sondern mittlerweile auch bestätigt. Trotz der doppelten Anzahl an Links klagen die amerikanischen Nutzer (das neue Update ist vorerst nur dort online) über Einbrüche bei den Besucherzahlen von 50 bis 70 Prozent: http://blogs-optimieren.de/2422/bildersuche-erste-zahlen-zum-traffic-ruckgang/
Im deutschen Raum dürfte es zu ähnlichen Rückgängen kommen, wenn das Update auch für die deutsche Suche online ist. Durchaus möglich, dass sich Google aber hier noch etwas zurück hält. Man hat angekündigt auf die Rechtslage in den einzelnen Staaten Rücksicht zu nehmen.
@ray:
Google macht eindeutig etwas „falsch“, wenn es die Quell-URI angibt und nicht den Inhalt des ALTernative-Tags oder des TITELs ihrer Bilder mit einem „Suchwort“?
BTW: Das meiste SEO ist ein Problem für Google, da es deren Sicht auf die Welt stört (so wie mich Reklame im „richtigem Leben“).
Sie umgehen sowas, so gut es nur geht.
Denken sie mal drüber nach …
@134 tess: Dann ist das neue Verhalten wohl nicht ’negativ‘ sondern nur ‚weniger positiv‘ für Sie?
@ 138 Stefan Weierstraß
Nein. Siehe bitte Beitrag 128.
@thilo:
Ja, ist es. Man kann aber auch auf vielen anderen Ebenen den Zugriff mit einfachen, gewöhnlichen, standardisierten Mitteln sehr feingranular steuern.
Aber das alles soll der Michel nicht wissen, da es dieses schöne, bequeme „Diebstahl“-Argument zerstören würde, welches aber notwendig ist um an neues Geld zu kommen.
Aufklärung ist kein Primat der kommerziellen Presse.
@139 tess: Habe ich gelesen, überzeugt mich aber nicht wirklich. Ich frage mich, welches tolle Geschäftsmodell denn damit überhaupt angegriffen wird?
Die von SN verlinkte Protestseite stellt es so dar, als ginge es um das illegale Abgreifen hochauflösender Bilder – aber das lässt sich doch verhindern, wurde mehrfach erklärt. Bei den meisten Seiten, die hochauflösende Bilder verkaufen (Agenturen) ist es doch jetzt schon so, dass diese eben _nicht_ frei verfügbar sind, sondern z.B. passwortgeschützt.
Das einzige Geschäftsmodell, das unter der Änderung leidet, scheint mir dieses zu sein: ich stelle einigermaßen wahllos Bilder ein und betreibe SEO, in der Hoffnung auf ein paar Werbeklicks. Ist das so?
@142: „Die von SN verlinkte Protestseite stellt es so dar, als ginge es um das illegale Abgreifen hochauflösender Bilder — aber das lässt sich doch verhindern, wurde mehrfach erklärt.“
Seit wann muss man als Urheber „verhindern“, dass seine Rechte verletzt werden? Seit wann soll nicht mehr nachgefragt werden, bevor man die Werke anderer Leute nutzt und verwertet?
Und nun die entscheidende Frage: wieso muss man das in robots.txt ausschliessen, wenn es hätte anders herum laufen sollen? Google hätte sich die Erlaubnis einholen müssen! Das wäre technisch einfach zu realisieren: alle Website-Betreiber, die ihre hochauflösenden Bilder in der neuen Bilder-Suche haben wollen, müssen ein File namens google-image-bot.txt im DocumentRoot anlegen. Fertig.
Seit es Content-Konzerne gibt, die auf den Content der Nutzer angewiesen sind, scheint der Grundsatz „vor Nutzung anderer Werke fragen“ über Bord gegangen zu sein, oder?
@142 Der Urheber sollte es verhindern wenn sein Geschäftsmodell darin besteht, irgendwie Geld damit zu machen. Das gilt aber allgemein, schon vor dieser Änderung bei Google, und sogar ganz unabhängig von Google.
Wer seine Ware frei verfügbar macht und trotzdem noch auf Einnahmen hofft mag zwar im Recht sein, besonders klug ist er aber nicht. Und ob er in diesem Fall tatsächlich so eindeutig im Recht ist, sehe ich nicht – an anderer Stelle wurde das schon mal verneint.
[…] http://www.stefan-niggemeier.de/blog/dreist-und-dumm-die-neue-bildersuche-von-google/ […]
Kann einer mal genau beschreiben, wie die Fremdeinbindung von Bildern technisch unterbunden werden kann?
Ich schrieb u.a.:
Die ganzen Diskussionen um das Thema LSR und jetzt die Bildersuche sind sehr anstrengend, weil immer die gleichen Argumente kommen, die da u.a. lauten, dass man Google doch aussperren könnte.
Und was kommt anschließend?
– „Und wer zwingt die Keeses dieser Welt und Dich dazu, Google komplett zu blockieren, wenn man den Google Imagebot auch separat aussperren kann?“
– „Vermutlich verstehen Sie nicht, daß Sie das Verzeichnis, in dem HQ-Bilder liegen, separat aussperren und die Thumbnails weiterhin zulassen können.“
– „Für Seitenbetreiber sollte es — sofern sie das wollen — ein Klacks sein, die direkte Verlinkung technisch zu unterbinden. Oder nicht?“
– „Man kann aber auch auf vielen anderen Ebenen den Zugriff mit einfachen, gewöhnlichen, standardisierten Mitteln sehr feingranular steuern.“
– „Die von SN verlinkte Protestseite stellt es so dar, als ginge es um das illegale Abgreifen hochauflösender Bilder — aber das lässt sich doch verhindern, wurde mehrfach erklärt.“
————–
Dass all die Sperr-Ideen nicht im Geringsten etwas mit meinem Beitrag, geschweige denn mit dem Beitrag von S. Niggemeier zu tun haben, lässt sich in diesem Leben offenkundig nicht mehr vermitteln.
Hallo Alle,
ich muß mal dumm dazwischen haken und entschuldige mich schon im voraus. Mein Verständnis: Was frei im Web abzurufen ist, ist frei abzurufen. Das entbindet zwar nicht vom Urheberrecht und berechtigt auch nicht dazu, daß jemand anderes für dieses nicht ihm gehörende von Dritten Geld verlangt, aber es ist doch erstmal (wenn nicht unterbunden), frei abzurufen? Bin ich total auf dem Holzweg? Das ist daoch als würde der nichtsahnende Mitarbeiter eine Excel-Tabelle mit Firmenpaßworten ins Web stellen und dann Google schimpfen, wenn es die _Suchergebnisse_ anzeigt. Habe ich jetzt eine völlig falsche Sichtweise? Wo ist der Haken?
@149 Thomas Hofmann:
Dass der Urheber darüber bestimmen kann, wie seine Werke genutz werden. Nur weil ich mein Werk (Bild, Text, Musik,…) auf meiner Webseite kostenlos zur Nutzung anbiete heißt das ja nicht, dass jeder andere mein Werk auch kostenlos anbieten darf. Das freie Abrufen gilt natürlich schon (ich kann kein Geld von jemandem verlangen, der sich mein Bild auf meiner Webseite angesehen hat, wenn ich es ohne Schranken zur Verfügung stelle), aber eben nur auf der meiner eigenen Webseite. Wenn jemand anderes mein Werk nutzen will (was Googel wohl tut, indem es das Bild in voller Größe auf den eigenen Seiten zeigt), dann muss er mich fragen.
Man kann mit etwas htaccess-Magie, insbesondere Auswertung des Referer-Tags, jedes Deeplinking, auch das von Google aushebeln. Somit gilt auch das gleiche Argument wie beim LSR.
@149: „Was frei im Web abzurufen ist, ist frei abzurufen. […] Habe ich jetzt eine völlig falsche Sichtweise? Wo ist der Haken?“
Es macht einen Unterschied, ob man auf die Inhalte eines Dritten verlinkt oder ob man diesen Inhalt übernimmt. Niemand käme auf die Idee, diesen Blog-Post von Niggemeier 1:1 in seinem eigenen Blog zu übernehmen – auch nicht als IFrame eingebunden. Das Zitieren und Verlinken ist jedoch absolut in Ordnung.
Google „zitiert“hier nicht mehr den Inhalt, sondern übernimmt ihn vollständig. Es spielt dabei keine Rolle, wie das technisch implementiert ist, sondern wie es beim User ankommt.
Du bist – wie derzeit leider sehr viele – der Meinung, dass alles, was ins Netz gestellt wurde, zur freien Verfügung steht. Wäre das so, dann würden diejenigen, die die Werke schaffen, sehr bald damit aufhören, sie ins Netz zu stellen. Der einzige Grund, weshalb sie das tun ist, dass sie eine Handhabe gegen jene haben, die ihre Werke ungefragt nutzen.
Im Heise-Forum musste ich kürzlich das hier lesen:
Das ist ein leicht abgewandeltes Mantra der „Free Culture“-Bewegung, die die Schuld am unmoralischen Handeln der Ausbeuter auf die Ausgebeuteten schieben will. „Information wants to be free!“ – es soll keine Schranken mehr zwischen „Content-Erzeugern“ und -Konsumenten geben. Nicht einmal mehr die Schranke, dass der Erzeuger bestimmen darf, was mit seinem Content geschieht, wo und wer ihn nutzen darf oder nicht. Damit wird dem Schaffenden jegliche Kontrolle und die Möglichkeit genommen, mit seiner Leistung Geld zu verdienen.
Andreas Roedl, du hast mir nicht zugehört.
Jakob: „dann muss er mich fragen“
Wo steht das? Was heißt bei dir übernehmen? Ist dieser Begriff international und rechtlich in den betroffenen Ländern (hier USA + Deutschland) bestimmt? Fragen über Fragen. Jeder mit einer eigenen Website hat die Möglichkeit, die Zugriffe auf die Inhalte zu steuern/zu unterbinden.
Bitte nicht falsch verstehen. Ich will nicht gut heißen, was Google tut. Aber tun die Beschwerdeführer selbst etwas dazu, die Situation zu verändern?
@151 Falk D.
Der Vergleich hinkt. Beim LSR brandmarken die Verlage bisher das Veröffentlichen von ungeschützten Textschnipseln (Snippets) als geistige Enteignung. Derzeit ist es eben noch so, dass einzelne Wortkombinationen nur in Ausnahmefällen vom Urheberrecht geschützt werden (mMn mit gutem Grund). Die Verlage jammern nun darüber, dass die Suchmaschinen quasi parasitär deren Arbeit vergolden würden und man das Listen nur deshalb nicht verhindern könne, weil man kein Verbietungsrecht hat. Dem Argument kann man damit entgegen treten, dass man auf die robots.txt verweist. Denn damit lässt sich das Listen nämlich wirkungsvoll verhindern.
Beim Urheberecht ist es aber ja nunmal so, dass sich die Gesellschaft entschieden hat geistige Schöpfungen als schützenswert anzusehen und deshalb gibt es schon ein Verbietungsrecht, nämlich das Urheberrecht. Ihr Argument kommt deshalb über ein Jahrhundert zu spät, denn es wäre vielleicht mal eines gegen die Einführung des Urheberrechts gewesen.
Der Punkt ist: Es gibt meiner Meinung nach einen ziemlich relevanten Unterschied zwischen Textschnipseln oder ganz gewöhnlichen Sätzen auf der einen Seite und Artikeln, Romanen, Musikstücken, Bildern, Filmen etc.. Es stellt sich bei Ihrem Vergleich also eigentlich die Frage, ob Sie ein LSR einführen oder das Urheberrecht abschaffen wollen.
@153:
Das steht zum Beispiel in der Allgemeinen Erklärung der Menschenrechte unter Artikel 27, Absatz 2. Der Kern weltweit aller Urheberrechtsgesetze ist der, dass man vor Nutzung der Werke anderer, diese um Erlaubnis fragen muss.
Dass dies mit Hilfe von DMCA und OCILLA (Online Copyright Infringement Liability Limitation Act) in den USA aufgeweicht wurde, ist ja nicht unsere Schuld. Die Welt sah damals noch vollkommen anders aus und wenn etwas im grossen Komplex „Urheberrecht“ reformiert werden müsste, dann an diesen beiden „Acts“. Das ist übrigens auch der Grund, warum Google diese neue Bildersuche noch nicht in Deutschland eingeführt hat. Hier gibt es kein DMCA, das besagt, dass man als Mittelsmann Content ungeprüft anbieten darf, bis der Urheber ankommt und dies untersagt, was sich langfristig betrachtet noch als Vorteil erweisen wird.
@Stefan Niggemeier:
Wieso muss ich eigentlich immer wieder moderiert werden? Schreib ich zu lang? Oder zu böse? Oder zu falsch? Fragen über fragen…
@Hoffmann:
Das folgt aus dem UrhG.Das gilt aber natürlich nur in Deutschland, weswegen Google.de ja die Bildersuche bisher auch nicht hat. Im internationalen Web ist das UrhG dann doch ein bisschen hilflos.
Aber eine Gegenfrage: Wenn ich in einen Buchladen gehe und mir ein Buch klaue (oder von mir aus Material und Druckkosten bezahle), ist das dann in Ordnung, weil der Laden mich ja reingelassen hat?
Was hier (viel)leicht übersehen wird, ist, dass Google mit der neuen Bildersuche den Content-Anbietern kaum noch Anreize bietet, ihre Bilder indizieren zu lassen. Wenn man den Nachteil hat (und den Traffic bezahlen muss), ohne dagegen auch die Vorteile genießen zu dürfen (nämlich dadurch auch z. B. PIs zu generieren), verliert das ganze System einseitig seine Grundlage.
Die Folge ist (und dazu würde ich auch jedem Kritiker hier raten), dass immer mehr Anbieter von attraktivem Bild-Content dazu übergehen, ihre Produkte eben nicht mehr über die Bildersuche anzeigen zu lassen – wozu auch? Es gibt schlicht kaum noch sinnvolle Gründe dafür. Letztendlich würde sich, bei entsprechender Anzahl, die ganze Aktion eben für Google selbst problematisch auswirken. Was nutzt eine Bildersuche dem User, wenn er dort nur dritt- oder viertklassiges Material geboten bekommt?
Und genau an dieser Stelle krankt meiner Meinung nach der Monopolvorwurf. Sicherlich ist Google derzeit die unangefochtene Nummer Eins, auch und gerade bei der Bildersuche. Doch der Grund dafür liegt in erster Linie bei den Ergebnissen, die diese Suche zuweilen zutage fördert – nicht darin, dass es keine Alternativen gibt (oder geben könnte). Ein findiger Geist mag an der Stelle nun vielleicht an die Etablierung einer eigenen Bildersuche denken, die vermehrt auf die Wünsche und Bedürfnisse der eigentlichen Content-Anbieter eingeht. Selbstverständlich wäre das zunächst einmal mit viel Arbeit verbunden, doch letztlich liegt die Macht doch bei denjenigen, die ihren Content zur Verfügung stellen – oder dann eben auch nicht.
Insofern: Wer sich über das Gebaren Googles ärgert, sollte vielleicht wirklich einfach Nägel mit Köpfen machen und auf die Indizierung verzichten. Einen Grund, das nicht zu tun, gibt es ja jetzt offensichtlich nicht mehr (wenigstens bei kommerziell orientierten Anbietern).
@147: Das Verbieten der Einbindung von Bildern per Link erfolgt üblicherweise über die Konfiguration des Webservers. Entweder per .htaccess bei Apache oder mit webconfig bei IIS.
@151: Nein, das ist etwas ganz anderes als beim LSR. Beim LSR geht es eben NICHT um das GESAMTE Werk, sondern nur um Auszüge. Um Snippets, Links. Um Zitate.
Hier geht es darum, dass ein multinationaler Konzern das gesamte Werk in seiner Vollständigkeit als Teil seiner eigenen Seite ausgibt, den User monetarisiert, aber die Kosten für die Auslieferung dem Webseitenbetreiber aufbürdet und ihm obendrein den User vorenthält.
Das ist etwas ganz anderes als „Aggregator linkt mit Snippets auf Verlag“. Das wäre wie „Aggregator kopiert ganzen Artikel und stellt ihn auf seine eigene Seite“.
Andreas Roedl:
Ein Link war wohl zu viel Arbeit, ich glaube nicht, du kannst das aus dem Kopf zitieren. Aber wahrscheinlich bist du auch ein Anhänger dieses unsäglichen lmgtfy. Was für ein Widerspruch in sich. :-)
Lieber alter Jakob:
Kannst du nicht lesen oder schreibst du meinen Namen absichtlich falsch? Provokation hilft in dieser Diskussion nicht weiter. Du darfst auch gern Thomas sagen, aber ich weiß natürlich nicht, wie der sonstige Umgangston in deiner Familie ist.
Du vergleichst Äpfel mit Birnen. Die Bilder werden nicht geklaut. Sie liegen nach wie vor auf deinem Server. Deine Aussage ist einfach falsch. Was du versuchst ist polemische Volksverdummung und hilft der Sache auch nicht weiter.
@158:
Du wirst dich wundern, aber wenn man sich schon seit mehr als zehn Jahren mit dem Thema beschäftigt, kann man ziemlich viele Dinge aus dem Kopf zitieren.
Und das hier nennt man Projektion (2. Ergebnis in der Google-Suche):
@alter Jakob (wg. Moderation): Keine Ahnung, liegt nicht an mir.
@97 Stefan Niggemeier schreibt „Nach der gleichen Logik könnte Google auch meine Artikel auf dieser Seite im Volltext bei sich anzeigen, wenn jemand nach entsprechenden Begriffen sucht.“ Vielleicht verstehe ich da etwas nicht. Genau macht die alte Bildersuche, wie auch oben im Beitrag demonstriert, das Bild mit der Seite im Volltext anzeigen, in einem Frame. Aus verständlichen Gründen ändert man das nun, zeigt den Text nicht mehr an, nur noch das Bild. Natürlich kann man die vergrößerte Bildvorschau kritisieren, gleichzeitig aber die alte Bild/Text Vorschau zu loben, das verstehe ich nun wirklich nicht. Irgendwie verheddern sich wohl alle wegen der unsäglichen LSR-Lobby-Aktion, bei der die FAZ sich leider dem Springerverlag als Gehilfen andient.
@ Thomas Hofmann: „polemische Volksverdummung“?
Ne Nummer kleiner hatten Sie es nicht?
Um die immerwährende Diskussion um „Diebstahl vs. die Bilder sind ja noch da, also nicht geklaut“ zu beenden, braucht es eine eindeutige Definition, in wie weit auch die Kopie eines meiner Bilder „Diebstahl“ darstellt.
Wenn jemand in meinen Laden kommt, mir ein Buch aus dem Regal nimmt und damit ohne zu bezahlen hinausgeht, ist es Diebstahl. Er tut etwas mit meinem Eigentum, das ich nicht möchte.
Genau so der, der auf meine Website kommt, dort eines meiner Bild kopiert und damit ohne zu bezahlen geht. Auch hier tut er etwas gegen meinen Willen. Er hat sich etwas ohne mein Einverständnis angeeignet, nämlich eine Kopie meines Bildes. Und es ist dabei völlig egal, ob das Original noch auf meinem Server liegt. Es ist eine Form von widerrechtlicher Eigentumsaneignung, also Diebstahl.
Und allein die Tatsache, dass ich eine Website habe, auf der ich Bilder anpreise und zur Schau stelle, bedeutet nicht, dass sich die jeder kopieren darf.
Dann dürfte auch niemand mehr Waren ins Schaufenster stellen, da dies ja dann die analoge Aufforderung wäre, diese doch bitte kostenlos mitzunehmen.
Und wenn der Vergleich hinkt, weil ich meine Bilder auf meiner Website nicht zu kommerziellen Zwecken anbiete, dann greift als Beispiel jemand ganz gut, der sich ein freistehendes Ladenlokal anmietet, um im Schaufenster Exponate seiner Kunst auszustellen (möglicherweise sogar ohne direkte Verkaufsabsicht, sondern primär, um zu zeigen). Diese darf man auch nicht mitnehmen, denn sie gehören dem Künstler.
@Widder: In diesem Frame wird aber die komplette Seite geladen, auf der das Bild liegt. Schauen Sie sich das Beispiel oben mit dem Eric-Schmidt-Foto aus der FAZ an. Bei der alten Bildersuche werden alle Inhalte der FAZ geladen, ich sehe den Kontext des Bildes, die redaktionelle Leistung der FAZ und die Werbebanner, mit denen die FAZ Geld einnimmt, womit sie Fotografen bezahlen kann. Dass das bloß in einem Frame stattfand, änderte ja daran prinzipiell nichts.
Puh, und ich dachte schon, die Sache würde hier noch zu hoch aufgehängt.
Lieber Tomahs
Ich hoffe ich habe dein Selbstwertgefühl nicht allzusehr durch das überflüssige „f“ beschädigt. Das war nicht meine Absicht. Wer allerdings anderen Provokation, Polemik und Unverständnis vorwirft, der sollte selber nicht so provokativ, polemisch und unverständig „argumentieren“.
Mir ist bewusst, dass Vergleiche von realen Gegenständen mit beliebig reproduzierbaren Daten immer schwierig sind. Deshalb habe ich ja gesagt, dass das Material und die Druckkosten bezahlt werden und damit alles, was den gegenständlichen Wet des Buchs ausmacht. Insofern wird das Buch nach deiner Definition ja nicht „geklaut“, denn ich nehme ja nur den Inhalt umsonst mit. Das ist absolut exakt das Gleiche, was du für das Internet forderst.
Denn nur weil ein Urheber jemanden auf seine Seite lässt (z.B. Google) ist damit nicht das Einverständnis zu einer Nutzung der Inhalte der Seite gegeben. Lediglich das Anschauen ist erlaubt, alles andere ist ohne Einverständnis des Urhebers ebensowenig erlaubt wie das stehlen von Büchern (mit einigen Ausnahmen die im UrhG geregelt werden, aber die greifen bei der Nutzung durch Google sowieso nicht). Das sagt das UrhG. Damit hast du die Antwort auf die Frage nach dem Haken erhalten, auch wenn du das vielleicht nicht verstehst oder nicht verstehen magst.
Das man Google aussperren kann (was wohl viele machen werden) macht das Vorgehen von Google übrigens nicht legitim. Wenn man jeden Dritten aussperren müsste, bei denen man eine unberechtigte Nutzung verhindern will, dann wäre die Folge, dass man niemanden mehr auf seine Webseite lassen darf. Oder um auf meinen (in keiner Weise hinkenden) Vergleich zurück zu kommen: Nur weil man Leute in seinen Buchladen lässt, ist das nicht die Einverständniserklärung die Bücher zum Selbstkostenpreis mitzunehmen.
@156 alter Jakob: Der hinkende Vergleich mit einem Ladendiebstahl wird ja durch Wiederholung nicht besser – es schmerzt nur etwas, die ewig gleichen (falschen) Argumente der LSR-Befürworter jetzt auch hier zu lesen.
Aber selbst wenn man sich auf das Argument einlässt, stellt man schnell fest, dass es überhaupt nicht weiterhilft. Zu Ihrer Gegenfrage eine Gegen-Gegenfrage:
Wenn Diebstahl verboten ist, wieso macht sich der Ladenbesitzer dann die Mühe, seinen Laden mit Kameras auszustatten, RFID-Tags an der Ware anzubringen, Kassiererinnen anzustellen? Warum haben an der Kasse aushängende Gutscheinkarten keinen Wert, bevor sie durch die Kassiererin aktiviert wurden? Warum kriege ich im Elektronikmarkt das Produkt nicht sofort ausgehändigt, sondern stattdessen nur einen Laufzettel mit dem ich mir das Produkt gegen Bezahlung an der Information abhole? All das sind doch überflüssige Kosten, der Inhaber könnte ja stattdessen auch einfach ein Schild über dem Eingang anbringen, auf dem steht: ‚Sie dürfen keine Ware ohne Bezahlung aus diesem Geschäft nehmen.‘
Verwandte Frage: Wenn der Inhaber dies alles nicht tun würde – also zum Beispiel seine teure Ware in einem Regal _vor_ dem Geschäft an einer von innen nicht einsehbaren Stelle präsentiert – und dann für einen Diebstahl seine Versicherung in Anspruch nehmen möchte. Was würde ihm die wohl erzählen? Mir kommt da der Begriff ‚Fahrlässigkeit‘ in den Sinn.
Der Geschäftsinhaber handelt ungefähr so, wie die Bildeigentümer gerne weiter handeln möchten. Selbst wenn es also Diebstahl wäre, was Google da treibt – es macht die Handlungsweise der Eigentümer nicht sinnvoller.
Das Verfahren von Google als Diebstahl zu bezeichnen funktioniert übrigens nur bei einer sehr speziellen Definition der Begriffe ‚Übernahme’/’Kopie’/’Zitat‘, so wie in @152 versucht. Wenn ich mir vor dem Hintergrund das Paperboy-Urteil durchlese, kommen mir ziemliche Zweifel ob diese Definitionen zulässig sind.
@Stefan Weierstraß:
Ich bin kein LSR-Befürworter, finde aber, dass dieses Argument einiges für sich hat (vgl. auch meinen Kommentar unter #163)
In einer idealen Welt reichte das Schild des Ladenbesitzers in Ihrem Beispiel. Wir leben aber nicht in einer solchen. Es gibt Leute, die umsonst mitnehmen, DVDs aus dem Supermarkt genau so wie Bilder von Webseiten.
Anders als der Ladeninhaber habe ich zunächst aber keine Möglichkeit, Kassierer anzustellen, Alarmanlagen zu installieren oder RFID-Tags anzubringen. Nun wurden weiter oben schon Sicherungsmaßnahmen beschrieben, wie ich meine Bilder Diebsahlsicher machen könnte. Die Konsequenz wäre aber bei einigen, die davon leben wollen, dass kaum noch jemand auf ihre Website kommt, um dort Bilder zu kaufen.
Auf das reale Leben übertragen: Stellen Sie sich eine Ladenzeile mit Millionen von Geschäften vor. Einige blinken und glitzern, um die Kunden anzulocken und andere haben die Schaufenster mit Brettern vernagelt und Dobermänner vor der Tür angleint. In welchen Laden gehen die Kunden wohl eher, grade wenn es ein so ungleich größeres Angebot im Internet gibt, als vergleichsweise Supermärkte in einer Innenstadt?
Nur weil ich die Möglichkeit habe, etwas kostenlos zu bekommen, muss ich diese nicht in Anspruch nehmen, egal, wie einfach der Anbieter es mir macht.
Klauen Sie eine Stange Zigaretten (oder was anderes) aus einem Laden, nur weil der Besitzer grade (zugegebenermaßen leichtsinnigerweise) diesen unbeaufsichtigt zurückließ? Es geht hier nicht darum, ob er leichtsinnig war, fahrlässig handelte und was seine Versicherung dazu sagen wird. Es geht um Ihr Verhalten als jemand, der vor der Entscheidung steht, das Richtige oder das Falsche zu tun. Was tun Sie?
Ich frage mich gerade, ob es den anwesenden Urheberrechts-Kritikern, die gleichzeitig auf robots.txt und Watermarks hinweisen, auffallen wird, dass beide Maßnahmen auch eine Art DRM ist. Aus der Ecke der Urheberrechts-Revolutionäre wird ja auch gerne mal die Abschaffung jeglicher „Gängelung der Konsumenten/Nutzer“ (DRM) gefordert. Google ist in diesem Falle ebenfalls ein Nutzer.
Auffällig ist wie immer, dass die Verantwortung auf die Schöpfer der Werke abgewälzt wird.
@Stefan Weierstraß:
In Bezug auf den Vergleich Kopie/Diebstahl stimme ich zu, dass dieser gerne überzogen und vor allem auch falsch verwendet wird. Der Punkt auf den ich hinaus wollte ist der, dass die unberechtigte Nutzung von Urheberrechtlich geschützten Gütern verboten ist. Genauso wie Diebstahl verboten ist, der im Übrigen sogar dann verboten bleibt, wenn das Geschäft keine Vorkehrungen gegen Diebstahl getroffen hat. Denn die werden ja nur deshalb getroffen, weil sonst das gediebstahlte Gut verloren geht – immerhin, in diesem Fall ist ein Urheber besser dran, denn die Kopie hat er nicht vorher besessen und kann sie daher nicht verlieren. Und ich habe noch von keinem Fall gehört, in dem ein Urheber sein Werk gegen kopieren versichert hätte. Vielleicht ist das ja eine Marktlücke, obwohl ich stark annehme dass eine solche Versicherung finanziell eher unrentabel für den Versicherer ist…
Im Übrigen verweise ich für die Erläuterung meines Vergleichs auf #166.
Mich würde aber Ihr Vorschlag interessieren, wie bspw. ein Fotograph seine Bilder anpreisen soll, wenn er sie niemandem zeigen darf? Oder ist das Internet als Markt für Urheber halt einfach verboten? Oder darf ich Sie so verstehen, dass das Urheberrecht generell abgeschafft werden soll? Dann kann ich Sie immerhin verstehen, wenn ich auch nicht der gleichen Meinung wäre.
@Andreas Roedl
Sie finden es auffällig, dass man von jemandem, der einen Inhalt öffentlich macht, verlangt, dazuzusagen, wenn er bestimmte Formen von Öffentlichkeit dann doch nicht meint?
@166: ‚Deshalb habe ich ja gesagt, dass das Material und die Druckkosten bezahlt werden und damit alles, was den gegenständlichen Wet des Buchs ausmacht. Insofern wird das Buch nach deiner Definition ja nicht »geklaut«, denn ich nehme ja nur den Inhalt umsonst mit.‘
Warum nicht noch einen Schritt weitergehen, um den Vergleich noch passender zu machen: Anstatt für Material und Druckkosten des weggenommenen Buchs zu bezahlen, lassen Sie das Buch gleich im Laden. Sie setzen sich dort hin und lesen es gleich an Ort und Stelle durch.
Einige Buchhandlungen dulden das – die bieten dann sogar Sitzecken an und verkaufen Kaffee, damit es ein angenehmerer Aufenthalt wird. Andere schweißen ihre Bücher in Folie ein, um so etwas zu verhindern. Wo stehen wir dann in etwa beim ‚Bilderklau‘?
@164 Stefan Niggemeier, rutscht man so nicht in die „Zueigenmachen von fremden Webseiten“, http://de.wikipedia.org/wiki/Frame_(HTML)#Zueigenmachen_von_fremden_Webseiten, eine wesentlich vielschichtigere Problematik? Ich möchte in der heutigen Situation keine Suchmaschine sein :)
@kasuppke:
An Sie die gleiche Frage: Unbeaufsichtigter Laden, weit und breit keine Menschenseele. Greifen Sie über die Ladentheke, um sich etwas, das Ihnen nicht gehört, anzueignen?
@172:
Dann passt aber der Vergleich nicht mehr, weil sie das Internet ja auch zuhause lesen ;)
Und es ist doch schön, dass Buchhandlungen das Dulden, denn sie könnten es auch untersagen. Die machen das aber nicht aus Selbstlosigkeit, sondern weil es sich insgesamt rechnet. Wenn im Ergebnis mehr Geld in der Klasse klingelt, dann stimmt ja alles. Das wäre im Übrigen auch bei der Google-Bildersuche so: Wenn denn die Urheber profitieren würden, dann würde sich keiner beschweren (auch wenn sie es könnten).
@170: ‚Mich würde aber Ihr Vorschlag interessieren, wie bspw. ein Fotograph seine Bilder anpreisen soll, wenn er sie niemandem zeigen darf? Oder ist das Internet als Markt für Urheber halt einfach verboten?‘
Da muss ich gar nicht viel vorschlagen, sondern kann einfach auf existierende Angebote verweisen. Eins davon, zufällig herausgepickt, ist http://http://de.fotolia.com/
Man kann dort ohne Anmeldung suchen und sieht auch Bilder in niedriger Qualität als Ergebnis. Will man sich von der tatsächlichen Qualität überzeugen, kann man in das Vorschaubild hereinzoomen. Will man für eine spätere Bildverwendung schon mal ein Layout herstellen, kann man eine beabsichtigt schlechte Version mit Wasserzeichen kostenfrei herunterladen.
Einzig und allein das Bild in guter Auflösung (also das eigentliche ‚Produkt‘) ist hinter einer Bezahlschranke versteckt, und dementsprechend auch sicherlich nicht über eine Google-Suche auffindbar.
Es gibt Gesetze, die Ladendiebstahl verbieten. Und entsprechende Urteile. Zeigen Sie mir die Gesetze, die das Vorgehen von Google verbieten. Und die Urteile.
@ Stillwater
„Auf das reale Leben übertragen: Stellen Sie sich eine Ladenzeile mit Millionen von Geschäften vor. Einige blinken und glitzern, um die Kunden anzulocken und andere haben die Schaufenster mit Brettern vernagelt und Dobermänner vor der Tür angleint. In welchen Laden gehen die Kunden wohl eher […]“
Das ist eine sehr zutreffende Beschreibung. Aufs Internet übertragen könnte ich, wenn ich Google (teil)sperre, auch gleich meinen Stecker ziehen. Aber das will nicht in die Köpfe Einiger, die sogleich wieder mit einer Antwort kommen, dass ich Google doch (teil)sperren kann.
@tess
Und weil SIE Google brauchen, soll Google nach IHRER Pfeife tanzen? Willkommen in der Welt.
@168: ‚Auf das reale Leben übertragen: Stellen Sie sich eine Ladenzeile mit Millionen von Geschäften vor. Einige blinken und glitzern, um die Kunden anzulocken und andere haben die Schaufenster mit Brettern vernagelt und Dobermänner vor der Tür angleint. In welchen Laden gehen die Kunden wohl eher, grade wenn es ein so ungleich größeres Angebot im Internet gibt, als vergleichsweise Supermärkte in einer Innenstadt?‘
Auch dieser Vergleich hinkt, meiner Meinung nach. Passender wäre vielleicht folgende Situation: zwei Juweliere nebeneinander. Der eine stellt echte Schmuckstücke in seinem Schaufenster aus, der andere stellt aus Versicherungsgründen nur Imitate aus.
Diese Imitate sind weniger wert als Originale (weil aus Blech und Glas statt aus Gold und Diamant), aber man kann die Gestaltung der im Geschäft zu kaufenden Schmuckstücke klar erkennen.
Würden Sie jetzt ausschließlich beim ‚echt ausstellenden‘ Juwelier kaufen, oder würden Sie nicht viel eher den Juwelier wählen, der das passende ‚Schmuck-Design‘ ausstellt?
@176:
Das ist quasi die analoge Diebstahlvorkehrung. Immerhin eine wohl halbwegs wirksame Lösung gegen Missbrauch, wobei mich interessieren würde ob man dafür dann den Dienstbetreiber bezahlen muss. Und ist das Vorschaubild eigentlich in der guten Qualität (konnte die Seite nicht laden)? Muss ja, wenn man sich damit von der Qualität überzeugen kann. Und wer hindert mich dann, einfach das Vorschaubild zu kopieren, bspw mit einem Screenshot? Oder wenn ein Käufer das Bild legal aber ohne Bezahlschranke veröffentlicht? Darf das dann wieder kopiert weden, ist ja immerhin frei zugänglich?
Ist aber eigentlich auch nicht so wichtig. Fakt ist: Urheberrechtlich geschützte Werke dürfen nicht ohne Erlaubnis genutzt werden. Auch nicht im Internet. Und das bloße Bereitstellen von Inhalten auf der eigenen Seite ist keine Einverständniserklärung zur beliebigen Nutzung.
Da zeigt sich mal wieder, dass das Internet nur deshalb „unfrei“ wird, weil sich manche Menschen und Konzerne nicht an grundlegende Abmachungen halten.
Nun wird man also seine Bilder in Briefmarkengröße oder mit Watermarks versehen ins Netz stellen, weil sich ein Konzern nicht benehmen konnte. Aus dem gleichen Grund stattet man seine Werke mit DRM aus, nicht etwa um die Käufer zu ärgern, sondern weil manche Menschen ein Problem mit dem Begriff „geistiges Eigentum“ haben.
Die „Freiheit im Internet“ wird in Wahrheit von jenen bedroht, die sie immer wieder fordern. Ihre wahre Motivation verbergen sie mit Hilfe von mitunter aberwitzigen Rationalisierungen: Lausauger behaupten, File-Sharing würde doch nur der Popularität des Urhebers dienen; Google behauptet, mit der Umstellung würden mehr Click-Throughs stattfinden. Und überhaupt ist der Content eh nichts wert, also weshalb beschweren die sich überhaupt?
@ Stefan Weierstraß # 178:
Ihr Juwelier-Beispiel hat sicher was für sich. Doch bevor wir uns in mehr oder weniger hinkenden Beispielen verheddern:
Ich kann als Laie nicht beurteilen, wie viel Aufwand es wäre, ein sicheres Angebot für meine Erzeugnisse zu erstellen, wenn ich diese über das Internet anbiete oder einfach nur ein Privatmensch bin, der seine schönen Hobbybilder / Texte / whatever zwar zugänglich, aber nicht einfach kopierbar machen möchte.
Bezogen auf Ihr Beispiel: Wieviel Aufwand es ist, Schmuckimitate zu erzeugen, ins Schaufenster zu legen und die Vor-Ort-Logistik für die echten Schmuckstücke vorzuhalten.
Mir ging es primär darum, ein Bewusstsein für das zu wecken, was der Einzelne da tut und wofür er sich entscheidet, wenn er etwas kostenlos kopiert.
Verantwortung haben beide Seiten: Die Anbieter und die Kunden.
@179: Wie beschrieben kann man in das Vorschaubild hineinzoomen, es wird dann ein Wasserzeichen immer mittig im Bildausschnitt angezeigt. Ein Qualitätsabgleich ist also möglich.
Alle weiteren Ihrer Fragen gehen am Thema vorbei, Sie wollten ja wissen wie ich mir eine mögliche ‚Diebstahlsicherung‘ des armen Fotografen gegenüber der bösen Google-Bildersuche vorstelle. Das ist mit dem Beispiel gezeigt, indem man sich einfach mal vorstellt, die Seite mit dem Vorschaubild wäre zur Indexierung freigegeben, die Links zur Megapixel-Version des Bildes aber eben nicht.
@183 Stillwater: Das ‚Wegsperren der Juwelen‘ ist mit einem Zweizeiler erledigt, wie die ‚Imitate‘ erzeugt werden hängt davon ab, von welcher Größenordnung wir hier sprechen.
Der Hobbyfotograf mit ein paar Bilder könnte das händisch erzeugen. Irgendeine Nachbearbeitung findet sicherlich eh statt. Wenn dann zusätzlich zum Originalbild auch eine verkleinerte Version abgespeichert wird, können diese in unterschiedlichen Verzeichnissen abgelegt und eins davon ‚gesperrt‘ werden.
Bei größeren Webseiten kommt sicherlich ein CMS zum Einsatz, welches eine Funktion zur Bildskalierung in den meisten Fällen mitbringt.
#176:
Sie scheitern ja selbst an dem Vergleich von realen Gegenständen und Inhalten: Der Juwelenkäufer wird sich hüten seine Juwelen zu verlieren, denn dann hat er keine mehr. Das kann dem Bildkäufer aber egal sein, denn er behält sein Bild ja auch wenn es kopiert wird. Und wenn er das Bild bspw. auf seiner Webseite veröffentlicht, dann kann man es ja wieder beliebig kopieren.
Wenn öffentliches kostenlos benutzbar ist, dann kann der Urheber jeden Inhalt genau so lange verkaufen, bis der erste Käufer ihn öffentlich zugänglich macht.Klar, dann kann man natürlich die Veröffentlichung untersagen und wenn er dagegen verstösst muss man halt klagen. Nur, dann kann man doch auch gleich alles so lassen denn welches Recht ich am Ende durchsetze ist dann auch egal.
@kasuppke: #177
„Es gibt Gesetze, die Ladendiebstahl verbieten. Und entsprechende Urteile. Zeigen Sie mir die Gesetze, die das Vorgehen von Google verbieten. Und die Urteile.“
Sie haben die Frage, die ich gestellt habe nicht beantwortet. Wie stehen Sie zu Ihrer Verantwortung, zu Ihren moralisch-ethischen Wertmaßstäben? Begehen Sie einen Diebstahl, wenn niemand hinsieht?
Nur weil es kein offizielles Gesetz gibt, dass den Bilderklau im Internet weltweit einheitlich regelt, bedeutet das, dass Sie sich einfach ein Bild kopieren dürfen?
Digitale Güter sind – im Gegensatz zu stofflichen Gütern – erst ein Phänomen der Neuzeit. Ich bin mir sicher, dass es auch in der Steinzeit schon Regelungen gab, wer sich ein Stück aus dem Beutetier schneiden durfte und wer nicht.
Gemessen daran steckt die Entwicklung von Verhaltensmaßstäben und auch Gesetzen für digitale Güter noch in den Kinderschuhen und Regeln, Gesetze und Urteile müssen sich erst bilden im Laufe der Zeit.
Macht es das dann besser? Dürfen Sie sich Bilder kopieren, nur weil es noch keine Gesetze gibt, die explizit das regeln?
Zumal ja sich auch noch die Frage stellt, ob das, was Google da jetzt macht, vom Urheberrecht gedeckt ist bzw. wäre, wenn diese Suche hier in Deutschland ebenfalls angeboten wird.
@186: ‚Sie scheitern ja selbst an dem Vergleich von realen Gegenständen und Inhalten‘
Naja… wenn Sie mir das jetzt vorwerfen, nachdem ich mehrfach darauf hingewiesen habe, für wie hinkend ich so einen Vergleich selbst halte, dann scheinen Ihnen alle besseren Argumente schon ausgegangen zu sein. :)
#184:
Die anderen Fragen sind essentiell. Denn nach Ihrer Ansicht soll frei zugängliches Material ja auch kostenlos benutzbar sein, wer das Material frei zugänglich macht ist damit nebensächlich. Sie selbst haben doch auf die Problematik realer Gegenstand/reproduzierbare Daten hingewiesen. Die Diebstahlsicherung hilft nur, solange der Urheber die volle Kontrolle über die Verbreitung des Bilds hat. Wenn er es verkauft, verliert er diese und damit Ihrer Auffassung nach auch sein Urheberrecht.
@189, das sind ja jetzt wüste Spekulationen über meine Ansichten und Auffassungen… sicher, dass Sie sich damit nicht auf den Kommentar eines anderen Teilnehmers beziehen?
“ Begehen Sie einen Diebstahl, wenn niemand hinsieht?“
Nein.
Aber ich weiß nicht, warum ich hier darin mitwirken soll, hier die hinkenden Vergleiche noch eine Stadionrunde laufen zu lassen.
Google begeht keinen Diebstahl. Google tut nichts Verbotenes. Vielleicht wird das, was Google tut, irgendwann verboten sein. Verlieren wird dabei dann aber auch ganz bestimmt nicht Google.
Die Vehemenz, mit der hier einige die tapferen Davids gegen den bösen Goliath verteidigen, hat ja fast etwas Niedliches. Wenn die tapferen Davids nicht auf Knien rutschen würden, um die Krumen vom Tisch des Goliath zu bekommen.
@188:
Die Sache ist die, dass ich die Legalität von Kontentkopie und Diebstahl verglichen habe (es ging um die Frage in #149 ob nicht alles was frei zugänglich ist auch automatisch beliebig nutzbar sein muss) und Sie eben die Kopie von Daten mit dem Diebstahl von Juwelen (bzw. deren Schutz) vergleichen. Tut mir leid, da geht mir gar kein Argument aus. Ich kann mich nur wiederholen: Eine geistige Schöpfung ohne Erlaubnis des Urhebers zu Nutzen ist nur in Ausnahmefällen erlaubt.
Ich kann mir allerdings vorstellen, wo das ursprüngliche Mißverständnis liegt, nämlich bei der konkreten Frage ob Google eine Urheberrechtsverletzung begeht oder ob das Vorgehen erlaubt sein muss. Ich persönlich glaube diese Bildersuche nicht erlaubt ist und Google wohl auch, denn sonst wäre die Bildersuche auch auf .de. Darüber kann man aber sicherlich streiten. Aber meine Kommentare haben sich nicht nur auf Google bezogen, sondern waren eher generell.
Dann brauchen wir einen Hinweis auf jedem Bild ‚für größeres Bild bitte anmelden.‘ Das Vorschaubild ist klein, aber für eine Vergrößerung muss man auf die Webseite und sich dort einloggen.
Wenn es das nicht schon gibt.
Natürlich senkt das den Traffic. Weil die Leute, so wie ich es oft tat, nicht nachsehen, ob noch eine größere Auflösung vorhanden ist. Aber ich klicke dabei nie auf Werbung. Es war doch meist toter Traffic, der nur Strom kostet.
Qualitativer Traffic wird damit neu definiert.
Wer nach Inhalten sucht, der sucht nicht über die Bildersuche.
Ärgerlich mag es sein für Seiten, die z.B. TattooBilder umsonst anbieten. Aber wer 1000de Bilder umssonst anbietet, hatte die bisher auch selber geklaut oder billig gekauft. Proffessionelle Bilder waren schon immer kostenpflichtig.
Ich hatte aus Ihrem Kommentar #167 als Antwort auf meinen Kommentar und insbesondere aus diesem Absatz
geschlossen, dass Sie der gleichen Auffassung sind wie Thomas Hofmann, also ebenfalls denken dass alles was frei zugänglich ist auch kostenlos nutzbar sein muss. Wen es nur um meinen vergleich ging, dann habe ich ja schon erklärt wie der gemeint ist. nix für Ungut…
@191: Eigentlich habe ich dort die Bewerbung eines Produkts (=Schmuck) durch ein geringwertigeres Produkt (=Blechschmuck) mit… der Bewerbung eines Produkts (=Bild) durch ein geringwertigeres produkt (=Bild mit Wasserzeichen o.ä.) verglichen. Auslöser war der Kommentar, der nur die ‚digitalen‘ Optionen ‚Bewerben und Diebstahl riskieren‘ und ‚gar nicht Bewerben‘ anbot. Den von Ihnen kritisierten Vergleich habe also nicht ich angestellt.
@193: Selbst Thomas Hofmann stellt in #149 doch nur die Frage, ob ein ‚frei abrufbares‘ Dokument nicht bedeutet, dass man es auch ‚frei abrufen‘ darf.
Die Fragestellung nach einer ‚kostenlosen Nutzung‘ ergibt sich ja erst aus der Interpretation dessen, was Google dort tut. Ist das wirklich eine ‚Nutzung‘, oder handelt es sich bloß um die Zurverfügungstellung eines ‚freien Abrufs‘, der durch den Bildeigentümer zumindest implizit gewährt wurde.
Das war auch das, worauf ich mit meinem Kommentar #167 hinaus wollte. Selbst wenn sich ergibt, dass Google eine nicht erlaubte ‚Nutzung‘ vornimmt ist es doch trotzdem im Interesse des Eigentümers den ‚freien Abruf‘ zu verhindern, wenn er ihn doch eigentlich gar nicht erlauben wollte. Und spätestens dann, wenn ein Profifotograf durch den Verkauf seiner Bilder Geld verdienen will muss man doch einfach annehmen, dass der freie Abruf eben nicht in seinem Interesse ist.
Ich habs schon mehrmals geschrieben:
Das Netz ist ein Medium. Es ist nicht „die Realität“ und funktioniert daher auch anders. Diese Vergleiche mit dem Buchladen sind daher wohl eher hinderlich.
Das Netz sorgt auf technischer Ebene lediglich für Informationsaustausch. Man kann etwas „einspeisen“. Das hat zur Folge, das anderen Netzteilnehmer darauf zugreifen können (=sich eine Kopie davon anfertigen können).
Als das vormals akademische Netz durch das Aufkommen von http (Hypertext-„Webseiten“, ab Version 2 sogar mit eingebettenen Bildern!) populär wurde und die Teilnehmerzahl und Inhalteanzahl explodierte, wurde das Netz zunehmend unübersichtlich.
Anfangs wurden die Inhalte noch von Menschen katalogisiert (DMOZ), später übernahmen Automaten diese Funktion. Die erfolgreichste Suchmaschine war dazumal Altavista und verlies sich beim Ordnen der Inhalte auf die Angaben, die die Erzeuger den Inhalten in maschinenlesbarer Form beifügten. Sehr schnell zerstörten die individuelle SEO-Bemühungen der Einsteller die Qualität solcher Suchergebnisse.
Da erfand Larry Page den einen Algorithmus, welcher die Inhalte ordnete, indem er die Beziehungen der einzelnen Inhalte untereinander analysierte . Seither gibt es Google. Diese Firma verfolgt noch immer den Ansatz ins Netz gestellte Informationen zu analysieren, in eine sinnvolle Ordnung zu bringen und so auffindbar zu machen. Das nur kurz zur Geschichte und zum Verständnis dieses Mediums.
„Das Netz“ kennt also per se keine weitergehenden Rechte an den Inhalten, die eingestellt werden. Sind diese erreichbar, können sie kopiert (=angesehen, gespeichert) werden. So funktioniert das technisch und so ist daher auch das Wesen des Netzes.
Das schließt NATÜRLICH nicht aus, dass Zugriffe auf Inhalte beschränkt werden können. (Bsp: Jeder Internetbrowser läuft auf einem Rechner, der am Internet angeschlossen ist. In der Regel bietet der Rechner aber die auf ihm gespeicherten Inhalte nicht im Netz an – Ausser ein Schadprogramm umgeht diese Einstellung. Aber auch dann wird nicht jeder auf die angebotenen Inhalte zugreifen können, sondern nur der „Virenbetreiber“).
Populäre Beispiele für Zugriffsbeschränkungen sind auch VPN oder passwortgeschütze „Loginbereiche“. Zugriffssteuerung ist also überhaupt nichts neues oder ungewöhnliches.
Google durchsucht nun das Netz auf auffindbare, nicht zugriffsbeschränkte Inhalte (z.B. Bilder) um sie durchsuchbar zu machen. Der Automat kann ohne Mitwirkung der Inhalteeinsteller auf technischer Ebene nicht unterscheiden, ob ein erreichbares Bild auf rechtlicher Ebene „geschützt“ ist, oder nicht. Es ist dann eben einfach erreichbar.
Die Inhalteeinsteller haben nun aber trotzdem zahlreiche Möglichkeiten die Erfassung durch die Suchmaschine zu steuern.
Ist es wirklich zuviel verlangt, dass die Inhalteanbieter einen kurze maschinenlebare Notiz für die Suchmaschinen anbringen? Die menschenlesbare AGB dieser Anbieter zieht sich doch auch häufig gar über mehrere Seiten.
Man muss sich fragen, warum tun sie das nicht? Es wäre ein Klacks! Die selben Leute, die sich hier sträuben verwenden auf der anderen Seite unglaubliche Mittel darauf die Durchsuchbarkeit ihrer Angebote zu optimieren („Suchmaschinenoptimierung“).
Es ist völlig unglaubwürdig, dass diese Leute zu dumm sind, sich mit „Suchmaschinenzugriffssteuerung“ auseinanderzusetzen!
Hier soll auf Kosten eines gut funktionierenden Mediums schlicht Geld kassiert werden. In mit Vernunft nicht zu rechtfertigender Weise. Mehr nicht.
@Andreas Roedl:
Diese „Debatte“ die wir gerade erfahren hat weniger etwas mit dem Silicon Valley zu tun, als mit etwas „typisch deutschem“. Da hat Lothar in #127 durchaus recht.
Ich empfehle dazu das DLF-Feature zu Wau Holland:
http://www.dradio.de/dlf/sendungen/dossier/1968209/
mp3 -> https://netzpolitik.org/2013/der-hacker-wau-holland-oder-der-kampf-ums-netz/
Witzigerweise hat diesen Geist (der auch sie ergriffen hat) indirekt der CCC hier für „das Netz“ nach D getragen …
Es ist erschreckend, mit welchen Argumenten sich hier einige berufen fühlen, Googles Interessen durchzusetzen. Was glaubt ihr zu verteidigen? Natürlich habe ich als Kreativer/Künstler ein Interesse daran, bei Google gefunden zu werden. Das ist genauso legitim wie Googles Wunsch, Geld zu verdienen. Aber: Google darf nicht einfach meine Bilder benutzen, um damit Geld zu verdienen. Der Vorwurf des „Deutsch-seins“ ist lächerlich. Wenn damit gemeint ist, dass man das Aneignen von fremden Inhalten kritisch hinterfragt: ja, dann bin ich deutsch! Und … ?!
Das Argument „Benutzerfreundlichkeit“ ist auch keines. Nochmal: es gibt unendlich viele Möglichkeiten, coole, sehr benutzerfreundliche Anwendungen zu basteln, indem ich mir fremde Inhalte benutze – nur: das darf man nicht!
Ich habe einen Artikel dazu geschrieben, aber der Ping kommt offenbar nicht durch: http://www.tagseoblog.de/google-monopol-gewohnheit-und-science-fiction
Gruß, Martin
@197:
Wo wir dann schon beim Name-Dropping sind:
http://www.smithsonianmag.com/arts-culture/What-Turned-Jaron-Lanier-Against-the-Web-183832741.html
@196:
Und das sehe ich eben anders. Es ist ja eben nicht so, dass der freie Abruf verhindert werden soll, sondern nur die unerlaubte Nutzung. Wieso soll jemand, der seine eigenen Werke aus was für Gründen auch immer umsonst für die Allgemeinheit zum Anschauen bereitstellt, damit auch seine Einwilligung geben, dass andere seine Werke nach deren belieben nutzen dürfen, am besten auch noch kommerziell? Wieso sollte ein Hobbyfotograf seine Bilder hinter einer Bezahlschranke verstecken müssen, wenn er sie eigentlich gerne allen umsonst zeigen will, gleichzeitig aber auch möchte dass diejenigen, die die Bilder sehen wollen, das dann auf seiner Seite tun. Daran ändert auch nichts, dass der Urheber Google nicht aktiv aussperrt. Denn analog könnten ja auch alle anderen verlangen, dass sie solange die Inhalte Nutzen dürfen, bis es ihnen explizit verboten wird (mit welcher Begründung sollte Google denn ein Sonderrecht haben). Und das geht absolut gegen den Sinn des Urheberrechts.Die Nutzung von werken bestimmt der Urheber (theoretisch zumindest). Und das kann eben auch sein, dass man nur sich selbst die kostenlose Nutzung erlaubt.
Es gibt zwar Ausnahmen, in denen eine Bereitstellung von Inhalten gleichzeitig eine Einwilligung für bestimmte Verwendungen der Inhalte ist (bspw. Zweckübertragungstheorie), generell ist es nach derzeitigem Recht aber so, dass der Urheber über die Nutzung seiner Werke entscheidet. Und vor diesem Hintergrund halte ich die Veröffentlichung von Google für problematisch, weil ich die Veröffentlichung der Originalbilder in der Googlesuche aus dem ursprünglichen Umfeld heraus als verbietbar ansehe. Auch wenn das Google wohl nicht die Bohne interessiert.
@Dexter#197:
Das ist schon alles nicht falsch, was Sie schreiben. Allerdings kann Google doch selbst und völlig unabhängig vom gefundenen Inhalt entscheiden, wie die gesuchten Inhalte angezeigt werden. Denn das entscheidet nur Google. Und da kann man durchaus der Meinung sein, dass eine Bildersuche unzulässig ist, die die Suchergebnisse aus dem ursprünglichen Umfeld herauslöst und in Originalgröße und -auflösung vor dem Googlehintergrund anzeigt.
@alter Jakob:
Sie schreiben
Die Nutzung von werken bestimmt der Urheber (theoretisch zumindest).
Eben! Er kann dies bestimmen. Dazu muss er es aber kommunizieren. Er sagt es den Usern menschenlesbar auf seiner Seite (z.B. Nutzungsbedingungen, AGB) und er kann es auch Suchmaschinen mitteilen.
Warum also bestimmen das manche Urheber in Bezug auf die Suchmaschinen nicht, obwohl sie könnten? Und regen sich danach auf, wenn die Suchmaschine zugreift?
Diese Suchmaschinen klauen nichts, sie nehmen, was ihnen technisch zum Mitnehmen ohne weitere Forderungen hingelegt wir!
Wenn man – entgegen dem Wesen des Netzes – mutwillig einführt, dass es Inhalte gibt die technisch identisch und ununterscheidbar vorliegen, die aber rechtlich betrachtet unterschiedlich behandelt werden müssen, dann wird es unmöglich gemacht, eine Suche anzubieten. Wir müssen dann ohne eine solche Suchmöglichkeiten auskommen.(Beachte: Das gilt nicht nur für Bilder!)
Cui bono?
@Andreas Roedl
Immer wieder erheiternd, wenn US-Amerikaner von Kommunismus sprechen. (BTW:“Lanier machte als scharfer Kritiker von Wikipedia und der Open Source-Bewegung von sich reden.“ -> siehe WP :P)
Grusel…
@Mißfeldt:
Aber: Google darf nicht einfach meine Bilder benutzen, um damit Geld zu verdienen.
Wo ist das ProblemDann sei dir ein fröhliches
User-Agent: Googlebot-Image
Disallow: /HQ-Bilder/
empfohlen. Woher sollen Google (und die anderen Sumas) sonst wissen, was du willst?
Sollen die eine Gedankenlesevorrichtung erfinden?
@200: Das ist aber doch ein Totschlagargument gegen eine Bildersuche allgemein, und nicht ein Argument gegen speziell _diese_ Ergebnispräsentation einer Bildersuche.
Auch bei der alten Variante der Bildersuche konnte man sehr gut um die Betrachtung der Originalwebseite herumkommen – die war ja nur im Hintergrund zu sehen, teilweise verdeckt von der Bildvorschau. Wenn mich nur das Bild interessiert hat, habe ich dann im rechten Frame auf ‚in Originalgröße anzeigen‘ geklickt, und musste es nicht erst mühsam im Kontext der Seite wiederfinden. Ob das jetzt moralisch verwerflich war oder nicht, muss wohl jeder für sich entscheiden. Ich bin der Meinung, dass ich da nur von dem mir eingeräumten Recht auf ‚freien Abruf‘ Gebrauch gemacht habe und habe deswegen kein schlechtes Gewissen.
Eine nach diesen Maßgaben ‚legitime‘ Bildersuche dürfte dann eine Sache überhaupt nicht machen – nämlich Bilder ohne Kontext anzeigen. Man würde dann bei Google ‚Bild:Auto‘ eingeben, und als Ergebnis Textlinks zu Webseiten erhalten, auf denen Bilder von Autos zu sehen sind. Ob das jetzt so wahnsinnig hilfreich für den Hobbyfotografen ist, der seine Bilder zeigen möchte, das wage ich zu bezweifeln. ;-)
@Dexter
„Theoretisch“ deshalb, weil sich viele einen Dreck um Urheberrechte scheren, nicht zuletzt die Verlage. Und Sie vertauschen die Reihenfolge: Nicht der Urheber muss die Nutzung explizit untersagen, sondern derjenige, der die Inhalte Urheberrechtsrelevant nutzen will muss fragen, ob er das darf. Wenn er sie ohne zu fragen nutzt, macht er das rechtswidrig und kann abgemahnt oder auf Unterlassung verklagt werden. Eine automatische Zustimmung des Urhebers wuerde ich dann sehen, wenn dieser sich fuer einen Dienst anmeldet, wenn also der Urheber aktiv seine Inhalte zur Verwendung hergibt. Wenn Google die die Listung in der Bildersuche in Zukunft also anmeldepflichtig macht, dann sehe ich kein Problem.
Und es gibt ja auch kein grundsaetzliches Problem mit Suchmaschinen, sondern ein Konkretes mit der neuen Darstellungsform der Bildersuche von Google. Und fuer die kritisierte Darstellung ist alleine Google verantwortlich.
Ganz unabhängig von der langen, laufenden Diskussion muss ich auch noch einmal feststellen: mir wird das eingebundene Bild eben nicht in Originalgröße angezeigt. Ich habe hier ein Bild, im Original >2000px hoch. In der Bildsuche wird es mir angezeigt mit einer Höhe von 260px. Die Bildgröße ist damit auf einen kleinen einstelligen Prozentwert des Originals skaliert.
Natürlich werden im Original schon kleine Bilder weniger stark verkleinert, und im Extremfalls vielleicht sogar in Originalgröße angezeigt. Dann ist das aber wiederum bestimmt kein hochqualitatives Bild eines armen Hobbyfotografen.
Auch zu der zu Beginn der Diskussion zitierte Statistik muss ich noch einmal eine Frage stellen: Gibt es neben dem Rückgang in den Seitenaufrufen auch eine Statistik über die gesamten Aufrufe von Einzeldateien? Da die Bilder aus der Originalquelle eingebunden sind, müsste dieser Wert ja konstant geblieben sein. Wenn das so ist, dann würde das die Glaubwürdigkeit erhöhen. Man kann dann trotzdem noch die Frage stellen, ob die Aufrufstatistik für ein aus Text und Bild kombiniertes Dokument relevant ist, wenn der Eigentümer das Bild auch zum getrennten Abruf bereitstellt.
Ich mache es mal kurz.
Die Zeiten von; ich mache mal eine tolle, frei zugängliche Website und verdiene mit Werbung darauf einen Haufen Geld; sind definitiv vorbei. Endgültig.
@204: Was sie machen und was ihr Gewissen dazu sagt ist alleine Ihre Sache. Ich halte auch beileibe nicht alles was illegal ist fuer schlimm oder gar moralisch verwerflich. Ich sage lediglich, dass jemand, der fremde Inhalte nutzt und vor allem veroeffentlicht wie er es braucht, sich nicht wundern muss, wenn ihm eine berechtigte Abmahnung ins Haus flattert. Das gilt natuerlich nicht fuer das blosse Betrachten von Bildern.
@Stefan Niggemeier:
„Ja, man kann das über die robot.txt ausschalten. Lichtschalter, ein, aus, Keese, s.o.“
Nein, dem ist nicht so, nur weil Springer-Lobbyisten das behaupten stimmt es noch lange nicht -.-
Dann sind wir wieder am Kern der Problematik angelangt. Die Gewinnfrage lautet: ist jede Verlinkung einer frei zugänglichen Bilddatei so, dass sie beim Linkempfänger auch direkt als Bild angezeigt wird (also IMG statt A) gleich eine ‚Nutzung‘ des Vermittlers? Ist es darüber hinaus sogar eine ‚Veröffentlichung‘, wenn die originale Datei ja auch schon öffentlich zugänglich ist?
Selten so einen Schwachsinn gelesen.
Sofern nicht gewünscht ist, dass die Bilder von Google eingebunden werden, lässt sich das technisch verhindern. Ob irgendwelche Seiten dadurch weniger Besucher haben ist mir vollkommen egal. Eine Urheberrechtsverletzung findet auch nicht statt.
An Googles Stelle würde ich meine Deutschland-Präsenz schließen und über Google.com ne deutsche UI anbieten, dann erledigen sich auch die nervigen Spießbürger, „Zeitungsverleger“ und internetausdruckende Politiker die eh keinerlei relevante Interessen gegenüber Google vertreten.
Ab viel Spaß mit der Unterschriftenliste…
@alter jakob #205:
Das sich der Inhalteanbieter bei einem Dienstleister „anmelden“ muss, damit dieser der Allgemeinheit eine Dienstleistung mit dessen öffentlichen wie (technisch) zur Verfügung gestellten Daten erbringen kann ist bizarr.
Denken sie das doch mal zu Ende. In ganzer Konsequenz! -> Alle, die etwas im Netz publizieren, müssten die Inhalte bei Verzeichnisdiensten anmelden. Das ist in gewissen Sinne der aktuelle Facebook-Horror in übelster Potenz!
Das Ding ist doch, dass die alte, „unproblematische“ Bildersuche nach konservativer Rechtsauffassung ebenso illegal ist, wie die neue. Nur wird diese eben als akzeptabel geduldet, weil diese heilige PIs bei den Inhalteeinstellern erzeugt. (Ob diese PIs irgendwie produktiv sind ist eine andere Frage).
Recht ist nichts statisches, sondern ist am ehesten der Spiegel dessen, worauf sich die Gesellschaft als akzeptabel geeinigt hat. Es ist etwas, was sich mit den Gegebenheiten ändert. Deshalb ist es ja auch so problematisch, „alte“ Rechtsauffassungen auf ein neues Medium zu übertragen.
(Tip: Nochmal das Feature aus #197. Dort geht es um BTX vs. Internet.)
Wenn jemand „mühevoll“ produzierte Poesie auf Blätter druckt und diese mittels eines Ballons tausendfach über einer Stadt abwirft, die restriktiven „Nutzungsbedingungen“ aber in vogonianisch auf der Rückseite abdruckt, darf er sich dann wundern, wenn diese Inhalte am Tag darauf in der Zeitung abgedruckt werden?
@Fast. Mir ist Ihre Gewinnfrage zu absolut gestellt. So wuerde ich sie mit „Nein“ beantworten. Wie so oft in der Juristerei gilt die Standardphrase „es kommt darauf an“. Denn nur weil zwei das gleiche tun ist es nicht immer das selbe. Daher wuerde ich die Gewinnfrage anders formulieren und das „ist jede …“ aus Ihrer Frage durch ein „kann eine … sein“ ersetzen. Und dann wuerde ich die Frage mit „Ja“ beantworten. Ob das konkret bei Google eine Verletzung ist, darueber kann man streiten.
@alter jakob:
Und wie sollten z.B. Suchmaschinen aus „jeder“ eben diese „einen“ herausfiltern können? Diese müssten ja irgend ein Kriterium an der Hand haben. Oder sollte man sie einfach ganz abschaffen, aslo die Suchmaschinen etc. (= Lösung, wenn es kein Kriterium gibt)?
Der Kommentar davor ging an 210.
@Dexter:
Bei Google News kann man sich auch Anmelden, so bizarr das fuer Sie sein mag. Klar, es werden auch nichtangemeldete News gezeigt, aber Google News in Urheberrechtlich auch eher unproblematisch. Wenn die Suchergebnisse das Urheberrecht verletzen und dem Urheber schaden, dann waere es fuer die Suchmaschine besser, wenn der gelistete den Suchmaschinen-AGB zugestimmt hat. Ich haette aber eine Alternative zu einer Anmeldung: Die Suchergebnisse verletzen kein Recht und/oder der Urheber hat einen Vorteil von der Suche. Dann aergert sich niemand. Ich glaube aber nicht, dass es zu einer Anmeldungsbildersuche kommen wird, denn das waere nur eine Chance fuer die Konkurrenz die Luecke zu fuellen. Ist aber eh egal, weil Google.com sich wahrscheinlich sowieso nicht um deutsches Urheberrecht scheren muss.
Und zu Ihrem Ballonpoeten: ich weiss nicht ob er sich wundern wuerde, in jedem Fall koennte er es aber der Zeitung untersagen sein gedicht zuveroeffentlichen (vielleicht waere er aber auch nur froh endlich gedruckt zu werden). Ich wuerde mich aber wundern, wenn die Zeitung das Gedicht statt einer Story ueber den Poeten und seine Aktion abdrucken wuerde (und das kann er dann natuerlich nicht verbieten).
@215 Dexter: Die Antwort waere eine ganz einfache: Die Suchergebnisse verletzen einfach in keinem Fall das Urheberrecht. Oder das Suchergebnis bringt fuer den Urheber einen Mehrwert. Falls Google aber urheberrechtlich relevante Suchergebnisse (und das sind Bilder im Gegensatz zu Snippets) dazu benutzt um selbst mehr Geld zu verdienen ohne dem Urheber einen Vorteil zu bieten (wenn denn bspw.tatsaechlich die Besucher ausbleiben), tja dann koennte man auch von einem parasitaeren Geschaeftsmodell reden.
Ich merke aber gerade, dass sich Google wirklich einen Baerendienst erweist. Ich bin absolut gegen das LSR, aber erst durch diese Diskussion kann ich das Parasitenargument der Verleger zumindest nachvollziehen. Auch wenn es fuer das LSR immer noch grundfalsch ist, denn dort wird der Traffic ja weitergeleitet weil die Anzeige des Suchergebnisses den gesamten Inhalt nur ahnen laesst.
@214: Verstehe ich nicht ganz. Es gibt ja hier nicht ‚Zwei‘ die etwas tun, sondern nur einen (Google), der das Gleiche (Bilder verlinken) verschiedenen Anderen ‚antut‘. Diese Anderen sind auch nicht wirklich unterscheidbar, alle haben ihre Bilder unter gleichen Voraussetzungen öffentlich verfügbar gemacht.
Darf ich Sie alle mal kurz beim Sich-im-Kreis-Drehen unterbrechen und eine Frage in die Runde werfen?
Mal angenommen, ich schreibe einen Blogeintrag über Google und möchte den mit einem schönen Bild von Eric Schmidt illustrieren. Die FAZ hat ein schönes Bild von Eric Schmidt, das liegt da frei auf der Seite herum. Darf ich mir das nehmen und hier als Schmuck in einen Blogeintrag einbauen? Wenn nein, sollte ich es dürfen? Und macht es einen Unterschied, ob ich das Bild bei der FAZ runter- und hier wieder hochlade oder es einfach direkt von der externen Seite einbinde?
(Ach so, ich würde selbstverständlich die Quelle nennen und mindestens vier Links dorthin zurück setzen.)
Sie unterbrechen also, um dann doch die gleiche Diskussion wieder aufzunehmen. Auch in Ihrem Beispiel ist die zu beantwortende Frage, ob Sie das Bild _nutzen_, oder nur ein frei verfügbares Bild _verlinken_.
Im Zusammenhang mit einem Blogpost über Schmidt würde ich ganz klar von einer Nutzung sprechen. Über die Googlesuche sagt das aber auch nichts aus.
Gute Frage Herr Niggemeier. Ich bin ja in der Werbebranche tätig und kein Jurist. Meine Meinung wäre, dass Sie zuerst die Erlaubnis der FAZ einholen müssten. Begründung: Sie wissen ja nicht, welchen Deal die FAZ mit dem Fotografen, der das Bild geschossen hat, eingegangen ist. Hat der alle Nutzungsrechte an die FAZ abgetreten, so dass die das Bild weiter veräußern darf? Vielleicht will die FAZ das Bild bzw. die Nutzung aber gar nicht „veräußern“ auch wenn es frei rumliegt. Besteht der Fotograf auf eine Nennung der Quelle? Inwieweit sind seine Urheberrechte betroffen usw.
Also, erst die FAZ fragen, die gibt ein OK oder verweist auf den Fotografen, der die Rechte hält. Dann den Fotografen fragen.
@218: Ich denke, ich hatte bereits das „Deep-Linking“ angesprochen, welches bis vor wenigen Jahren noch schwer verpönt war. Vor noch nicht all zu langer Zeit gingen Organisationen wie die EFF (Lawrence Lessig) gegen Urheberrechtsverletzungen vor, als Unternehmen wie Cisco/Linksys Open-Source-Code (GPL) verwendet (verwertet) haben.
Natürlich wird dir jemand antworten, dass die FAZ doch nicht gezwungen wurde, dieses Bild ins Netz zu stellen. Immerhin: was im Internet gelandet ist – auf welchem Weg auch immer – wird automatisch zum Allgemeingut! Genau so hat jedes Unternehmen argumentiert, das unberechtigt Open-Source/GPL-Code in seine Produkte eingebaut hat. EFF und Public Knowledge werden seit ein paar Jahren finanziell von Google unterstützt:
http://www.copyhype.com/2012/12/guest-post-the-net-fail-part-1/
Dazu passend:
http://www.theleftroom.co.uk/?p=2010
http://www.ipi.org/policy_blog/blog_detail.asp?id=1280
@alter Jacob:
Ich finde es nicht bizarr, wenn man sich verzeichnismässig bei solchen Diensten auch anmelden kann, sondern es faktisch müsste.
Die Suchergebnisse verletzen kein Recht und/oder der Urheber hat einen Vorteil von der Suche.
Viel zu schwammig …
Wenn die Suchergebnisse das Urheberrecht verletzen und dem Urheber schaden, dann waere es fuer die Suchmaschine besser, wenn der gelistete den Suchmaschinen-AGB zugestimmt hat.
Sie unterstellen also, dass es auch im Kontext des Netzes sinnvoll wäre, die Rechte nicht implizit durch die reine Zurverfügungstellung (Unterbindung z.B. via robots.txt) einzuräumen, sondern erst durch eine explizite Zustimmung. Ich halte das für überkommen und sehr kontraproduktiv angesichts des neuen Medium. Allzumal sämtliche Rechte der Urheber auch im neuen System gewahrt bleiben können. Hier stehen Nachteile des alten Systems(„explizit“) gegen Vorteile des neuen Systems („implizit“).
Das gegen das Vorteilhaftere trotzdem propagiert wird und das alte System sogar per LSG noch verschärft zementiert werden soll, hat seine Wurzeln schlicht darin, das sich manche (unter dumm-dreister Inkaufnahme handfester gesellschaftlicher Nachteile!) über das alte System plump bereichern wollen.
Manche meinen ja, dass man sich schlecht fühlen soll, wenn man hier (angeblich) für das böse Google Stellung bezieht. Aber wie fühlt man sich wohl, wenn man Springer argumentativ die Stiefel leckt?
So eine kurze Hackeridee:
Vielleicht sollte Google die Anfragen seines Spiders (als „Angebot“ betrachtend) einfach mit einer Art AGB garnieren, die für die Weiterverwendung des Inhaltes gelten, den der Inhaltelieferant daraufhin zurückgibt. Dann weiss der Lieferant Bescheid was mit „seinen Daten“ passieren wird und unter welchen Bedingungen und kann dann auf Annahme oder Ablehnung entscheiden :)
@Stefan Niggemeier:
Was soll die Frage? Du machst das doch! Scrolle mal bitte ganz hoch!
(Sogar auf mehreren Ebenen und ohne Link und Quellenangabe unterm Bild!)
@Dexter: Auf den Hinweis hatte Herr Niggemeier vermutlich schon vor 200 Kommentaren gehofft. ;-)
@Dexter: Die Frage war nicht, ob ich das mache, sondern ob ich das darf. (Würde dabei aber lieber bei meinem gerade gewählten Beispiel bleiben, weil das da oben dann doch, auch wenn Sie das vermutlich nicht so sehen, etwas anderes ist, nämlich ein Zitat.)
@219 Im Kreis drehen
Wenn man mit Google Bilder von Eric Schmidt sucht, ist es schwierig Fotos aus der FAZ zu finden. Die rsten sind auf der community von der FAZ ohne Hinweis auf den Urheber. Das erste Bild in der FAZ ist von der FAZ mit Urheber Christian Thiel benannt. Wenn Sie den mit Google suchen, dann finden Sie, dass das ein Fotograf ist, von dem Sie sich eine Lizenz geben lassen können. Also Bild und Urheber mit Google gefunden.
Wenn Sie es nicht unbedingt darauf anlegen, Werbung für die FAZ zu machen, sondern nur ein Bild von Eric Schmidt brauchen, dann sollte Sie sich z.B. die erste Fundstelle von Google Bilder ansehen. Da finden Sie ein Bild auf Wikipedia. Das ist von Charles Haynes gemacht worden unter kann unter CC-BY-SA-2.0 kostenlos genutzt werden.
Also mit Google Bilder ist es viel einfacher, sich urheberechtskonform zu verhalten als wenn man darauf besteht, Bilder aus der FAZ zu kopieren. Die Urheber werden also mit Google Bilder geschützt vor Bloggern die bei der FAZ kopieren wollen. War es das, was Sie wissen wollten?
(Mit Leuten diskutieren, die auf eine Frage antworten mit „Was soll die Frage?“. Man kann sich seine Kommentatoren nicht aussuchen.)
@Stefan #219: Ich finde das sih im Kreis drehen in diesem speziellen Falle sehr erhellend. Ih habe gute Argumente für beide Seiten gehört.
Zu Deiner Frage: Nein, das solltest Du nicht dürfen. Du machst Dir damit das Bild zu eigen. Du benutzt es, um Deinen Artikel aufzuhübschen. Des Weiteren verdienst Du ja wohl 130 Schrillionen Euro pro Seitenaufruf mit den Stilanzeigen, die ich gerade nicht sehen kann…
Die Google-Bildersuche ist sowohl in der alten als auch in der neuen Variante werbefrei – soviel zum Google macht sich mit Bildersuche die Tasche voll-Argument.
Nebenbei bemerkt: Ich habe seit enigen Tagen immer die nue Bildersuche gesehen, und jetzt ist sie wieder weg.
@Wolfgang Ksoll: Nein, vergessen Sie mal kurz, wie ich das Bild von Eric Schmidt finde. Ich habe einfach ein Schönes auf der Seite der FAZ gesehen, das ich nehmen möchte. Darf ich? Wenn nein, warum darf Google?
@Stefan Niggemeier:
Das mit dem Zitat war mir klar. Sie hätten vielleicht gerne ein „richtiges“ Bild von Eric genommen, aber sie haben diese Krücke genutzt. Nicht zum ersten mal – sie tun das schon selbstverständlich. Darüber würde ich einmal nachdenken.
(Wann wurde das Zitatrecht in der jetzigen Form eigentlich eingeführt? Und warum?)
Aber zu ihrer Frage:
Selbstverständlich dürften sie ein fotokopiertes Bild aus der Print- FAZ nicht für ihr geheimes Samistad-Produkt nutzen. Weil sie die konkreten Nutzungsbedingungen kennen.
Nun kann man – wie Keese & Co. – natürlich argumentieren, dass das in identischer Form auch für alles und jeden (z.B. Suchmaschinen) im Internet zur geltung kommen soll. Und es dabei gleichzeitig zielführend ist, wenn dem Automaten kein maschinenlesbares Kriterium für kopierbar/nichtkopierbar gegeben wird.
@229:
Willkommen in der Urheberrechtsdebatte! ;)
Gute Gelegenheit, das LSRfP zu erwähnen. Meine Meinung: schlecht gemacht, falscher Gegner, viel zu früh. Keese hatte wohl die USA und das DMCA/OCILLA im Sinn, obwohl Safe Harbor und Fair Use in Deutschland derzeit lediglich diskutiert wird. Er ahnt jedoch, dass das irgendwann zwangsläufig auf uns zukommen wird und war mit seinen Bedenken einfach zu voreilig.
Was solche Regelungen bedeuten, sehen wir, wenn wir uns Angebote wie diesen ansehen:
http://toolong-didntread.com/
(Die sind werbefinanziert, wohlgemerkt)
Mit Regelungen, die „Remixing“ erlauben, die Anbietern die Verwertung fremder Werke einen Freifahrtschein ausstellen, wandert das Geld vom Konsumenten nicht mehr zum Urheber sondern zu den Verwertern (Google, Reddit, Imgur, TL;DR, Huffington Post).
Das sind die Bedenken eines Keese, der sie allerdings mangels Überblick nicht in Worte fassen kann. Für ihn ist fälschlicherweise Google (News) der „Gegner“, obwohl er das Grundproblem jedoch richtig erkannt hat.
Zum Begriff „Nutzung“: Google zeigt die Bilder auf der eigenen Suchergebnisseite ohne irgendeine urheberrechtliche Eigenleistung was das Bild angeht. Was wenn nicht anschauen soll denn der Zweck eines Bildes sein? Und wie kommt man darauf, das derjenige, der das Bild zum Anschauen bereitstellt, es nicht nutzen wuerde? Auf den Gedanken bin ich bisher gar nicht gekommen…
@Andreas:
Gibt es nicht schon seit Urzeiten Anbieter, die genau das offline machen, was der Dienst macht? Aktuelle Presse sichten, und ein Excerpt dieser Sichtungen mit Focus auf die Belange des Kunden erstellen und diesem ausliefern?
Ich dachte große Konzerne/Politikerbüros etc. nehmen sowas üblicherweise in Anspruch.
Nutzung erfolgt dann, wenn aus einer Sache ein Mehrwert erzeugt wird.
Der Mehrwert den Google mit der Suche erzeugt, ist die Aufbereitung dieses Materials in eine Übersicht, die konkrete Zusammenstellung nach den Kriterien der Suche.
Nutzt ein Telefonbuch die enthaltenen Telefonnummern?
Nutzt ein LKW die Fracht?
Primär nutzt Google wohl seinen Algorithmus.
@Stefan Niggemeier #231:
Vielleicht beantwortet #236 ihre Frage.
Na aber sicher gibt es das! Gab es schon immer! Nur: es war ein „Konzern“ und ein „Politikerbüro“, die jeweils für diesen Service bezahlt haben. Heute sieht das Verhältnis vollkommen anders aus: unzählige Quellen, ein Aggregator, unzählige Rezipienten. Wer wird bei diesem Spiel gewinnen?
Mit Hilfe des DMCA/OCILLA/Safe Harbor/Fair Use kann ich einen Service in den USA aufbauen, der wiederum die Inhalte von TL;DR verwertet und ihn gegen eine Zahlung von einem Dollar pro Jahr dem Nutzer ohne Werbung anbietet.
Die Ideologie, die aus einer Mischung aus „sharing is caring“ und „remixing“ besteht, bedeutet, dass am Ende keiner mehr weiss, woher eigentlich der Content stammt. Wohin eigentlich das Geld fliessen soll, das man mit diesem gesharten/remixten Content einnimmt.
Das eigentliche Ziel der Konzerne, die zwar Content durchreichen, aber nicht produzieren können.
@198:
„Aber: Google darf nicht einfach meine Bilder benutzen, um damit Geld zu verdienen. “
Nein, natürlich nicht. Wenn’s nach Dir und den anderen Keese-Papageien ginge, müßte Google bei jedem Bild, das es in den Index aufnehmen möchte, erstmal dessen Rechtelage in 200 Ländern der Erde abchecken und dann ’nen Google-Mitarbeiter beim Besitzer des Bilds vorbeischicken, der sich bei Kaffee und Kuchen eine Kopiererlaubnis- oder aber ein -verbot abholt.
Weil Suchmaschinen unter solchen Umständen nicht arbeiten könnten, gibt es die robots.txt, in der der Besitzer des Bilds Google ohne menschlichen Besuch mitteilt, was Google mit den Inhalten der Seite tun darf und was nicht.
Eigentlich ein tolles Konzept, hat auch immer prima funktioniert, bis das Netz von Urheberrechts- Verwerter- und Abmahnanwaltswichsern verseucht wurde, die das Grundprinzip des WWWs entweder nicht verstanden haben oder darauf scheißen.
Eines schönen Tages wird das ganze Gesocks, das nicht müde wird, Diebstahl von Wissensmehrung durch Vervielfältigung zu unterscheiden, vom Blitz erschlagen. Dann gehört das Netz endlich wieder denen, die sich an die ursprünglichen Regeln halten.
Ich freu mich schon.
Dexter: Im Zusammenhang mit dem Urheberrecht ist Ihre Definition aus 236 schlicht falsch. Das Bild wird benutzt, wenn es angezeigt wird und Google benutzt die Bilder um sie dem User zu zeigen (der dann entweder gefunden hat was er will, oder nicht). Das Google zum finden der Bilder einen Algorithmus benutzt ist urheberrechtlich fuer die Nutzung des Bildes irrelevant.
Gleiches gilt bspw. auch fuer eine einfache Zitatsammlung, die sich inhaltlich nicht mit dem Zitat beschaeftigt, sondern nur die Zitate auflistet.
Abschliessend moechte ich im Zusammenhang mit Keese noch darauf hinweisen, dass es einen durchaus relevanten Unterschied zwischen urheberrechtlich geschuetzten Werken und dem vom LSR geplanten Schutzgut gibt.
Gute Nacht allerseits…
@Andreas
Wer wird bei diesem Spiel gewinnen?
Keine Ahnung. Wer soll denn gewinnen?
Aber mal im Ernst:
Wenn diese Excerpte von wenigen große Serviceanbietern für viel Geld an wenige Kunden verkauft werden ist das keine „Ausbeutung“ der Inhalteersteller, aber so wie das von TL;DR & Co. gehandhabt wird schon? Nun, ich kann dieses Argument nicht nachvollziehen.
bedeutet, dass am Ende keiner mehr weiss, woher eigentlich der Content stammt.
Die Angabe woher der Content stammt gehört nicht zum „fair use“?
Wie sie ja richtig dargelegt haben ist die Menge an Information mittlerweile ein Problem. Diesen ordnend aufzuarbeiten ist Mehrwertproduktion.
Sie unterstellen doch auch keinem Zeitungskiosk, dass der er an den Inhalten der Zeitungen verdient, deren attraktive Titelseiten er im Original(!) in sein(!) Schaufenster legt.
Was ich bisher verstanden habe: Bilder direkt von der Quelle einzubinden ist verpönt (unabhängig davon, ob es rechtmäßig ist): man bringt die Seitenbetreiber um Besucher, lässt ihnen aber den Traffic.
Wie verhält es sich aber, wenn ich direkt auf ein Bild verlinke (und nicht auf eine html-Seite mit diesem Bild), oder direkt auf eine pdf-Datei? Beides wird oft gemacht, ist das auch verpönt? Falls nein, warum nicht?
@ Jeff
Um es mit Helmut Berger zu sagen:
Na, jetzt wird er gewöhnlich …
He, ich hab auch noch einen tollen Vergleich, darf ich, darf ich? Danke.
Wenn RTL einen Film ausstrahlt, dann kann ihn jeder kostenlos sehen. Wäre es deshalb okay, wenn Sat.1 die RTL-Ausstrahlung in kompletter Länge zeitgleich auch zeigen würde, ohne Rechte an dem Film zu besitzen? Wäre es legaler wenn sie „Quelle: RTL“ dabei einblenden würden?
@alter jacob:
Sie haben völlig Recht.
In #212 habe ich ja auch schon dargelegt, dass die „alte“ Google Bildersuche nach diesem Urheberrecht wohl illegal ist.
Das Gesetz und die realen Notwendigkeiten/Zustände stehen in dem Fall aber nicht in Einklang. Das ist doch DAS Problem!
Auch im Blogartikel geht es um die aktuelle _Entwicklung_ der Gesetzeslage etc.
In dem Kontext ist meine Antwort bzgl. des Mehrwertes zu sehen.
Die Antwort ist logisch richtig (also wahr), auch wenn sie juristisch interpretiert („auf das Urheberrecht bezogen“) falsch ist.
Gute Nacht!
@redenhalter:
Wäre es legaler wenn sie »Quelle: RTL« dabei einblenden würden?
Nein. Da muss immer „Quelle: Internet“ stehen. So macht das ja auch die ARD – und die muss es wissen, die ist schließlich Staatsfernsehen.
@242:
„Wie verhält es sich aber, wenn ich direkt auf ein Bild verlinke (und nicht auf eine html-Seite mit diesem Bild), oder direkt auf eine pdf-Datei? Beides wird oft gemacht, ist das auch verpönt? Falls nein, warum nicht?“
Google: Paperboy-Urteil
@Jeff:
Das zweite Suchergebnis (bundesgerichtshof) ist ja interessant. Also bzgl. der Darstellung auf der Google-Ergebnisseite:
Aufgrund der robots.txt dieser Website ist keine Beschreibung für dieses Ergebnis verfügbar.
Da macht der Bundesgerichtshof – warum auch immer – Keese & Co. vor, wie das geht …
„Da macht der Bundesgerichtshof — warum auch immer — Keese & Co. vor, wie das geht …“
:)
Jetzt müßten die Keeses dieser Welt nur noch auf den Link „Weitere Informationen“ klicken, dann könnten sie das mit der robots.txt nochmal nachlesen.
Die Hoffnung stirbt zuletzt. Aber sie stirbt.
@Dexter: Es ging mir nicht um ein „fotokopiertes Bild aus der Print– FAZ „, sondern das Foto, das da auf FAZ.net rumsteht. Warum wollen Sie meine schlichten Fragen nicht beantworten, ob ich das hier einfach hochladen und/oder einbinden dürfte und wenn nein, warum nicht?
Darauf hat es nun schon mindestens drei Antwortversuche gegeben. Mag sein, dass Ihnen die nicht zusagen, oder dass sie unvollständig sind. Aber einfach so zu tun als hätte es sie überhaupt nicht gegeben ist schon etwas plump.
@jeff (OT):
Huch! Schau dir mal die robots.txt von denen an.
Ich würde meinen, da hat der Admin was verbockt.
# exclude help system from robots
User-agent: *
Disallow: /
Das Suchergebnis auf Google kommt wohl über einen externen Link.
Seufz
Ein letzter Link noch von mir, bevor ich mich aus dieser kleinen Diskussion verabschiede.
http://www.ethicsscoreboard.com/rb_fallacies.html
@252:
„Das Suchergebnis auf Google kommt wohl über einen externen Link.“
Jep, schaut so aus.
@253:
Das kann ich auch:
http://koelnwiki.de/wiki/Kölner_Grundgesetz
@Stefan Niggemeier:
Weil ich keine Lust habe?
Aber gut:
Natürlich dürfen sie eine digitale Kopie ebensowenig nutzen wie die Fotokopie.
Google darf das in den Artikeln seiner zahlreichen Google-Blogs selbstverständlich ebensowenig.
Ist doch klar.
Eine Suchmaschinenergebnisseite ist aber anders einzuordnen als ein Blogeintrag. Das wissen auch sie und deshalb ist ihre Frage lediglich eine rhetorische. Ebenso wie meine Antwort #232.
Ich verweise im Übrigen nochmal auf #236. Sie kommen jetzt aber nicht mit juristischen Spitzfindigkeiten?
Ich wünschte mir von ihnen eine Spass-Suchmaschine für die Titelseiten von „Neue Welt“, „Gala“ & Co. und fände es nicht verwerflich, wenn sie die Cover dieser Produkte in gewohnter Weise dafür nutzen würden.
@Dexter:
Nein, das weiß ich nicht, und das ist eine zentrale Frage in dieser ganzen Diskussion. Was darf eine Suchmaschinenergebnisseite? Sie sagen: Eine Suchmaschinenseite darf auch urheberrechtlich geschützte Bilder anzeigen. Vollständige Texte auch?
Das Urheberrecht akzeptieren Sie also nicht als Grenze dessen, was eine Suchmaschine darf. Gibt es überhaupt Grenzen? Wer bestimmt sie?
Das sind keine rhetorischen Fragen, sondern Versuche, Ihre Entscheidungskriterien zu verstehen. Ich habe jetzt immerhin verstanden: Sie lehnen das Urheberrecht nicht grundsätzlich, sondern nur für Suchmaschinen ab. Bleibt meine Frage: Warum?
Lesen Sie das Paperboy-Urteil und ersetzen Sie dabei in Gedanken den Begriff ‚Startseite‘ durch ‚Seite, auf der sich das Bild befindet‘ und ‚Beitrag‘ durch ‚Bild‘ – zum Beispiel in den jeweils letzten Absätzen auf den Seiten 11 und 12.
Im ersten Abschnitt wird erklärt, dass es sich für den Suchmaschinenbetreiber maximal um Störerhaftung handeln könnte, da den Abruf der Suchmaschinennutzer vornimmt. Im zweiten Abschnitt wird erklärt, dass es nicht wettbewerbswidrig sei, den Nutzer an Werbung ‚vorbeizuführen‘.
Beides scheint auf die Situation hier sehr gut zuzutreffen. Sie könnten jetzt natürlich argumentieren, dass die vorgeschlagenen Ersetzungen nicht zulässig sind – aber das könnten Sie dann ja vielleicht auch ordentlich begründen.
@231
Wenn Sie ein Bild aus der FAZ nehmen wollen, um es in Ihrem eigenen Blog einzubauen, müssen Sie den Urheber fragen und ggf. für eine Lizenz zahlen.
Wenn ein Kiosk-Besitzer das gleiche Bild in der FAZ auch schön findet und es in seinem Schaufenster ausstellt, damit die Leute, die vorbeikommen, die FAZ kaufen, braucht er keine Lizenz vom Urheber des Fotos zu erwerben, obwohl er das Foto kommerziell nutzt, um Käufer für die Zeitung anzulocken.
Wir haben die Diskussion auch schon beim #LSR gehabt, dass der Taxifahrer nicht dem Bordell-Besitzer eine Vergütung zahlen muss, wenn er Gäste in den Puff fährt.
Google baut nichts als einen Katalog, ohne mit Google Bilde Geld zu verdienen. Da ist nicht mal Werbung bei Google Bilder. Einfach nur ein Katalog. Wie der Kiosk, der die Zeitungen im Schaufenster ausstellt, der mit dem Ausstellen kein Geld verdient und auch nicht die Absicht hat. Google macht den Katalog nur, damit Leute wie Sie die Bilder finden und sich nicht auf die FAZ beschränken müssen.
Es wäre zynisch, von dem Kioskbesitzer wegen des ausgestellten Fotos Geld zu verlangen oder ihn urheberrechtlich zur Verantwortung z ziehen, obwohl er das Bild in kommerziellem Interesse ausstellt, weil er mit dem Verkauf der FAZ Geld verdienen will. Er darf das machen, Sie nicht. So ist da Recht bei uns nach alter Väter Sitte. Für Sie, Google, den Kioskbesitzer. Wo haben Sie da ein Problem mit, was bei uns seit hunderten von Jahren funktioniert?
„Was darf eine Suchmaschinenergebnisseite? Sie sagen: Eine Suchmaschinenseite darf auch urheberrechtlich geschützte Bilder anzeigen. Vollständige Texte auch?“
Das machen Suchmaschinen bereits seit Ewigkeiten:
http://webcache.googleusercontent.com/search?q=cache:3mZ2ULDOm_UJ:www.stefan-niggemeier.de/blog/dreist-und-dumm-die-neue-bildersuche-von-google/
http://web.archive.org/web/20130128033428/http://www.stefan-niggemeier.de/blog/
Nachtrag zu #257: Seite 17, Absatz 2 ist sogar vollkommen ohne Ersetzungen auf die hier diskutierte Situation anwendbar.
@Stefan (#256)
Naja, die angezeigten Thumbnails sind auch urheberrechtlich geschützt und dass diese von einer Suchmaschine angezeigt werden dürfen, wurde gerichtlich festgestellt. Ob das für hochauflösende Bilder genauso gilt, weiß momentan wohl niemand so richtig. Die Frage ist aber schon, wo der rechtliche Unterschied zu sehen sein soll.
Zu deiner ursprünglichen Frage, nach meiner Kenntnis ist es folgendermaßen: einbetten eines Bildes eher nicht ok (da es so wirkt, als mache man sich das Bild zu eigen), einbetten eines Youtube-Videos eher ok (da offensichtlich, dass es eingebettet ist). Ohne Gewähr. ;-)
Dass das erneute Hochladen eines Bildes etwas anderes ist, ist offensichtlich. Und wie schon angemerkt wurde, ist es anscheinend auch im Falle einer Suchmaschine etwas anderes.
Die Funktionalität der neuen Bildersuche könnte man übrigens auch folgenderweise implementieren, garantiert ohne Urheberrechtsverletzung: Die Suchmaschine liefert nur die Links zu den gefundenen Bildern aus, die Visualisierung übernimmt eine lokale Anwendung, z.B. ein Browserplugin.
Die lokale Anwedung könnte natürlich auch eine WebApp sein, die, denkt man das ganze weiter, von Google bei jeder Suchanfrage ausgeliefert werden könnte. Plus eine Liste an Links. Und da wären wir dann wieder in dieser Grauzone.
Auch lustig:
„Das bedeutet, dass die Deutsche Nationalbibliothek ihrem gesetzlichen Auftrag, das deutsche Web für nachfolgende Generationen zu archivieren, nicht nachkommen kann.“
http://www.neunetz.com/2012/06/13/ein-deutsches-archive-org-ist-praktisch-unmoeglich/
@Frank:
Doch doch. Dexter, Jeff, Herr Weierstraß & Co. wissen das 110-prozentig!
„Doch doch. Dexter, Jeff, Herr Weierstraß & Co. wissen das 110-prozentig!“
So läuft das hier. Sobald Du den Gastgeber in Verlegenheit bringst und er merkt, daß er ins Klo gegriffen hat, wird’s gehässig.
Vorbildlich.
@SN
Nein, das weiß ich nicht, und das ist eine zentrale Frage in dieser ganzen Diskussion. Was darf eine Suchmaschinenergebnisseite?
Sie sollte Suchergebnisse übersichtlich anzeigen können. Der primäre Nutzen der Seite sollte sich aus dem „Finden“ der Inhalte und der zugehörigen Quellen ergeben. (Weniger aus der Möglichkeit sofort verwertbare HiRes-Bild-Originale oder Textkopie-PDFs downloaden zu können). Auch sollten die anzeigten Bilder die Seite nicht primär „schmücken“, sondern deren (notwendige!) Darstellung eben das Ergebnis der Dienstleistung bilden.
Vollständige Texte auch?
Wäre der primäre Nutzen der Seite, dass dort vollständige Texte zu lesen sind, würde es sich nicht mehr um eine Suchmaschinenergebnisseite im obigen Sinne handeln.
Ein evtl. vorstellbares Szenario in dem größere Texte(abschnitte) zur Ansicht kommen können sollten, wäre z.B. eine Suchmaschine, die Textvergleiche ausgibt, mit der also Textähnlichkeiten gefunden werden könnten. Sowas ist mir bislang aber (leider) noch nicht untergekommen.
Das Urheberrecht akzeptieren Sie also nicht als Grenze dessen, was eine Suchmaschine darf.
Ich würde eher sagen: Ich halte das bestehende Urheberrecht – soweit ich dieses verstehe und es mit den oben dargelegten Notwendigkeiten kollidiert – für anpassungswürdig.
Gibt es überhaupt Grenzen?
Ehrlich: Was für eine Frage. Herr Niggemeier!
Wer bestimmt sie?
Letztlich (hoffentlich) der Souverän, der sich sein Bild nur über „die Medien“, z.B. Bildzeitung oder auch ihr Blog machen kann.
BTW: Ich finde ihren Artikel ja auch nachvollziehbar und natürlich kann man es dumm von Google nennen, wenn die nun gerade jetzt in den USA die Suche umgestalten, während in Deutschland debattiert wird! Aber mit Blick auf Frankreich muss man leider feststellen: „Was kümmerts die Eiche …“
P.S.
Das mit dem Schalter in ihrem Artikel, also im vorletzten Absatz, ist falsch.
@Wolfgang #258:
Ihre Altvorderen hatten vor 100 Jahren bereits Internet?
Oder meinen sie, es gäbe damals-heute-und-nimmermehr irgendeinen Anpassungsbedarf bestehender Regelungen.
Ich bin in beiden Fällen zutiefst beeindruckt.
@Frank #261:
Ein Bild in einem Browser ist eine technische Ebene weiter unten nichts als eine URI in einem entsprechenden Tag.
Der Browser macht es also schon jetzt faktisch genauso, wie sich das mit dem Link und dem Plugin ausgedacht haben.
Da hat sich doch die jahrelange Lobby-Arbeit gelohnt. Das war der Plan.
Kurz mal zur Abgrenzung:
Das Leistungsschutzrecht wird von Verlegern gefordert. Diese sind in der Regel NICHT identisch mit den Urhebern. Durch Nutzungsverträge, die gerne in einem Ausverkauf der Rechte der Urheber bestehen, erwerben Veröffentlicher Nutzungsrechte an den Werken.
Setzen wir dagegen Bilder-Urheber, die ihr Bild/Foto auf der eigenen Homepage veröffentlichen. Hier werden oft keine Nutzungsrechte für Dritte eingeräumt. Auch professionelle Bilderdienste (z.B. Fotolia) bieten gegen Geld abgestufte Nutzungsrechte.
Nur mal angenommen, ich schreibe in mein Impressum, dass ich – auch Google – keine Nutzungsrechte für meine Bilder ab einer Größe von x * y einräume, dann müßte ich vor jedem deutschen Gericht (evtl. mit Ausnahme Hamburgs) doch mit einer einstweiligen Verfügung gegen Google Deutschland Recht bekommen?
Wenn ich mich nicht täusche, kann ich als Urheber auch beeinflussen, in welchem Zusammenhang meine Werke überhaupt veröffentlicht werden dürfen. Kann ich da nicht auch einfach den Zusammenhang mit der Google-Seite ausschließen?
Ich rede hier nicht von Thumb-Nails, sondern von Bildern in einer relevanten Größe.
Gibt es vielleicht jemanden mit juristischem Hintergrund, der etwas Fundiertes dazu sagen kann?
„Nur mal angenommen, ich schreibe in mein Impressum, dass ich — auch Google — keine Nutzungsrechte für meine Bilder ab einer Größe von x * y einräume, dann müßte ich vor jedem deutschen Gericht (evtl. mit Ausnahme Hamburgs) doch mit einer einstweiligen Verfügung gegen Google Deutschland Recht bekommen?“
Nein, Du wirst verlieren, weil der Google-Imagebot kein Impressum liest, sondern die robots.txt und es ist Deine Aufgabe als Webmaster, die robots.txt anzupassen.
http://www.telemedicus.info/article/1763-Die-Thumbnail-Entscheidung-des-BGH-im-Detail.html
„Die Bejahung einer Einwilligung in die Rechtsverletzung stützt der BGH zum einen auf die von der Klägerin vorgenommene Suchmaschinenoptimierung und zum anderen auf das Unterlassen der Klägerin, Google durch Modifizierung der „robots.txt-Datei” an der Indizierung der Bilder zu hindern:“
„Daraus ergibt sich ohne weiteres, dass das Verhalten der Klägerin, den Inhalt ihrer Internetseite für den Zugriff durch Suchmaschine zugänglich zu machen, ohne von technischen Möglichkeiten Gebrauch zu machen, um die Abbildungen ihrer Werke von der Suche und der Anzeige durch Bildersuchmaschinen in Form von Vorschaubildern auszunehmen, aus der Sicht der Beklagten als Betreiberin einer Suchmaschine objektiv als Einverständnis damit verstanden werden konnte, dass Abbildungen der Werke der Klägerin in dem bei der Bildersuche üblichen Umfang genutzt werden dürfen. Ein Berechtigter, der Texte oder Bilder im Internet ohne Einschränkungen frei zugänglich macht, muss mit den nach den Umständen üblichen Nutzungshandlungen rechnen (vgl. BGH, Urt. v. 6.12.2007 – I ZR 94/05, GRUR 2008, 245 Tz. 27 = WRP 2008, 367 – Drucker und Plotter).”
Mittlerweile gibt es die neue Bildersuche auch in Deutschland.
Als Anwender finde ich sie sehr praktisch. Als Webseitenbetreiber werde ich mich einrichten müssen.
Ich halte mich weiterhin an den alten Grundsatz:
Wenn du ein Bild ins Internet stellst, musst du davon ausgehen, dass du keine Kontrolle mehr darüber haben wirst. Das ist (leider) keine Neuigkeit.
Da der Hausherr auch alle Fragen siebenmal stellt und nicht gefallende Antworten ignoriert, mach ich das jetzt auch mal.
Wenn ich ein Bild in einer bestimmten Auflösung ohne eine der zahllosen möglichen Arten der Zugangssicherung auf meine Seite stelle, könnte man dann sagen, dass ich dieses Bild „veröffentliche“? Und wenn ich ein Bild „veröffentliche“, muss ich dann damit rechnen, dass es öffentlich verfügbar, nutzbar (d.h. in diesem Fall „ansehbar“) wird? Und wenn ich eine einfache Möglichkeit habe, bestimmte Nutzungen (z.B. durch Suchmaschinen) auszuschließen, das aber nicht tue, weil ich ja doch gerne von der Suchmaschine profitieren möchte, kann ich mich dann über die Nutzung beschweren, die ich ja implizit erlaubt habe? WAS GENAU spricht dagegen, dass es logischerweise der Rechteinhaber sein muss, der auf maschinenlesbare Art und Weise der Maschine mitteilt, was mit dem Bild geschehen darf und was nicht? Weil es nicht in die Argumentation passt.
Mit Verlaub: Niggemeier argumentiert hier haargenau auf der Schiene, gegen die er seit Monaten anschreibt. Und ich glaube, das hat er mittlerweile auch gemerkt, daher die Garstigkeit in einigen Kommentaren.
@ S. Niggemeier
Sie werden auf konkrete Fragen zu diesem Thema von diesen Usern keine konkrete Antwort erhalten, weil diese User in dieser Diskussion nur ein „Argument“ kennen: robots.txt. Dann ists auch schon vorbei. Es kann sie auch nicht selber betreffen, denn sobald dieser Fall eintreten sollte, werden die eigenen Positionen schneller über Bord geworfen als man Leistungsschutzrecht überhaupt aussprechen kann. Siehe Julia Schramm.
Im Ergebnis muss man eben um sein Recht, seine Möglichkeiten und um Mehrheiten kämpfen, sonst geht das Licht aus.
@ Maik K.
„Mittlerweile gibt es die neue Bildersuche auch in Deutschland.“
Auch wieder ein Beitrag, nach dessen ersten Satz man getrost abschalten kann…
Aus einem meiner anderen Kommentare:
Und sich dann wundern, warum man vom „rechtsfreien Raum Internet“ spricht. Wir befinden uns wohl derzeit erst im Spätmittelalter des Internets:
http://de.wikipedia.org/wiki/Geschichte_des_Urheberrechts#Sp.C3.A4tmittelalter
@257, Stefan Weierstraß, Jeff, Paperboy-Urteil (PU)
Das ist natürlich eie grandiose Idee.Genauso kann man in Anlage II zum Waffengesetz Abschnitt 2, Unterabschnitt 2, 1.1 Erlaubnisfreier Erwerb und Besitz einfach den Begriff „Druckluftwaffe“ durch „Raketenwerfer“ ersetzen und schon kann ich mir eine Stalinorgel in den Vorgarten stellen.
http://www.gesetze-im-internet.de/waffg_2002/anlage_2_82.html
Nein, im Ernst, das PU greift hier nicht. Es reicht ein urheberrechtlicher Begriff um das ganze Paperboy-Kartenhaus in dieser Diskussion einstürzen zu lassen: Schöpfungshöhe. Die fehlt bei den hyperlinks im PU, ist bei Google aber zweifelsfrei gegeben.
Ich erläutere das jetzt nur kurz, kann aber später mehr dazu schreiben. Im PU wird das Urheberrecht gar nicht großartig diskutiert. Denn wie auf Seite 11 erster Absatz im PU steht, wurde von der Klägerseite überhaupt nicht vorgetragen, wie der Dienst Paperboy das Urheberrecht verletzen soll. Denn es werden auf der Suchseite ja nur Snippets gezeigt, die das Urheberrecht idR aber gar nicht verletzen. Deshalb ist die für die Bildersuche von Google relevante Urheberverletzung im PU gar nicht lang diskutiert, sondern nur kurz verneint. Und deshalb hatten die Kläger auch keinen Unterlassungsanspruch aus dem UrhG.
Zu Seite 17, Absatz 2: Da sagt der BGH lediglich, dass das Setzen von Hyperlinks im grundsätzlich zu Dulden ist und solche Links auch an der Startseite (auf der die Werbung platziert war) vorbeiführen können. Das bedeutet aber nur, dass jemand es Dulden muss, dass auf jede seiner (!) Seiten verlinkt werden kann, solange er die Seite (und den Inhalt) frei zugänglich macht. Das ist keine Überraschung, heisst aber nicht, dass die Suchseite den Inhalt komplett zeigen darf oder die Deep-Link-Seite beliebig verändern kann.
Der Unterschied ist also, dass der Dienst Paperboy Hyperlinks mit Textschnipseln gezeigt hat und den Nutzer dann an der Startseite vorbei direkt zum jeweiligen Artikel geführt hat, der dann auf dem Rechner des Nutzers angezeigt wurde (aber im Umfeld der jeweiligen Zielseite). Dass ein Artikel, wenn er frei im Netz zugänglich ist, natürlich in den PC geladen wird, der auf die Zielseite gelenkt wird, kann man aber nicht dem Lenker/Vermittler ankreiden und stellt auch keine Verfielfältigung dar, denn wenn man den Artikel überhaupt lesen will, muss er ja geladen werden. Er wird aber erst dann geladen, wenn der Nutzer die Zielseite erreicht und nicht schon auf der Suchseite. Paperboy hat aber keine urheberrechtlich relevanten Inhalte in der Suche veröffentlicht und hat auch nicht die Zielseite verändert angezeigt.
Google hingegen veröffentlicht urheberrechtlich geschütztes Material. Das das Urheberrechtlich geschützte Material mit einem Deep-Link versehen ist, macht aber die Veröffentlichung nicht zulässig. Denn genau das ist der Unterschied zum PU.
Es wird eigentlich alles ganz einfach, wenn man die richtigen Begriffe verwendet. Ich habe hier in meinen Kommentaren auch fälschlicherweise den Begriff „Deeplinking“ und nicht den passenderen Begriff „Hotlinking“ verwendet. Das Paperboy-Urteil behandelt das Thema „Deeplinking“ (an der Startseite vorbei), aber im Fall der neuen Google-Bildersuche geht es eben um das „Hotlinking“.
Hotlinking ist oftmals auch gleichzeitig ein Deeplinking.
Rechtliche Situation:
http://de.wikipedia.org/wiki/Hotlinking
Und hier haben wir es dann noch mal ganz konkret:
http://www.heise.de/newsticker/meldung/Framing-eines-Fotos-verletzt-Urheberrechte-138167.html
Damit wäre alles geklärt, oder? Ich denke, es wird keine Rolle spielen, ob es nun mit Hilfe eines Frames oder sonst irgendwie implementiert wurde.
Ja, Herr Niggemeier, man kann auch die Teilnahme eines Kommentators an einer Diskussion ausbremsen, wenn einem die Argumente nicht passen . Das „Hausrecht“ erlaubt dies und vieles andere. Stil hat es nicht.
Interessant fände ich, wie diejenigen, die Google hier Veröffentlichung fremder Inhalte vorwerfen, das Wort „veröffentlichen“ definieren: „Etwas, das jemand anders bereits explizit für eine unbegrenzt große Zahl an Nutzer öffentlich gemacht hat, für mehr Leute auffindbar machen“ ist doch nicht veröffentlichen? Bedeutet „veröffentlichen“ nicht, dass etwas vorher nicht öffentlich war?
@272:
„Nein, im Ernst, das PU greift hier nicht.“
Das entscheidende BGH-Urteil ist nicht das PU aus 2003, sondern das TU aus 2010, in dem die Mitwirkungspflicht des Webmasters – robots.txt – in Stein gemeißelt wurde. => @269
Trinken Sie doch erstmal ’ne Tasse Kaffee und schieben Sie auch dem Herrn Roedl einen rüber, der Tag ist noch lang.
Vielleicht bin ich nur dumm, aber sicher nicht dreist! Ich möchte einfach nur wissen, wie ich das ABO zu all dem Unsinn betr. „Google Bildersuche“ abschalten kann …
@276:
Aus meinem Kommentar 275:
Für Leute wie Dich vorsichtshalber noch mal an einem Beispiel erklärt: wenn ich mit meinem unveröffentlichten Manuskript zu einem Verlag gehe, der das Buch dann veröffentlicht, dann ist es auch für alle zugänglich. Wenn Du dieses veröffentlichte Buch nimmst und es nochmals veröffentlichst, verstösst Du gegen das Urheberrecht. Du darfst nichts veröffentlichen, woran du keine Rechte hast. Egal, ob es bereits veröffentlicht wurde, oder nicht. Ganz simpel. Basics des Urheberrechts…
Aber wie gesagt: siehe Kommentar 275.
Einen hab ich noch:
Möglicherweise muss man bei Analogien aufpassen. Bei Google ist kein Mensch, der mit Vorsatz widerrechtlich ein Bild von Eric Schmidt bei der FAZ kopiert und es mit festem Willen in eine eigene Seite einbaut, wie es Stefan Niggemeier vorgeschlagen hat. Bei Google ist eine Maschine, die aus im Internet veröffentlichten, frei zugänglichen Bildern einen Katalog herstellt. Bei einer Bibliothek ist der Katalog nicht Gegenstand urheberrechtlicher Betrachtungen. Stefan Niggemeier hat offenbar Probleme, technische und rechtliche Sachverhalte auseinander zu halten. Deshalb ein weiteres Beispiel, wo technische identische Sachverhalte rechtlich völlig unterschiedlich gedeutet werden.
Nehmen wir ein Diensteangebot nach dem Telemediengesetz. Irgendwo kann ein Dienstenutzer einen Text eingeben, z.B. einen Kommentar wie diesen hier. Der Nutzer gibt gibt einen Text ein, er wird veröffentlicht, wahrscheinlich hat er kein Urheberrecht darauf wegen der geringen Schöpfungshöhe, aber er muss sich rechtlich dafür verantworten. Der Betreiber der Plattform hat keine Haftung für den Inhalt und muss erst bei Kenntnisnahme eines Gesetzesverstosses möglicherweise eingreifen.
Anders dagegen verhält es sich, wenn der selbe Text (ohne ein Jota Änderung) als Kommentar bei einer Online-Zeitung eingeht, wo (meist juristische Laien) als Vorzensoren (von den Zeitungen verachtend Community-Manager genannt) den Text begutachten und dann ihn veröffentlichen oder nicht. Die juristischen Laien machen dann kurzen, berufen sich oft auf das Strafrecht (z.B. Beleidigung), meiden aber Strafgerichte und rauben dem Beschuldigten rechtliches Gehör. Als Strafe für diese Anmaßung gehen sie in volle Haftung für den Text. Sollten darin strafbare Handlungen sein, können sie wegen Beihilfe mitbestraft werden.
Notabene: bei identischem Text völlig unterschiedliche Folgen. Macht die Maschine das alleine, keine Haftung. Mischen Menschen mit freiem Willen mit, wenn auch als bezahlte Lohnzensoren, sieht es völlig anders aus. So eben auch, wenn Stefan Niggemeier sich mit Vorsatz, ohne sich um Urheberrechte zu kümmern, ein Bild kopiert und bei sich im Blog nutzt.
(Wobei noch hinzukommt, dass es ihm in dem gewählten Beispiel nicht darum geht, ein Bild von Eric Schmidt nutzen zu dürfen, die es ja auch zur kostenlosen, unproblematischen Nutzung gibt und Google es einfach macht, diese zu finden, sondern er darauf beharrt, eines aus der FAZ zu nehmen, wo der Urheber bekannt ist, den man um Lizenz fragen muss, also es um Vorsatz geht.)
@278:
Im Zweifelsfall klickst Du auf den Link am Ende der Abo-Mail…
@257: full of win!
@274: Danke. Hab herzlich gelacht.
@275: Schön, daß hier mal meiner die ganzen Urheberrechtsundinterneterklärungsmaschinen a la Dexter aufklären möchte, daß das „Paperboy-Urteil“ – mit dem die hier in einer Aufregung hausieren gehen, als hätten sie das gerade zum ersten mal gelesen – nichts mit dem ganzen Kram hier zu tun hat. Das werden die aber nicht einsehen, weil.
@277
wieso sollte das in Stein gemeißelt sein. Die Umstände haben sich doch geändert; viele sagen, Grenzen wurden überschritten. Warum sollte nicht mit einer geänderten Rechtsprechnung darauf reagiert werden?
Außerdem reden wir ja nicht von Webmastern sondern von schöpferisch Tätigen/Künstlern. Die werden auch gerne als etwas weltfremd betrachtet. Sollen die jetzt in einem Kurs über robots.txt, .htacess und .htpasswd besuchen?
Kann man das denn einfach so einstellen, wenn man z.B. einen Homepagebaukasten von 1und1 benutzt. Oder ist dann der „Webmaster“ von 1und1 in der Pflicht, wenn gewünscht, des Künstlers Werke vor Google zu schützen?
@274/@275: Ihre Interpretation wäre in ihrer Absolutheit sicher auch noch mal durch ein Gericht zu überprüfen. Das Wesentliche ist aber doch, dass das Urteil genau das Argument ausser Kraft setzt, das Herr Niggemeier in seinem Beitrag nutzt.
Stellen Sie sich eine Ergebnisseite vor, auf der meinetwegen auf das Hotlinking, nicht aber auf das Deeplinking, verzichtet wird. Das erlaubte Thumbnail bildet dabei einen Hyperlink auf das Originalbild.
Das dürfte dann wohl auf jeden Fall erlaubt sein (s.o.), nützlicher ist es aber nicht. Weder für den Suchenden, noch für den Anbieter, der immer noch seinem Werbepfennig hinterher weint.
Diese Ausgangssituation kann man jetzt ausbauen: das Originalbild könnte nach Klick in einem Frame der Suchseite angezeigt werden statt in einem neuen Tab, oder ein clientseitiges Script könnte die eine Art eines Hyperlinks (A) durch die andere (IMG) ersetzen. In Kombination nähert man sich der kritisierten Ergebnispräsentation wieder stark an, wobei alle durch den Nutzer ausgeführten Einzelaktionen erlaubt bleiben.
„Sollen die jetzt in einem Kurs über robots.txt, .htacess und .htpasswd besuchen?“
Sie finden es zu viel verlangt, dass jemand, der Sachen im Web veröffentlichen will und in bezug auf die Behandlung durch Suchmaschinen Sonderwünsche hat, lernt, diese zu artikulieren?
@kasuppke / 285
Und meine zweite Frage mit Homepagebaukasten?
Und ja, ich finde es ist zuviel verlangt. Den meisten geht es nicht um die Webseite als HTML-Konstrukt, sondern darum Inhalte zu veröffentlichen. Dafür gibt es heutzutage Contentmanagement-Systeme, die gerade keine weitergehenden Kenntnisse erfordern.
@Jeff
Danke, Kaffee getrunken, Thumbnail Urteil gelesen. Immer noch meiner Meinung. Es würde helfen, wenn man die Urteile ganz liest und im Zusammenhang mit dem bringt, was nun Realität ist.
Auch hier gibt es einen entscheidenden Unterschied: Das Urteil bezieht sich auf die Bildersuche, die damals üblich war. Der BGH erklärt die konkludente Einwilligung in die Rechtsverletzung, die durch die bei der Bildersuche üblichen Vorschaubilder entsteht. Die neue Bildersuche bei Google hat aber nicht nur Vorschaubilder, sondern zeigt auch eine Option „Originalbild anzeigen“. Siehe Google.co.uk (nicht erschrecken):
http://www.google.co.uk/search?hl=de&site=imghp&tbm=isch&source=hp&biw=1024&bih=625&q=fotos&oq=fotos&gs_l=img.3..0l10.5579.6467.0.6628.5.4.0.1.1.0.191.593.0j4.4.0…0.0…1ac.1.2.img.ZtBa5RoEB9Y#imgrc=VELI7g6hkBADHM%3A%3B7c1-m7KxNW8ViM%3Bhttp%253A%252F%252Fmundolouco.net%252Fwp-content%252Fuploads%252F2013%252F01%252FFotos-bizarras-de-pessoas-tiradas-no-momento-da-prisao-4.jpg%3Bhttp%253A%252F%252Fmundolouco.net%252Ffotos-bizarras-de-pessoas-tiradas-no-momento-da-prisao%252F%3B620%3B607
Wenn man darauf klickt, dann erscheint das Originalbild ohne auf die entsprechende Seite desjenigen zu gelangen, der das Bild bereitstellt. Damit hat Goolge die Bildersuche verlassen und zeigt eben nicht suchmaschinenübliche Vorschaubilder, sondern Google veröffentlicht das Orignalbild.
Darüber hat der BGH nocht entschieden und ich kann mir nicht vorstellen, dass die Konstruktion der konkludenten Einwilligung in eine Rechtsverletzung für Vorschaubilder auch für das Orignalwerk gilt. Oder anders gesagt, der BGH hat sich damals mit folgendem Tatbestand auseinandergesetzt:
Nun ist die entsprechende Abbildung nicht mehr nur durch den Verweis auf die das Orignalbild enthaltende Internetseite zu sehen, sondern bei Google: Goolge ist bei der Abbildung des Orignalbildes nur noch Rechtsverletzer und kein Bereitsteller von Vorschaubildern.
Dann ist es doch Aufgabe der CMS-Hersteller, solche Funktionen einzubauen, falls sie vom Kunden gefordert werden.
Ich habe einmal in eine veraltete Installation einer Coppermine-Bildergalerie reingeschaut. Dort werden Bilddateien in verschiedenen Größen mit verschiedenen Präfixen (thumb, klein, normal, original) gespeichert. Es sollte ein Leichtes sein, statt Präfixen Unterordner zu nutzen, so dass dann nur die Originale mittels robots.txt-Aussperrung nicht in der Bildersuche auftauchen.
Aber das Prinzip hatten wir ja vor 150 Kommentaren auch schon mal. :-)
@Chico:
Der Fotograf sollte sich schon informieren, was zu beachten ist, wenn er seine Werke in Medium x selbst veröffentlicht.
Man muss aber dazusagen, dass der Fotograf sicher das kleinste Problem damit hätte, wenn Google seine Fotos unter seinem Namen auffindbar macht.
Probleme entstehen ja eher durch/für Lizenznehmer seiner Fotos, deren Kopien seiner Fotos dann unter _deren_ Namen bei Google gelistet werden – weil diese gerne die Klicks dafür von Google kassieren möchten.
Bilder im Netz sollten Urheberinformationen in sich tragen. Würde sich die Webgemeinschaft darauf einigen können, wäre die Welt besser.
@Stefan Niggemeier:
Das mit der HQ-Bildervorschau finde ich auch unlauter. Google sollte darauf verzichten oder diese von der Bildquelle aus leicht steuerbar machen. Und ja, es ist die Frage: Wo zieht man die (automatische) Grenze. Ich weiss es nicht.
@Peter Marteau
Ich habe weder was zum Paperboy-Urteil geschrieben, noch habe ich das Urheberrecht erklärt!
@287: Den direkten Link zum Bild gibt es in der alten Suche doch auch schon. Dieser Link war bis jetzt auch gar nicht Thema der Diskussion, sondern nur das direkt angezeigte Bild daneben.
Ergänzung zu #287:
Der Punkt ist: Nur weil man gefunden werden will und man dafür die Vorschaubilder einer Bildersuche akzeptieren muss, heisst das noch lange nicht dass es der Suchmaschine erlaubt ist die Bilder über das in der Suche notwendige hinaus zu Veröffentlichen.
@Stefan Weierstraß #284:
Meine Interpretation wird ziemlich deutlich auch im Thumbnail Urteil bestätigt. Da werden die Vorschaubilder in der Suche grundsätzlich als rechtsverletzend angesehen.
Und inwiefern das PU dei Argumentation von Herrn Niggemeier widerlegt, wenn das PU auf den konkreten Fall von Google nicht anwendbar ist, dass muss ich noch einmal erklärt bekommen…
@Dexter:
Aber exakt das ist doch der Kern meiner Kritik!
@290:
Der Link zum Originalbild führt nicht auf die Seite, auf der das Originalbild zu sehen ist, sondern zeigt das Originalbild ohne auf die Seite zu führen, auf der das Bild gefunden wurde.
Wenn ich dagegen bei google.de auf ein Foto klicke, komme ich zur Fundstelle.
http://www.google.de/search?hl=de&site=imghp&tbm=isch&source=hp&biw=1024&bih=625&q=fotos&oq=fotos&gs_l=img.3..0l10.964.1550.0.1813.5.5.0.0.0.0.152.582.1j4.5.0…0.0…1ac.1.2.img.fENdTRPyi5E
@293: In der alten Suche gelange ich nach Klick auf ein Vorschaubild zunächst auf eine weitere Seite von Google, auf der die Zielseite in einem Frame eingebunden (erlaubt? Nicht erlaubt?) ist und mir im rechten Frame ein direkter Link zum Bild geboten wird. Die Funktion ‚Bild ohne Kontext anzeigen‘ war vorher also auch schon vorhanden.
@Stefan Niggemeier:
Ein weiterer zentraler (ähemm) Eckpfosten ihrer Kritik ist, dass die Anzeige der Originalseite jetzt nicht mehr im Googlekontext erfolgt. Das finde ich wiederum nicht schlimm. Auch den Deeplink finde ich hinnehmbar, wenn auch grenzwertig.
@294: Keine Ahnung ob erlaubt oder nicht, zumindest sehe ich die Originalseite. Bei goolge.co.uk wird es aber eh nicht so gemacht. Und dass das Bild ohne Kontext erlaubt ist, glaube ich nicht. Aber darüber hat ja noch niemand entschieden.
Was ich als das Hauptproblem bei der Bildersuche ansehe ist, dass das Suchergebnis idR gleichzeitig das ist, was der Suchende eigentlich sehen wollte. Es gibt dann, anders als bei Textschnipseln, die nur eine Ahnung vom Text ermöglichen, keine Notwendigkeit mehr auf die Zielseite des Urhebers zu gehen. Die folge ist, dass die Bilder bei Google gefunden werden und nicht bei den Urhebern, Google also fremde Schöpfungen selbst bereitstellt und nicht mehr nur zum Zweck der Vermittlung anzeigt.
@296: Wenn man Ihrer Interpretation folgt, dass jedes Verlinken mittels IMG statt mit A gleich ein eigenes ‚Bereitstellen‘ darstellt, dann ja. Wenn die Vermittlungstätigkeit von Google schon auf der ersten Variante der Ergebnisseite endet (also bevor der Nutzer mittels Klick selbst tätig wird und den Iframe mit Bild überhaupt erst zur Anzeige bringt), dann nicht. Ist das so? PU/TU/Hot-&Deeplinking/Ja/Nein/Vielleicht/…, darum geht es ja hier schon in ewigen Kreisen, ohne dass der Eine den Anderen überzeugen kann.
Was bleibt ist immer noch die Tatsache, dass sehr wohl eine legale (und meiner Meinung nach auch legitime) Ergebnispräsentation denkbar ist, die den Bildeigentümer trotzdem noch um die Anzeige seiner Seite bringt – und das diese legale Präsentation nicht soo wahnsinnig weit von der Tatsächlichen ist, wie einige hier behaupten.
Deswegen sollte es nach wie vor im Interesse des Bildeigentümers liegen, sein schützenswertes Eigentum vor Zugriff (oder bestimmten Zugriffsarten) zu schützen. Tut er das nicht, muss er mit den Konsequenzen leben.
Ich stimme zu, dass der Bildeigentümer sich natürlich auch selbst kümmern muss. Wer seine Bilder nicht in der Google-Suche haben will, der kann (und muss ja auch) die robots.txt benutzen. Nur weil man aber gefunden werden will, kann das doch nicht bedeuten, dass einzelnen oder allen Suchmaschinen die Einwilligung für beliebige Rechtsverletzungen der Suchmaschine gegeben wird. Dann gibt es bald den ersten Google-Fotoband mit Bildern aus der Websuche.
Auch wenn mein Beitrag in der Flut an Kommentaren vermutlich untergehen wird, möchte ich ein Argument von einem rein technischen/vernunftbasierten(?) Standpunkt aus einwerfen.
Eigentlich liegt es im Interesse der Allgemeinheit, unnötigen Traffic im Internet zu minimieren. Das spart Ressourcen jeglicher Art. Und genau das erreicht die neue Bildersuche.
Dass sich durch unnötigen Traffic bisher Geld verdienen ließ, halte ich nicht für einen schützenswerten Zustand.
Ganz klar: Jeder hat das Recht, mit seinen *Inhalten* Geld zu verdienen! Aber mit den Inhalten sinnloses Datenaufkommen zu provozieren, nur um davon über Werbeeinblendungen jedweder Art zu profitieren, erscheint mir zweifelhaft.
Wieso wird eigentlich in dem Zusammenhang nicht auch über das Caching von *kompletten* Webseiten geklagt? Auch das ist technisch sehr sinnvoll. Aus ökonomischer Sicht aber wäre es wiederum dreister Diebstahl, oder nicht?
Zum Beispiel hier: https://webcache.googleusercontent.com/search?q=cache:3mZ2ULDOm_UJ:www.stefan-niggemeier.de/blog/dreist-und-dumm-die-neue-bildersuche-von-google/+&cd=1&hl=en&ct=clnk&gl=de
@298: Einmal abgesehen davon, dass wir uns über das Vorhandensein einer Rechtsverletzung in diesem Fall ja noch gar nicht einig geworden sind, ist es natürlich nicht so, dass ein Rechteeigentümer ‚beliebige‘ Rechtsverletzungen in der Zukunft zulassen soll oder muss.
Das Problem hierbei ist dann aber nicht Google, sondern die existierende Granularität, mit der im Netz Rechte vergeben (oder meinetwegen deren Einhaltung ‚erzwungen‘) werden können. Wenn Sie tatsächlich fordern wollen, dass die Rechtevergabe in beliebiger Feinheit darstellbar ist (‚diese Suchmaschine ja, aber nicht die andere‘, ‚verlinken ja, aber nicht darstellen‘, ‚darstellen ja, aber nur verkleinert‘), dann landet man irgendwann bei einer Keeseschen Rechtesprache fürs Internet. Dann sind wir aber nicht mehr an dem Punkt, an dem wir über das ‚dreiste‘ oder ‚dumme‘ Verhalten eines einzelnen Anbieters sprechen müssten.
@111, Andreas Roedl:
„Die Google-User sind glücklicher als zuvor, die Website-Betreiber sind sehr viel unglicher als zuvor. Mehr muss man über dieses Thema nicht wissen.“
Wenn es sich tatsächlich darauf reduzieren ließe, wäre die Abwägung der Interessen allerdings sehr einfach:
Es gibt also weit mehr Menschen, die von der neuen Bildersuche profitieren, als solche, die Schaden erleiden.
Nur (leider, wie ich finde) wird in unserer Gesellschaft alles mit Geld bemessen. Glücklich/unglich[sic] spielt da keine echte Rolle. Auch der Begriff „Nutzen“ erfährt dabei oft einen merkwürdigen Begriffswandel (siehe mein voriger Post #299).
@alter Jacob:
Ich finde, sie haben das Dilemma in #296 gut umschrieben.
Zu #298 ist vielleicht anzumerken, dass sich natürlich in dem Spiel nicht nur der Fotograf verantwortlich zeigen muss, sondern auch die Suchmaschine (Was sie ja auch -noch- tut, es gibt ja noch kein Google-Fotoalbum)
Ein Problem ist, dass Anbieter von „originären“ Bildern (Fotografen, Stockphoto-Anbieter etc.) wohl gar nicht mal so sehr über die neue Bildersuche ärgern werden. Es sind eher die Leute, die Bilder sekundär nutzen, z.B. als Schmuck ihrer Presse-/Blogartikel. Wobei da die Frage aufgeworfen wird, ob es überhaupt legitim ist, ein für einen Artikel lizenziertes Bild zur Werbung für den Artikel in eine Bildersuchmaschine aufnehmen zu lassen. Ich weiss, das klingt verkehrt herum – ist es aber nicht. Das läuft letztlich wiederum auf diese Opt-In oder Opt-Out-Geschichte hinaus. (Ich hoffe das ist nachvollziehbar)
Man bedenke dabei: Ein Opt-In würde bedeuten, dass neue Suchanbieter keine Chancen hätten.
#300: Ob wir uns einig sind, das ist ja sowieso unerheblich. Die bisherige Rechtsprechung hat jedenfalls festgestellt, dass schon die kleinen Vorschaubilder eine Rechtsverletzung darstellen (Thumbnail-Urteil). Nur konnte diese aufgrund der angenommenen impliziten Einwilligung der Klägerin nicht verfolgt werden.
Ich bin auch gar nicht gegen eine Bildersuche allgemein. Man muss bei Suchmaschinen aber aufpassen, dass die Urheberrechte nicht komplett auf der Strecke bleiben. Ich habe das Gefühl, dass Google nach dem TN-Urteil die Rechtsverletzung sukzessive ausgebaut hätte. Beweisen kann ich das aber nicht, weil ich das dem TN-Urteil zugrunde liegende Suchseitenlayout nicht finde.
@299 TM: Den Einwand mit dem Google-Cache finde ich ziemlich interessant. Möglicherweise, weil man gezielt nach Cache-einträgen suchen muss und es den Rechteinhabern bisher egal war?
@303: Wenn man voraussetzt, dass so etwas wie eine ‚implizite Einwilligung‘ existiert und Gültigkeit hat, dann ist eine ‚Rechtsverletzung in die der Rechtseigentümer eingewilligt hat‘ doch (zumindest pragmatisch im normalen Sprachgebrauch außerhalb von juristischen Spitzfindigkeiten) keine wirkliche Rechtsverletzung mehr.
Das sieht man auch daran, dass zwar im Urteil etwas von ‚Einwilligung in rechtsverletzende Handlung‘ steht, die dazugehörige Pressemitteilung das aber mit ‚Keine Urheberrechtsverletzung bei Bildersuche in Google‘ ins Normaldeutsche übersetzt.
Meinetwegen formulieren wir ab sofort anders und sagen stattdessen: ‚Google begeht eine Rechtsverletzung, hat aber die pauschale Erlaubnis dazu‘ – im Ergebnis ändert sich dadurch nichts.
@219 Stefan Niggemeier:
„Die FAZ hat ein schönes Bild von Eric Schmidt, das liegt da frei auf der Seite herum. Darf ich mir das nehmen und hier als Schmuck in einen Blogeintrag einbauen? Wenn nein, sollte ich es dürfen?“
Natürlich sollten Sie das dürfen. Erstens ist die Schöpfungshöhe lächerlich gering, denn es handelt sich um ein bloßes Abbild der Realität. Jeder, der Eric Schmidt gegenübersitzt, sieht dasselbe.
Zweitens ist das Bild auch öffentlich zugänglich. Jeder kann es auf der Seite der FAZ sehen. Welche Kopie man wo sieht, ist irrelevant.
Bleibt noch das Geschäftliche: Wenn Sie mit Hilfe von FAZ.net Geld verdienen, müssen Sie denen einen Teil abgeben. Höhe ist Verhandlungssache.
So, Urheberrechtsreform ist fertig.
@299
Ziemlich geiler Hinweis mit dem Website-Caching :)
Wenn die ganzen Keeses und Jakobs sich im Jahre 2023 dann endlich darauf geeinigt haben, dass die robots.txt tatsächlich existiert, bis dahin releast Google wahrscheinlich gerade das gesamte Internetz als begehbares 3D-Hologramm :) Und Recht haben die.
@170, alter Jakob:
„Mich würde aber Ihr Vorschlag interessieren, wie bspw. ein Fotograph seine Bilder anpreisen soll, wenn er sie niemandem zeigen darf?“
Das ist mit minimalem Aufwand möglich! Ich versuche es so anschaulich wie möglich zu erklären.
Gehen wir mal davon aus, dass Sie eine Seite namens http://www.fotos.example.de betreiben. Darauf stellen Sie ihre Fotographien aus und bieten sie zum Kauf bzw. zur Lizenzierung an.
Folgendes ist mit einfachsten Mitteln möglich:
(1) Sie zeigen Ihre Bilder wie gehabt (in allen beliebigen Auflösungen, mit/ohne Wasserzeichen) auf fotos.example.de an. Jeder Besucher kann diese betrachten und ggf. herunterladen.
(2) Ihre Seite ist, sofern sie das wünschen, in der regulären Google-Suche gelistet. Potentielle Besucher können sie also dort über den Textinhalt Ihrer Seite finden.
(3) Was in der Google-Bildersuche erscheint, können Sie völlig unabhängig von (1) und (2) bestimmen. Bspw. erlauben Sie nur, kleine Vorschaubilder mit/ohne Wasserzeichen anzuzeigen. Oder Sie verbieten die Anzeige Ihrer Bilder komplett. Das alles ist mit standardisierten Webtechniken, ohne großen Aufwand, machbar. Vor allem ist es so einfach, dass es jedem Seitenbetreiber zumutbar ist. Ich behaupte sogar, dass jeder professionelle Seitenbetreiber ein Vielfaches an Aufwand für Search Engine Optimization (SEO) betreibt als er das hierfür je müsste.
Sie sehen also, dass sie Ihre Werke weiterhin anpreisen können, insbesondere auch über die Google-Bildersuche. Und zwar in genau der Form, die Sie für richtig erachten.
Es macht dahingehend einen Unterschied, dass Google nur solange veröffentlichen darf, wie die Einwilligung besteht. D.h. nach dem TN-Urteil darf Google die Veröffentlichung untersagt werden, wenn die robots.txt die Bildersuche verbietet (und Google trotzdem veröffentlichen würde). Wenn die Veröffentlichung selbst keine Rechtsverletzung wäre, dann könnte eine Änderung der robots.txt daran auch nichts ändern.
Es gibt aber noch einen zweiten Punkt. Für die Herleitung der Zulässigkeit der veröffentlichten Vorschaubilder ist die Einwilligung ja auch relevant. Die Frage ist nämlich wie weit die implizite Einwilligung reicht. In Bezug auf die Suche aus 2010 hat der BGH festgestellt, dass auf jeden Fall eine Einwilligung besteht, die Bilder in der kleineren Vorschauvariante zu veröffentlichen. Dass nun zusätzlich zur Einwilligung in die Vorschaubilder auch die Zustimmung zu einer Veröffentlichung der Bilder in Originalgröße/-qualität und außerhalb des ursprünglichen Kontexts gegeben wird, nur weil Google die eigene Suche entsprechend ändert, halte ich für eher unwahrscheinlich.
@307 TM:
Da ging es für mich um die Frage, ob man Bilder, die öffentlich zugänglich sind, grundsätzlich ohne Genehmigung benutzen darf. Wenn das so wäre, dann könnte man auch die Bilder mit/ohne Wasserzeichen aus fotos.example kopieren und an anderer Stelle benutzen.Darf man aber natürlich nicht. Dazu hab ich weiß Gott aber schon genug geschieben…
@308: Ich bin mir ziemlich sicher, dass Google ein Vorschaubild bei ‚zurückgezogener impliziter Einwilligung‘ (also nach dem Anlegen einer robots.txt) auch nach zumutbarer Frist im Rahmen der nächsten Aktualisierung entfernen wird. Der Einwand ist also auch eher akademisch.
Was die Originalbilder angeht, da sind wir _wieder_einmal_ bei der ungeklärten Frage, ob es sich überhaupt um eine Veröffentlichung handelt. Die Kreise die wir ziehen werden also enger, vielleicht belassen wir es einfach dabei.
@310:
Klar, Google würde keine Vorschaubilder zeigen, wenn die robots.txt das verbietet. Den Punkt hab ich nur erwähnt, um auf den Unterschied hinzuweisen, der mit der Einwilligung begründet ist.
Und was die Originalbilder angeht: Wenn schon kleine Vorschaubilder als rechtsverletzend angesehen wurden, dann sind es Originalbilder erst recht. Da ist gar nichts ungeklärt, sondern ganz klar und eindeutig im TN-Urteil festgestellt.
Aber ich habe gerade den Fehler in meiner Argumentation festgestellt. Denn das Originalbild ist nicht, wie ich angenommen hatte, auf der Google-Seite zu sehen, sondern auf der URL der Zielseite …Aaaah, mein Fehler.
Dann sehe ich die Sache allerdings auch nicht mehr sooo eindeutig wie bisher. Denn dann kommt es wohl erstmal darauf an inwiefern die Einwilligung auch die vergrößerte Bildvorschau umfasst. Da kann man natürlich eher geteilter Meinung sein. Der Link zum Originalbild ist wohl eher unproblematisch für Google, das stimmt.
Aaaah, OK. :-)
Unser Missverständnis lag dann vermutlich daran, dass das, was Sie ‚vergrößerte Bildvorschau‘ nennen von mir teilweise ‚Originalbild‘ genannt wurde, während Sie damit den hinter dem Link ‚Originalbild anzeigen‘ versteckten Inhalt meinten.
Begründung für meine Bezeichnung als ‚Originalbild‘ ist die Tatsache, dass auch dieses Bild nicht als Kopie bei Google gespeichert und von dort ausgeliefert wird, sondern stattdessen per Hotlink das Bild vom Server des Bildeigentümers geladen wird. Eine Urheberrechtsverletzung durch Kopie liegt also in jedem Fall nicht vor, allenfalls eine Rechtsverletzung durch ‚Zueigenmachen‘ eines fremden Bildes. Darüber ob dieses Zueigenmachen hier vorliegt, so dachte ich bislang, diskutieren wir hier.
Nachdem ich mir sämtliche(!) Kommentare hier durchgelesen und dafür ca. 3 Stunden meines Lebens aufgewendet habe, möchte ich noch meinen persönlichen Gesamteindruck zum Besten geben.
Mir scheint, die Kritiker der neuen Bildersuche lassen sich grob in 2 Kategorien einteilen.
Einerseits diejenigen Kreativen, die aus hehrer, ideeller Überzeugung heraus beanstanden, dass ihr wie auch immer geartetes Werk „aus dem Kontext gerissen“ und zusammenhanglos, außerhalb ihrer künstlerischen Kontrolle, irgendwo dargeboten wird.
Andererseits solche, die Bilder (eigene, lizensierte, gemeinfreie usw.) auf ihrer Seite zeigen und die darauf geschaltete Werbung als legitime Einnahmequelle betrachten.
Dabei ist mir durchaus bewusst, dass sich viele der Betroffenen mehr oder weniger gleichzeitig in beiden Gruppen wiederfinden.
Ich möchte an erstere Gruppe appellieren, sich nicht vor den Karren der zweiten spannen zu lassen. Ihr habt nach wie vor die volle Kontrolle über Eure Werke. Nutzt die (vorhandenen) technischen Möglichkeiten, um jegliche Verwendung Eurer Arbeiten zu verbieten, die nicht Euren Vorstellungen entspricht! Dass dies keine Entscheidung zwischen Pest (=unauffindbar) und Cholera (=ausgebeutet) ist, habe ich in Post #307, und andere Kommentatoren vor mir, ausgeführt.
Der Gruppe der Werbenutznießer und Suchmaschinenoptimierer dagegen möchte ich sagen, dass sie von mir kein Mitleid erwarten können. So schön es war, für das bloße Anbringen von Werbebannern bezahlt zu werden, einen gesellschaftlichen Nutzen hatte dies nie.
@313: Word!
@299
„Auch wenn mein Beitrag in der Flut an Kommentaren vermutlich untergehen wird“
Offensichtlich nicht, im Gegensatz zu meinem Hinweis auf den Google-Cache (und die archive.org-Schande) in @259 und @262.
Aber schön, daß sie nochmal drauf hingewiesen haben, doppelt hält besser.
Ich weiß imer noch nicht, was richtig und fair ist.So. Nachdem jetzt wirklich alles auch von jedem gesagt wurde, können wir uns jetzt wieder anderen Dingen zuwenden.
@306:
„Wenn die ganzen Keeses und Jakobs sich im Jahre 2023 dann endlich darauf geeinigt haben, dass die robots.txt tatsächlich existiert, bis dahin releast Google wahrscheinlich gerade das gesamte Internetz als begehbares 3D-Hologramm :)“
Das gesamte Internetz abzüglich Deutschland, meinst Du vermutlich…
Dieses 3D-Hologramm ist in Ihrem Land leider nicht verfügbar, weil es urheberrechtlich geschützte Lichtquanten enthalten könnte.
Ein aktueller Einblick in die Anti-Copyright-Lobby, die hier einige Diskussionsteilnehmer bereits erfolgreich instrumentalisiert haben:
http://goo.gl/wvos0
(Mutter aller URLs gekürzt)
@dexter
Hören Sie doch bitte auf, den Fotografen zu unterstellen, dass die das doch alle toll finden.
Im DSLR-Forum ist man da durchaus durchwachsener Meinung:
http://www.dslr-forum.de/showthread.php?t=1214859
Rechtlich gab es wohl auch schon ein Urteil:
http://www.heise.de/newsticker/meldung/Framing-eines-Fotos-verletzt-Urheberrechte-138167.html
Ist nicht mein Text, aber finde ich sehr treffend:
„Lange nicht mehr kam bei mir so viel Fremdschämen auf wie beim Lesen diverser Verweise auf die robots.txt. Liebe Leute, die ihr das für eine Option haltet:
Ihr lebt in einem Rechtsstaat. In einem solchen darf Mensch sich darauf verlassen, dass zugesicherte Rechte ihm auch erhalten bleiben, ohne dass er für jeden möglichen Angreifer eine eigene Abwehrstrategie entwirft.“
http://www.dslr-forum.de/showpost.php?p=10736426&postcount=81
@Andreas Roedl
Jemand, der nicht Ihre Meinung vertritt, hat sich von einer Lobby instrumentalisieren lassen? Das ist keine Basis, auf der eine Diskussion möglich ist.
Und in meinen Augen ist es, lieber Chico, selbst in einem Rechtsstaat manchmal vonnöten, zu sagen, was man will. Unter uns Menschen sind Worte da manchmal (aber eher selten) eine gute Wahl, Suchmaschinen können mit einer robots.txt eher etwas anfangen. Was oft vergessen wird: Wem das Erstellen einer solchen zu viel Aufwand/zu kompliziert ist, der kann auch heute noch außerhalb des Internets ganz vortrefflich Geld verdienen.
Hi hi, sich über den Ausdruck „lobbygesteuert“beschweren weil man auf der Basis keine Diskussion führen könnte und dann den Betroffenen den „guten“ Rat geben, sich doch bitte eine neue Existenz aufzubauen, wenn man nicht mit Googles vorgehen einverstanden ist. Friss oder stirb, das klingt doch nach einer viel vernünftigeren Diskussionsgrundlage, auf keinen Fall aber nach Googlebrainwash. Ich verstehe jedenfalls nicht, wieso es der Untergang des Abendlandes sein soll, wenn die HD-Vorschau aus der Bildersuche wegfällt.
Aber es redet sich halt immer leicht, wenn man nicht betroffen ist (das weiß ich, weil ich mich ja auch leicht rede). Und genau deshalb wünsche ich kasuppke und Jeff viele gesunde Kinder, die alle Fotografen, Künstler und Graphikdesigner werden.
——————————————————————-
An all die Google-Hasser (die natürlich vorher und auch weiterhin von Google profitieren):
Ist auch nur einem von Ihnen folgendes Gerichtsurteil aus D bekannt:
http://www.telemedicus.info/urteile/Urheberrecht/Thumbnails/1047-BGH-Az-I-ZR-6908-Vorschaubilder-Google-Thumbnails.html
Dreist und vor allem dumm sind hier all die Kommentare, die von Unkenntnis sowohl der TOS von Google als auch der Funktionsweise der robots.txt. zeugen und ein – gelinde gesagt – laienhaftes Rechts- und Selbstverständnis an den Tag legen.
Was für ein weltfremdes Gejammere weil Google nun plötzlich böse ist.
Wenn dem so ist, dann nutzt es einfach nicht! Wenn das für euch nicht geht, dann ist das halt so. Das Leben ist nun mal kein Ponyhof! Habt ihr etwa geglaubt, Google sei altruistisch?
lol
Und ich finde es sehr gut, dass der Kapitalismus nun auch den Kreativen Probleme bereitet: je schlimmer, desto besser – desto eher erreicht man die kritische Masse für eine gesamtgesellschaftliche Neuausrichtung.
——————————————————————-
@ kleitos:
Jawoll, das Urteil ist bekannt und der Unterschied ist auch schon erwähnt worden. Aber wenn bei einem die Lichter ausgehen und man geifernd Amok schreiben muss, sobald man auch nur die Wörter „Google“ und „Kritik“ erahnen kann, dann kann ich mir gut vorstellen, dass man einfach noch nicht umrissen hat, worum es hier genau geht .
Da du aber ganz offensichtlich ein patentes Kerlchen und auch ein unglaublich professioneller Urteilsversteher bist (wahrscheinlich auch viel besser als Googles Anwälte), kriegst du den Unterschied auch noch raus.
Was die Thumbnail-Entscheidungen angeht, muss man schon noch differenzieren, das sagt der Artikel ja auch. Erstens werden die Urteile in der Rechtswissenschaft äußerst kritisch rezipiert (insbesondere das Konzept der konstruierten „schlichten“ Einwilligung). Zweitens hat die grundsätzliche (durchs Gericht festgestellte) Erlaubnis, in den organischen Suchergebnissen Bilder als Thumbnails anzuzeigen mE nichts mehr damit zu tun, sich das Bild gänzlich zu eigen zu machen.
Dass Google längst nicht mehr nur Intermediär ist, passt übrigens auch prima zur Debatte um das Leistungsschutzrecht:
Google führt vermehrt fremde Inhalte eigenem gewerblichen Nutzen zu. Freies Internet schön und gut, aber das Gegenargument ist zunächst mal nicht von der Hand zu weisen. Zum Glück gibt es genügend andere Ansatzpunkte, an denen man gegensteuern kann.
Allerdings frage ich mich schon, wie Herr Niggemeier seine Aussage „Wenn Google behauptet, dass die Änderung auch den Seitenbetreibern zugute kommt, ist das offenkundiger Unsinn.“ in diesem Kontext bewerten würde.
@Fritz: Da habe ich jetzt die Frage nicht verstanden und könnte nur mit einer Gegenfrage antworten: Inwiefern kommt die Änderung denn den Seitenbetreibern zugute?
Denke ebenfalls, dass die Aussage ziemlicher Unsinn ist.
Hatte es beim LSR aber immer so verstanden, dass dieser Punkt unter den Tisch fällt. Dort macht Google ja nichts oder besser: wenig anderes – nur eben mit Nachrichtenseiten. Allerdings habe ich keinen Gegner des LSR jemals sagen hören, dass es offenkundiger Unsinn ist, wenn Google behauptet, die Indexierung nutzt auch Verlagsseiten.
Bin nun wirklich kein Freund des LSR, frage mich aber, ob man da nicht ein Stück weit mit zweierlei Maß misst.
@322, alter Jakob:
Die Sache ist doch die, dass viele Webseitenbetreiber, die ihre Inhalte kostenlos ins Netz stellen, ihr Geschäftsmodell zu einem Großteil auf Google aufbauen. D.h. auf die Tatsache, dass Google ihnen Traffic bringt, oder gar gleich auf Google AdSense. Der Traffic auf der Seite wird mit Google Analytics gemonitort. Alles Tools und Services, die Google für umsonst bereitstellt. Da ist es dann schon reichlich borniert, rumzulamentieren, wenn man sich mit der Funktionsweise des Googlebots auseinandersetzen soll.
Webseitenbetreiber, die mit bloßem, auch unqualifiziertem Traffic (und das *ist* Traffic, der nur zustandekommt, weil in der Bildersuche die ganze Seite in einem Frame angezeigt wird) kein Geld verdienen, sollten eher froh sein über die Entlastung.
@Fritz:
Ich möchte auf den Unterschied der Schöpfungshöhe zwischen einem kompletten urgehobenem Werk auf der einen und den Allerweltssatzschnipseln die den Inhalt erahnen lassen auf der anderen Seite hinweisen.
Ein Snippet gibt eine Ahnung, was auf der Zielseite steht und führt vielleicht Leser zu. Wenn nicht, dann wissen die fast-Leser aber nicht was genau in dem Artikel drin stand. Es ist also notwendig die Zielseite zu besuchen, um das komplette Suchergebnis zu sehen.
Wenn ich aber ein komplettes großes Bild auf der Suchseite in hoher Auflösung sehe, dann ist das der komplette Inhalt, nach dem ich gesucht habe. Es gibt keinen Grund auf die Zielseite zu schauen.
Wenn Google komplette Artikel auf der Suchseite veröffentlichten würde, dann wäre es das gleiche. Um das zu Untersagen ist aber kein LSR notwendig, da reicht das UrhG.
Man muss bei Urherberschutz und dem geplanten LSR mit zweierlei Maß messen, denn es ist nicht dasselbe.
@328 Augusten:
Ich sage gar nichts dagegen, dass derjenige, der sich finden lassen will, sich auch finden lassen muss.
Aber wieso soll ein Dienst, den ich Nutze, meine Inhalte so verwenden dürfen wie er will, nur weil ich die Suchfunktion nutzen will, nicht aber seine Verwerterfunktionen? Darf Google dann auch komplette Webauftritte Framen (ein Google-Spon?). Und das ist doch die Frage: Was kann man noch als „Suche“ oder „Suchergebnis“definieren und was schon als Verwertung?
Und Google macht das umsont? Google verdient nicht an Google Ads? Sind die entgegen der Aussage von kleitos doch Altruisten?
Nachtrag zu 330:
Ich würde auch ein wesentlich geringeres Problem sehen, wenn der einzelne Nutzer über die robots.txt die Möglichkeit hätte lediglich die HD-Anzeige zu verbieten und gleichzeitig die Thumbnails zu erlauben. Das geht aber soweit ich weiß nicht, weil die HD-Anzeige automatisch mit der Bildersuche verwendet wird. Wenn ein Bild auffindbar ist, dann gibt es Zwangsweise auch die HD-Ansicht. Sollte das anders sein, dann bitte ich darum mich zu korrigieren.
Genau das tut doch die alte Bildersuche… (scnr)
@331: ‚Wenn ein Bild auffindbar ist, dann gibt es Zwangsweise auch die HD-Ansicht. Sollte das anders sein, dann bitte ich darum mich zu korrigieren.‘
Rufen Sie die Googlesuche einmal mit dem Suchbegriff ’site:de.fotolia.com‘ auf.
Ergebnis sind jede Menge Bilder, die auf der Seite erworben werden können (der für den ‚Eigentümer‘ positive Werbeeffekt der Googlesuche ist also weiterhin vorhanden), aber keins davon hat die ‚HD-Qualität‘ die einen Bilderwerb auf der Seite überflüssig macht.
Warum ist das so? Weil de.fotolia.com geeignete technische Maßnahmen einsetzt, um die Aufnahme von originalgroßen Bildern zu verhindern. In diesem Fall halt nicht nur robots.txt, wobei diese Datei in einem kleineren Hobby-Umfeld sicherlich ausreichend wäre, um den gleichen Effekt zu erzielen. Wie genau, das haben wir ja alle schon einmal geschrieben.
@332: Stimmt. Den Beitrag schreibe ich gerade über Google.de im Frame von einem Bild des Niggemeier-Blogs, von dem ich wiederum in diesen Beitrag gelangt bin. … es geht aber vergleichsweise langsam voran. Immerhin, ich kann alles sehen, also nicht nur das Bild oder den Artikel.Da funktioniert Google wie ein Zwischenbrowser.
Ich muss mich also präzisieren: Wenn nur Inhalte (Artikel/Bilder) von ganzen Webauftritten geframed werden, alles ausserhalb der Inhalte aber geschwärzt ist (Werbung, Seitenlogo, etc.)
@333:
Also ist die Antwort nein. Es geht nicht mit der robots.txt?
Danke euer Ehren, keine weiteren Fragen.
@335: Doch, das geht auch. Habe ich ja auch so und nicht andersrum geschrieben. Nicht nur in #333 sondern auch schon vorher – und auch nicht nur ich, sondern diverse andere Kommentatoren auch.
@336:
Den Beitrag müssten Sie mir zeigen. Ich hab lediglich #288 gefunden, aber da muss ich immer noch selbst Bilder in verschiedener Qualität und verschiedene Ordnerstrukturen vorhalten. Und der Link von Google zu meiner Seite geht dann auch auf das schlechte Bild (wobei man den wahrscheinlich auch umlenken könnte).
Eine Beschreibung wie ich das Bild, das in der Google-Suche als Thumbnail angezeigt wird, per robots.txt gleichzeitig von der Vorschau ausschließen kann, hab ich nicht finden können.
@337: Ja, und genau damit ist ihr Bild doch auch _auffindbar_. Danach hatten Sie doch gefragt.
Tatsächlich: Ich bin davon ausgegangen, dass Ihre hypothetische Bilder-Seite schon aus etwas mehr besteht als meinetwegen einer händisch zusammengefrickelten Frontpage-Seite. Zum Beispiel, dass dort eine der vielen frei erhältlichen PHP-Bildergalerien läuft. Dann übernimmt die Software das Skalieren der von Ihnen hochgeladenen Bilder ganz automatisch, und wenn Sie dann die folgende robots.txt anlegen, werden die Galerieseiten mit den verkleinerten Bildern gefunden und indexiert, nicht aber die über diese Galerieseiten ebenfalls noch verfügbaren hochauflösenden Bilder:
User-agent: *
Allow: /albums/small_*.jpg$
Allow: /albums/thumb_*.jpg$
Disallow: /albums/
Wenn das schon eine Größenordnung über der Technik Ihrer Bilderseite liegt, dann klappt es womöglich nicht ohne zumindest einen kleinen manuellen Eingriff. Dann frage ich mich aber auch ganz ernsthaft, was diese Debatte dann noch soll. In dem Fall wäre Ihre Logik dann ja, dass Sie wahllos HQ-Bilder in irgendein Verzeichnis dumpen können, bitteschön erwarten, dass diese per Suche gefunden werden können, aber keinesfalls angezeigt werden dürfen. Da wäre es meiner Meinung nach wirklich nicht zu viel verlangt, sich für das ein oder andere Extrem zu entscheiden.
Keine Ahung warum ich so schwer zu verstehen bin. In #331 hab ich noch noch den Begriff HD-Anzeige verwendet und dachte deshalb wissen Sie nicht was ich will. In #337 find ich meine Frage aber ziemlich eindeutig.
Nochmal: Ich will meine Bilder in der Suche finden lassen und selbstverständlich auch als Thumbnail anzeigen lassen. Ich möchte dann per robots.txt aber verhindern, dass dieses eine gefundene und als Thumbnail angezeigte Bild als vergrößerte Vorschau zu sehen ist.
Und jedes mal wieder bieten Sie mir einen Workaround an, der mich zu den verschiedenen Einträgen in die robots.txt Mehrarbeit kostet, die ich nicht bereit bin zu leisten.
Ich will nicht wissen, wie ein funktionierender Workaround aussieht und wieviel Arbeit er mir macht. Das interessiert mich nicht die Bohne. Ich möchte nur wissen ob es einen robots.txt Befehl gibt, mit dem ich das Anzeigen der Vorschau verhindern kann, so dass bei einem Klick auf das Thumbnail direkt auf die Seite weitergeleitet wird, auf der das gefundene Bild liegt.
Das Problem ist, dass Sie von einer vollkommen unrealistischen Ausgangssituation ausgehen. Ein Bild (HD oder nicht) muss in irgendeinen Kontext (=Webseite) eingebettet sein, dem Google die zum Bild passenden Suchbegriffe entnehmen kann. Wenn dieser Kontext nicht existiert, wird das Bild schon allein deswegen nicht angezeigt, weil es nicht an passender Stelle in Googles großem Suchindex hinterlegt ist.
Wenn aber ein Kontext existiert, dann werden Sie dort Ihre Besucher sicher nicht damit quälen wollen, dass sie das druckfähige, mehrere MB große Bild direkt dort einbetten – sondern Sie werden eine verkleinerte Version davon anzeigen. Die oben beschriebene Vorgehensweise ist also kein wegen Google zu leistender Mehraufwand, sondern etwas was eh schon existiert, wenn Ihre Webseite halbwegs sinnvoll funktioniert.
Den verbleibenden Punkt gönne ich Ihnen gern, wenn Sie ihn haben möchten: Für HD-Bilder ohne jeglichen Kontext gibt es keine robots.txt-Möglichkeit. Sie werden in der Googlesuche angezeigt, sobald Google seine Bild-KI dahingehend perfektioniert hat, dass sie die notwendige Bildinhaltsbeschreibung automatisch selbst erzeugt. Wohin Google dann allerdings verlinken sollte, wenn doch gar kein Kontext existiert, haben Sie bis dahin hoffentlich auch herausgefunden.
@340: Ich will nicht keinen Kontext. Ich will ganz normal als Thumbnail gefunden werden und auch kein anderes Bild in der Vorschau zeigen lassen. Ein letztes mal, dann verabschiede ich mich auch endlich:
Ich.Will.Die.Vorschau.Auf.Google.Per.Robots.Txt.Abschalten.
Schönen Abend noch.
@alter Jacob:
Die Google-Bildersuche ist dumm. Alle Bilder, die Google findet werden schlicht einmal verkleinert auf der „Thumbnail“-Übersichtsseite und einmal groß bis zur originalen Auflösung in der HQ-Vorschau gezeigt.
Wenn das realisiert werden soll, was sie wünschen, dann dürfen sie Google nur den Zugriff auf ihre thumbnailgroßen Bilder erlauben.
Nur Thumbnails der auf ihrer Seite veröffentlichten HQ-Bilder geht nicht. Sie müssen also für die Thumbnails selber sorgen.
Google-Sicht:
Google bietet Bilderanbietern schlicht an, dass ihr Bilder so wie veröffentlicht über die Suche im Netz gefunden werden können. Mehr nicht.
Wer ein Problem damit und/oder mit der Form wie das realisiert hat, kann die eigenen Bilder ja leicht entfernen lassen.
Noch eine Feststellung:
Die Thumbnails kommen m.E. von den Googleservern. Man schaue sich deren URI an.
@Stefan Niggemeier:
Inwiefern kommt die Änderung denn den Seitenbetreibern zugute?
Die Änderungen an der Suche haben natürlich zur Folge, dass sich der Nutzen für die einzelnen Beteiligten ändert. Für die Suchenden als auch für die, die zu gesuchte Sachen anbieten.
Für die Anbieterseite gilt: Für viele, deren Bilder bislang dort gefunden wurden ist die Situation jetzt schlechter als vorher. Für andere hat sich die Situation jedoch verbessert.
Vor allem für Webseitenbetreiber, deren Bilder primär der Zierde des Textes dienten, die Bilder also selbst schon als (lizensierte) Kopie veröffentlicht haben und bislang Traffik von der Bildersuche bekamen ist die Situation jetzt ungünstiger.
Ich glaube, dass das auch von Google gewollt ist, da diese Bilder ja eine große Redundanz aufweisen.
Für Anbieter originärer Bilder (Stockfotos etc), die ein vitales Interesse daran haben ihre (Vorschau-)Bilder zu finden sind, hat sich die Situation verbessert.
Man stelle sich die neue Suche mal ohne die vorherige Existenz der alten Suche vor. Welche der beiden Versionen ist fruchtbarer?
@alter Jakob
Aber wieso soll ein Dienst, den ich Nutze, meine Inhalte so verwenden dürfen wie er will, nur weil ich die Suchfunktion nutzen will, nicht aber seine Verwerterfunktionen? Darf Google dann auch komplette Webauftritte Framen (ein Google-Spon?).
Die alte Suche hat genau das gemacht. Wieso haben Sie sich darüber nicht aufgeregt?
Und das ist doch die Frage: Was kann man noch als »Suche« oder »Suchergebnis»definieren und was schon als Verwertung?
Inwiefern ist es Verwertung, wenn eine Bildersuche ein Bild als Ergebnis anzeigt?
Und Google macht das umsont? Google verdient nicht an Google Ads? Sind die entgegen der Aussage von kleitos doch Altruisten?
Es ist immer wieder erstaunlich wie wenig Ahnung die Leute, die Google Vewertung von Inhalten vorwerfen, vom Google-Geschäftsmodell haben. Google verdient was mit „Google Ads“, allerdings stammen 80% osä der Einnahmen aus Adwords, und die werden in der Bildersuche nicht angezeigt (genausowenig wie bei Google News übrigens). Es gibt noch AdSense, das Webseitenbetreibern die Möglichkeit gibt, Google Ads auf ihren Seiten einzublenden. Daran verdient Google ein bisschen was und teilt sich die Einnahmen mit dem Webseitenbetreiber.
Google verdient nichts mit der Bildersuche und auch nicht mit Google News. Das wird alles von der Suchmaschine quersubventioniert.
Wer sein Geld mit Google verdient (und vielleicht auch noch heftig SEO betreibt, um von Google möglichst prominent gefunden zu werden), kann sich doch wirklich mal mit der Funktionsweise des Bots auseinandersetzen. Wer damit kein Geld verdient, für den ändert sich nichts, denn für denjenigen stellt der sinnlose Traffic, der dadurch verursacht wurde, dass die Bildersuche die Seite in einem Frame anzeigt, keinen Wert dar. Im Gegenteil.
Frage in die Runde: wer oder was war zuerst da? Das Web oder Google? Wer gibt hier im Internet überhaupt die Regeln vor? Wieso haben wir etwas, was sich „robots.txt“ nennt? Haben wir uns als Anbieter das ausgedacht oder wurde das nicht deshalb notwendig, weil wir etwas künstlich einschränken mussten?
Google ist nicht das Web! In der Anfangszeit musste niemand ein File in DocumentRoot anlegen, das sich robots.txt“ nennt! Google (und all die Suchmaschinen zuvor) hat sich einfach das Recht genommen, mit den Inhalten anderer Leute Geld zu verdienen.
Google profitiert von einer Art Leistungsschutz, das sich hier in Deutschland Datenbankherstellerrecht nennt. Wie auch die Heise Verlagsgruppe (Telefonbücher), existiert Google nur deshalb, weil sie sich auf diesen Leistungsschutz berufen dürfen. Weshalb sollten Konzerne vom Urheberrecht profitieren, welches sie verletzen, indem sie sich an den Inhalten/Daten der restlichen Gesellschaft bedienen?
Google versucht, derzeit allen anderen Urhebern jegliche Rechte abzusprechen, weil sie nicht in der Lage sind, mehr als nur bereits vorhandene Werke zu indexieren. Sie haben bis auf ihre PR noch nie irgendetwas geschaffen.
Es gab ein Web bevor es Google gab. Die, die gerade ein Problem mit der Vorgehensweise von Google haben, haben ihr Geschäftsmodell eben nicht auf Basis dieser Suchmaschine gegründet, wie es hier gewisse Kommentatoren behaupten.
Google ist nicht das Web.
@Andreas:
Das ist doch ganz billiges Google-Bashing.
Die elementare(!) Erfindung bzw. Leistung Googles, die das Web Google verdankt habe ich weiter oben schon mal erläutert.
Google ist nicht das Web.
Richtig. Und das Web ist nicht Deutschland und seine tradierten Rechtsnormen.
Wie wir alle wissen stellen die Regeln denen das Web folgt schlicht einen Konsens dar, den die Teilnehmer eben frei gefunden haben. Ich finde RFCs wunderbar!
Kurze Frage: Wie stellen sie sich eigentlich eine ideale netzweite Bildersuche vor? (Sofern so etwas von ihnen überhaupt als sinnvoll erachtet wird ..)
Gaaanz am Anfang gab es auch keine Leute, die irgendwelche Bilder ins Web gestellt und sich dann über Abruf geärgert haben… Damals gab es reine Textbrowser. Diese Betrachtungen sind historisch interessant, aber nicht wirklich hilfreich.
@Andreas , #345: Ernsthaft?
1. Suchmaschinen halten sich an die Vorgaben der robots.txt aus Höflichkeit, sie sind nicht dazu verpflichtet. Betrachte es als Service.
2. Suchmaschinen werten Informationen aus, die andere im Internet für jedermann (oder sogar gezielt für Suchmaschinen) frei zugänglich machen. Das ist ihr gutes Recht. So wie es mein gutes Recht ist, mir alle Informationen anzuschauen (und in den meisten Fällen auch zu kopieren) die frei zugänglich sind. Das ist der Sinn dieses gigantischen Computernetzwerks. Wer das nicht möchte, sollte seine Informationen einfach nicht frei zugänglich online stellen. Zum Beispiel kann niemand (hoffe ich ;-) ) auf die Bilder auf diesem PC zugreifen, obwohl der genauso Teil dieses Netzwerks ist.
3. Der Aufhänger für diesen Blogpost war, dass die Besucherzahlen aufgrund der neuen Google-Suche auf einigen Webseiten eingebrochen sind. Und dass dadurch deren Geschäftsmodell nicht mehr funktioniert. Und jetzt sagst du, dass deren Geschäftsmodell nicht im geringsten auf Google beruht?
4. Aus dem gigantischen unsortierten Informationshaufen Internet innerhalb eines Bruchteils einer Sekunde die gewünschte Information herauszufinden ist also keine Leistung? Ernsthaft? Welches ist nochmal das weitverbreitetste Smartphonebetriebssystem? (tbc)
„Frage in die Runde: wer oder was war zuerst da? Das Web oder Google?“
Zuerst war Tim Berners-Lee. Und er sprach:
“The WorldWideWeb (W3) is a wide-area hypermedia information retrieval initiative aiming to give universal access to a large universe of documents.”
„Wer gibt hier im Internet überhaupt die Regeln vor?“
Die Nutzer. Abgesehen davon: Internet != WWW
„Wieso haben wir etwas, was sich »robots.txt« nennt?“
Weil wir nicht mehr in der Steinzeit des WWWs leben, als sich die Betreiber der Webserver noch persönlich kannten.
„Haben wir uns als Anbieter das ausgedacht oder wurde das nicht deshalb notwendig, weil wir etwas künstlich einschränken mussten?“
Die robots.txt wurde notwendig, weil die Zahl der Webserver explodierte und nur noch durch Suchautomaten zu händeln war, nicht mehr durch persönliche Anfrage beim Herrn Roedl.
„Sie haben bis auf ihre PR noch nie irgendetwas geschaffen.“
Stimmt: http://en.wikipedia.org/wiki/List_of_Google_products
@Andreas Roedl
Richtig, Google ist nicht das Web. Aber wer sich noch an die Zeit vor Google erinnern kann, weiss auch noch, wie schwierig es damals war, im viel kleineren Netz irgendwas zu finden, was man gesucht hat.
Google existiert nur deshalb, weil sie sich auf einen Leistungsschutz berufen können. Hä? Muss ich das verstehen? Ich dachte immer, Google existiert und ist so groß geworden weil sie
a) eine überragende Technologie entwickelt haben und immer weiter entwickeln, die immer noch ihresgleichen sucht. Oder was glauben Sie, warum kaum jemand irgendeine andere Suchmaschine benutzt? Wegen einem Leistungsschutzrecht? Get real!
b) es geschafft hat, mittels einem neuartigen Geschäftsmodell mit dieser technologie auch Geld zu verdienen.
Und jetzt kommen Sie und erzählen mir, Google sei nur sowas ähnliches wie ein Telefonbuchverlag? Ich bitte Sie.
Jetzt erklären Sie mir bitte noch, welches Geschäftsmodell genau dadurch gefährdet wird, dass kein sinnloser Traffic mehr auf bestimmte Seiten geleitet wird, und warum dieses Geschäftsmodell nicht von Google abhängt. Würde mich wirklich interessieren.
@Augusten:
Aber wer sich noch an die Zeit vor Google erinnern kann, weiss auch noch, wie schwierig es damals war, im viel kleineren Netz irgendwas zu finden, was man gesucht hat.
Es war eine Krux.
http://de.wikipedia.org/wiki/Gopher
:)
@alter Jakob 324
Jawoll, das Urteil ist bekannt und der Unterschied ist auch schon erwähnt worden.
Aber offensichtlich von Ihnen nicht verstanden worden. Die Zugänglichmachung via robots.txt entspricht einer Einwilligungserklärung. Wollen Sie das nicht, können Sie das einfach per robrots.txt abstellen.
Sie wollen gewaschen (gefunden) werden, ohne das man Ihnen den Pelz nass macht (Ergebisanzeige).
Aber wenn bei einem die Lichter ausgehen und man geifernd Amok schreiben muss, sobald man auch nur die Wörter »Google« und »Kritik« erahnen kann, dann kann ich mir gut vorstellen, dass man einfach noch nicht umrissen hat, worum es hier genau geht .
Sie haben bereits sehr deutlich gemacht, worum es Ihnen geht: Sie fühlen sich unfair behandelt. Sie haben – wie auch Ihre obige Bermerkung verdeutlicht – ein emotionales Problem.
Aber auch Google existiert nicht, um Ihre persönlichen Probelme zu lösen.
Da du aber ganz offensichtlich ein patentes Kerlchen und auch ein unglaublich professioneller Urteilsversteher bist (wahrscheinlich auch viel besser als Googles Anwälte), kriegst du den Unterschied auch noch raus.
Diese Hoffnung kann ich bei Ihnen leider nicht hegen – ich hatte ja bereits auf das vorliegenden laienhafte Rechts- und verzerrte Selbstverständnis hingewiesen.
Haben Sie denn vieleicht eine konstruktive Kritik bzw. Lösungsvorschläge für Ihr Problem, oder verlegen Sie sich bloß auf larmoyantes Wehklagen?
Kleine Beobachtung zum technischen Ablauf der neuen Bilder-Funktion, google zeigt anscheinend zuerst eine Vergrößerung des bei denen gespeicherten Thumbnails und ersetzt dies dann mit der von der ursprünglichen Webseite geholten Originals. Wenn die Originalseite auf Basis des Referrer kein Bild gibt bleibt es beim eher pixeligen Bild.
Ändert nichts an der grundlegenden Diskussion, aber zeigt was Blocks auf Basis der Referrer-Adresse bewirken würden.
@kleitos:
Schade, da war der Fritz in #325 so nett und wollte dich ein bisschen schlauer machen, und dann hat’s doch nicht geholfen.
Und mit emotionalen Problemen scheinst Du ja ’ne Menge eigene Erfahrung gemacht zu haben (jedenfalls mehr als mit BGH-Urteilen). Da will ich dann nicht widersprechen, wenn Du eines bei mir diagnostizierst. Ich hoffe nur, dass deine Ferndiagnose eine bessere Qualität hat, als deine Urteilsauslegung…
[gelöscht. ist auch mal gut jetzt.]
@alter Jakob #354
Schade, da war der Fritz in #325 so nett und wollte dich ein bisschen schlauer machen, und dann hat’s doch nicht geholfen.
Zitieren wir doch mal die „Belehrung“:
„Was die Thumbnail-Entscheidungen angeht, muss man schon noch differenzieren, das sagt der Artikel ja auch. Erstens werden die Urteile in der Rechtswissenschaft äußerst kritisch rezipiert (insbesondere das Konzept der konstruierten »schlichten« Einwilligung). Zweitens hat die grundsätzliche (durchs Gericht festgestellte) Erlaubnis, in den organischen Suchergebnissen Bilder als Thumbnails anzuzeigen mE nichts mehr damit zu tun, sich das Bild gänzlich zu eigen zu machen.“
Richtig wird erstens festgestellt, das das Urteil auch kritisiert wird, was ein ganz normaler Vorgang ist. Zweitens gibt er eine persönliche Einschätzung wieder der man folgen kann, aber nicht muss. Beide Punkte ändern das Urteil samt Begründung nicht.
Wo da nun ein Erkenntnisgewinn zu erzielen ist, erschließt sich wohl nur aus einer speziellen Perspektive, die sich primär durch ein Empfinden und nicht durch ein Verstehen auszeichnet.
Und mit emotionalen Problemen scheinst Du ja ›ne Menge eigene Erfahrung gemacht zu haben (jedenfalls mehr als mit BGH-Urteilen).
Auch hier ist wiederum kein Verstehen Ihrerseits zu erkennen. Das belegt neben der inhaltsleere Ihrer Aussage auch der Ansatz eines ad hominem.
Ich hoffe nur, dass deine Ferndiagnose eine bessere Qualität hat, als deine Urteilsauslegung…
Da ich nicht als Richter am BGH tätig bin obliegt es mir nicht, Urteile desselben „auszulegen“. Lesen und Verstehen ist vollkommen ausreichend.
Glücklicherweise habe ich von Ihnen nicht wirklich Lösungsvorschläge erwartet – sonst wäre ich nun enttäuscht.
So klagen Sie lediglich weiterhin larmoyant über die Ungerechtigkeit der Welt und arbeiten sich emotional aufgeregt an Sachargumenten ab und glauben, es würde Ihre Probleme lösen.
Wenn Sie sonst Nichts zu tun haben ….
Schwierig jetzt noch in die Debatte einzusteigen. Das meiste wurde gesagt, die Fronten sind festgefahren.
Ich versuche es trotzdem mal.
„Dumm und Dreist“ — WordPress um Funktinen zur Einbettung von Bilderrn erweitert
[gelöscht]
[gelöscht]
Schön, wie entspannt und sachlich die Diskussion hier verläuft.
@345, Andreas Roedl:
„Sie[Google] haben bis auf ihre PR noch nie irgendetwas geschaffen.“
Wow, diese Aussage ist (mit Verlaub, lediglich Bezug nehmend auf den Titel dieses Blogeintrags) „dreist und dumm“!
Vielleicht ist es ja Teil des Problems, dass technische Laien die Errungenschaften und den Wert der Google-Leistungen einfach nicht einschätzen können?
Das Polemisieren gegen Google bei gleichzeitigem konsequenten einblenden des Google+-Profils hatte ich für eine Form der Ironie gehalten. Habe ich mich wohl getäuscht.
Sollen sich auch alle schämen, die gedankenlos sich der Wunder der Wissenschaft und Technik bedienen, und nicht mehr davon geistig erfasst haben als die Kuh von der Botanik der Pflanzen, die sie mit Wohlbehagen frisst.
Wenn der Google Indizierer kommt, wird eben das große Bild technisch nicht verlinkt. Einfach mal den Admin fragen wie das geht. Das ist in fünfzehn Minuten erledigt und Google findet außer dem Thumbnail nichts.
Das selbe gilt übrigens auch für die deutschen Verlage. Sie könnten einfach beim „erkennen“ des Google Bots alles über den Titel und die ersten zwei Zeilen mit einem „Bitte auf Originalseite vorbeischauen“ Link versehen.
Aber das bringt eben 100fach weniger Geld als wenn man Google indirekt über ein Gesetz zur Kasse bittet. Traffic ist eben nicht gleich Umsatz.
Man kontrolliert die Server selbst. Die Anpassungen sind in Minuten erledigt. Aber lieber schreibt man 10.000 Seiten darüber dass man angeblich auf den eigenen Server nichts machen kann.
Irgendwie wirken die dt. „Kreativen“ zunehmend defensiv und weinerlich.
@361: Missverständlich ausgedrückt. Damit meinte ich künstlerische und kulturelle Werke im Sinne von Filmen, Musik, Literatur und dergleichen.
@Leo: „Das Polemisieren gegen Google bei gleichzeitigem konsequenten einblenden des Google+-Profils hatte ich für eine Form der Ironie gehalten. Habe ich mich wohl getäuscht.“
Will heißen: Wenn ich die Deutsche Bahn kritisiere, soll ich nicht verraten, dass ich mit ihr fahre?
@366: Das nicht. Aber wenn man das vermeintliche Ausnutzen eigener Bilder durch Google kritisiert wirkt es schon merkwürdig, wenn man gleichzeitig solche Bilder per Google+ veröffentlicht.
Aber das wird jetzt vermutlich wieder gelöscht. Warum gerade das so kontrovers sein soll, weiß ich nicht.
@361,362,367:
Sind wir also schon wieder bei persönlichen Angriffen angekommen? Keine Argumente mehr, aber die Diskussion darf nicht sterben, oder wie?
Da ich ja nicht feige bin und sogar auf mein Profil verlinke, kann man sich einen ersten Eindruck verschaffen, ob ich ein „technischer Laie“ bin.
Die Bilder habe ich freiwillig und absichtlich dort hochgeladen. Sie wurden nicht automatisch von anderen Websites hineingezogen.
EOD.
Abgesehen davon, dass meine Bilder nur mit geringstmögliche Ausflösung und Copyrightverweis ausgeliefert werden, finde ich das Vorgehen von Google eine Unverschämtheit. Und ich glaube , dass von den über 30 %, die auf meine Seite kommen, ein großer Teil wegbrechen wird.
Allerdings muss ich jetzt mal dumm fragen: letzter Stand der Dinge ist, dass die neue Suche in D noch nicht aktiviert ist (oder?). Zumindest bekomme ich bei allen Browsern noch die alte Ansicht zu sehen.
@Stephan:
Das ist richtig. Und ein Grund duerfte eben das offenbar etwas strengere Urheberrecht in Deutschland sein. Und ich vermute, dass Google das Prozessrisiko hoeher einschaetzt als manche Fanbois. Ein anderer Grund koennte auch der Streit um das LSR sein und dass Google nicht auch noch eine Urheberrechtsdebatte in Deutschland fuehren will.
@alter Jakob:
Danke für die Info! Dann habe ich ja fast „Glück“, denn an die über 98% der Besucher kommen aus Deutschland. Trotzdem ist das eine Sauerei aller erster Güte.
Ich verfolge das sehr aufmerksam und wenn es sein muss, sperre ich Goole Images aus (oder versuche es zumindest). Ich muss mit meiner Seite glücklicherweise kein Geld verdienen, was aber bei Anderen genau das Gegenteil ist.
@Stephan:
Ich versteh dein Problem nicht.
-> Momentan bekommst du Besucher von Google. Schön.
-> In Zukunft nicht mehr (so viele). Nicht so schön.
Du kannst deine Bilder ja da rausnehmen, wenn das in deinem Fall besser ist. Google wird sie dir ja nicht gegen deinen Willen „stehlen“. (Das werden alle so machen!)
Also was ist daran eine Sauerei? Woraus konstruierst du deinen Anspruch, dass Google dir Besucher liefern muss?
@Andreas Roedl:
Um deine Sicht besser verstehen zu können muss ich meine ernstgemeinte Frage aus #346 nochmal wiederholen:
Wie sollte eine netzweite Bildersuche deiner Meinung nach ausschauen?
Und noch eine: Du forderst im Grunde ein Opt-In für Inhalteanbieter. Welche Folgen würden sich deiner Meinung nach aus einem Opt-In-Zwang ergeben?
@dexter: Wie waer’s nur mit Thumbnails? Klappt doch bisher ganz gut.
An die Leute, die sich über den Widerstand der Urheber wundern: Es gibt ja eine Reihe professioneller Websites, die bekanntlich von Werbung leben. Als Websitebetreiber kann man sich in einem gewissen Rahmen darauf verlassen, dass ein geringer Prozentsatz von Besuchern auf die Anzeigen klickt. Und jetzt kommt schon der springende Punkt: Macht euch bewusst, dass es zu einem großen Teil DIESE KLICKS sind, die viele professionelle Websites überhaupt ermöglichen!!
Auch wenn über die alte Bildersuche viele Besucher Seiten aufrufen „müssen“, deren Text sie gar nicht interessiert (sondern nur das Bild), so bringt dieser mehr oder weniger „nicht qualifizierte“ Besucherstrom dennoch ein Einkommen. Das ist keine sehr besucherfreundliche Tatsache, aber es ist so.
Wenn dieser „unqualifizierte Besucherstrom“ nun großteils weggenommen wird, bedeutet das einen Wegfall von Einkommen – obwohl das Bild aber weiterhin verwendet wird!
Ich betreibe selbst hauptberuflich Websites. Die Bildersuche hat auf meine Projekte keinen Einfluss. Aber ich gehe davon aus, dass einige Suchmaschinenbetreiber schon längst auch experimentieren, wie sich die Anzeige ganzer Webseiten in den Suchergebnissen umsetzen lassen könnte. (Dieser Schritt ist nur urheberrechtlich etwas schwieriger.) Deshalb habe ich mich den aktuellen Protesten bezüglich der Bildersuche angeschlossen.
Ich vergesse dabei nicht, dass ich gleichzeitig selbst auch Benutzer bin und als solcher eine tolle Suchfunktion prima finde. Andersherum scheint jedoch vielen Benutzern das Verständnis dafür zu fehlen, dass Inhalte – vor allem professionelle – ja von irgendwem geschaffen worden sind UND das diese Menschen nicht von Luft leben. Es muss deshalb einen echten Kompromiss geben.
Technische Ausweichlösungen schaden nur mehr:
a) Bilder für den Google-Bot sperren: Bei dem Quasi-Monopol von Google in Deutschland ist dies praktisch die Entscheidung, eine Website komplett aufzugeben. Das würde im Fall von Bildportalen wahrscheinlich noch nicht genug Bedauern bei der Masse der Benutzer hervorrufen. Bei der abzusehenden Weiterentwicklung, dass ganze Webseiten in die Suchergebnisse eingebettet werden, wäre das dramatischer.
b) Besuchern der Google-Bildersuche ein Vorschaubild mit Wasserzeichen o.Ä. anzeigen: Das verstößt gegen die Google-Webmasterrichtlinien (siehe http://goo.gl/7H5Ro) und wäre ein Grund, aus dem Google-Index ausgeschlossen zu werden.
Der springende Punkt ist nun immer noch, dass der Einbruch der Besucherzahlen für die betroffenen, hauptberuflichen Websitebetreiber auch ein Einbruch des (Werbe-)Einkommens ist.
Nun gibt es Benutzer, die meinen, gute Inhalte haben keine Werbung nötig, sondern können verkauft werden. Das ist jedoch leider praxisfremd:
a) Im Kostenlos-Internet ist es überhaupt sehr schwer, Inhalte zu verkaufen. Das sieht man z. B. bei den großen Internet-Zeitungen: Wie viele von denen könnten nur von ihren Abonennten leben – ohne Werbeeinnahmen?!
b) Wenn die Besucher ja kaum noch zu den Seiten der Urheber geleitet werden, wie soll der Urheber dann noch etwas verkaufen?
Wohlgemerkt: Es gibt natürlich viele schlechte Websites, die einen „Untergang“ verdient hätten. Aber um diese Websites auszufiltern, dazu hat Google u.a. ein vielschichtiges Bewertungssystem für Websites und einen Suchalgorithmus.
In der aktuellen Debatte geht es aber gar nicht um schlechte Websites; die Inhalte werden ja für gut befunden und in den Suchergebnissen angezeigt.
Übrigens: Einen weiteren Beleg dafür, dass die neue Bildersuche tatsächlich wesentlich weniger Besucher zu den Urhebern weiterleitet liefert das deutsche Bilderportal pixabay.com: „Am 25. Januar [Anm.: kurz nach der Veröffentlichung der neuen Bildersuche] ist ein spontaner Rückgang des Image Search Traffics von rund 28.000 auf etwa 4.000 Besuchen pro Tag (-70%) zu erkennen“, siehe http://goo.gl/uOrQN.
Marcel
@Dexter:
Natürlich habe ich jetzt noch kein Problem, könnte aber mal in deutlich reduziertem Traffic kommen. Ich werde die Bilder dann auch rausnehmen.
Sauerei ist es aus meiner Sicht, weil
1.) es auch deutsche Seitenbetreiber gibt, die Bilder auf ihren Seiten außerhalb Deutschland betreiben.
2.) das Copyright bei mir liegt. Verlinken ist ok (Win/Win), aber auf Google-Server laden ist Diebstahl. Deswegen werde ich dann meine Bilder dann auch nicht mehr zur Verfügung stellen.
@Stephan
Probier die neue Bildersuche mal aus (Auf der Google Homepage rechts unten auf Google.com klicken, dann auf Bildersuche), und dann erklär mir mal, was daran mehr Diebstahl ist als an der alten Bildersuche.
@alter Jakob:
Also ein bisschen so wie die jetzige Suche.
Dabei stellt sich aber auch unverändert die Frage (von SN), wo die Grenzen (der Thumbnailgröße) zu ziehen sind. Und auch die alte Suche entspricht ja dem Bild des „Diebstahls“ von A.Roedl.
Also ich würde die Frage noch immer ganz gerne von ihm beantwortet sehen …
@Stephan:
Also entsteht ihnen durch Google doch keinerlei Schaden der die Bezeichnung „Sauerei“ verdienen würde. Ganz im Gegenteil. Google schickt ihnen Besucher, die ohne Google nicht zu ihnen kommen würden. Derzeit mehr, später weniger.
Google zwingt sie zu nichts.
von mir?
@SN:
#2^8
@Andreas Roedl:
Sie empfehlen auf ihrer Google+-Seite diesen Dienst:
http://labs.echonest.com/Uploader/index.html
Danke. In mehrfacher Hinsicht eine sehr interessante Empfehlung von ihnen!
Normalerweise würde ich jetzt schreiben: Keine weiteren Fragen, Sir! In ihrem Fall möchte ich aber davon Abstand nehmen -> #372.
@Augsten:
Es öffnet sich aktuell meine Seite, rechts das kleine Bild in der Vorschau mit Link. Das ändert sich dann gravierend mit der neuen Vorschau, wo meine Bilder bei Google liegen. Urheberrecht?
@Dexter:
Richtig, Google zwingt mich zu nichts, weswegen ich dann auch abschalten werde, wenns soweit sein sollte.
Für mich (und das ist meine persönliche Meinung) ist es nach wie vor eine Sauerei, was Google vor hat.
@Stephan: Wieso liegen die Bilder bei Google?
@377: „Google schickt ihnen Besucher, die ohne Google nicht zu ihnen kommen würden.“ –> Ja, aber auch anders herum: Google stellt auf seinen Seiten Inhalte dar, die es ohne die Arbeit anderer Menschen nicht gäbe! Und bisher gab es eben die stillschweigende Übereinkunft, dass Google nur kleine Ausschnitte dieser Inhalte zeigt, wodurch interessierte Besucher angehalten sind, zur Urheberseite zu klicken.
„Google zwingt sie zu nichts.“ –> Richtig. Aber falls sie es praktisch finden, dass im Internet sehr viel kostenfrei zugänglich ist: Ihnen ist sicher bewusst, dass Sie an dem Ast sägen, auf dem Sie sitzen?! Denn den Websitebetreibern, die Ihre Inhalte nur aufgrund von Werbung und gewisser Besucherströme kostenlos anbieten können, denen sagen Sie im Prinzip: „Wenn’s euch nicht passt, geht doch!“ Und wenn dieser kaltschnäutzigen Argumentation viele Websitebetreiber folgen und ihre Portale schließen würden, was wäre die Folge? Genau, weniger freie Inhalte. Dann würden sich sicherlich einige Portale auf Bezahlinhalte umstellen. Aber was wäre so ganz nebenbei wiederum davon eine Folge? Wissenszugang nur noch für die, die es sich leisten können! Usw. usf. …
Das koennte der Anfang vom Ende des Google Hypes sein. Googles einziges Geschaeftsmodell sind Advertisements, welches sie krampfhaft zu verteidigen versuchen. Damit dies auch weiterhin funktioniert muessen alle Benutzer die Suche benutzen und wie macht man das am Besten? Man laesst die Benutzer einfach nicht mehr aus dem Browser raus und zeigt IMMER die Suchleiste. Deswegen wurden auch die Google Apps entwickelt damit die Benutzer nicht mehr das Browserfenster verlassen muessen. Was daran innovativ ist verstehe ich schon lange nicht mehr. Es gab schon lange vor Google Suchmaschinen nur war noch niemand so dreist mit Ads richtig abzugreifen. Zum Glueck gibt es Alternativen zu Google. Ich koennte mir vorstellen das sich bis zum Jahr 2020 ohnehin niemand mehr so richtig fuer Google interessiert.
Dieser Blog zeigt ja heute schon das Google nichts anderes mehr einfaellt um Geld zu verdienen bzw. Mehrwerte zu schaffen. Hoffentlich wachen die Google Anhaenger bald mal auf und werden waehlerisch. Dann „entgoogelt“ sich die Welt ganz schnell von selber.
Nicht ganz objektive Gruesse aus Seattle und Danke fuer diesen Blog :-)
(ich hoffe der Code kommt unbeschädigt durch)
Das Problem ist, dass man im Internet so leicht verlinken kann und dass Browser Bilder so einfach inline Anzeigen können.
Von einer zulässigen Verlinkung
<a href=“http://example.com/bild.jpg“>Bild</a>
zu einem unzulässigen Einbinden
<img src=“http://example.com/bild.jpg“ alt=“Bild“>
ist es nur eine minimale Code-Änderung.
Es gibt sogar Browser-Addons dafür, die in Foren nach verlinkten Bildern suchen und den Code im anzeigenden Browser so ändern, dass das Bild direkt inline angezeigt wird. Das kann man technisch einfach nicht verhindern.
Wenn ich Sachen frei im Internet zur Verfügung stelle, d.h. ohne Login-Schranke und ohne spezielle Nutzungsbedingungen, darf verlinkt werden. Und ob nun in der ersten oder zweiten Variante verlinkt wird, ist nur ein kleiner technischer Unterschied.
„Was haben sie (die Römer) je als Gegenleistung erbracht, frage ich.“
„Das Aquädukt.“
„Was?“
„Das Aquädukt..“
„Oh. Jajaja. Das haben sie uns gegeben, das ist wahr.“
„Und die sanitären Einrichtungen..“
„Oh ja. Die sanitären Einrichtungen. Weißt Du noch, wie es früher in der Stadt stank?.“
„Also gut ja, ich gebe zu, das Aquädukt und die sanitären Einrichtungen, das haben die Römer für uns getan.“
„Und die schönen Straßen..“
„Ach ja, selbstverständlich die Straßen. Das mit den Straßen versteht sich ja von selbst, oder? Abgesehen von den sanitären Einrichtungen, dem Aquädukt und den Straßen…“
„Medizinische Versorgung….“
„Schulwesen….“
„Die öffentlichen Bäder….„
@SvenR:
Jaja, aber sonst?
@SvenR:
Ich koennte mir vorstellen das sich bis zum Jahr 2020 ohnehin niemand mehr so richtig fuer die Römer interessiert.
@Volker Leitzgen:
Nunja. Google betreibt die Infrastruktur und DEN Marktplatz für das verbreitetste Mobilbetriebsystem.
Ich halte ihre These (oder sollte man besser „Hoffnung“ sagen?) für haltlos.
Stellt Euch mal vor, da wäre jemand, der alle Inhalte von Zeitschriften einscannt.
Jetzt kommt jemand, der etwas sucht. Weil es der Marktführer ist, wendet der, der etwas sucht sich an den, der dafür spezialisiert ist, etwas zu finden. Der, der etwas findet sagt nun NICHT MEHR dem, der etwas sucht: „Ja, das findest Du in dem und dem Magazin. So sieht das dann aus.“ Und zeigt ihm eine Voranzeige, SONDERN, „Ja, das hab‘ ich hier (und dann grau auf dunkelgrau einen Texthinweis: ‚Das gibt es auf der Seite …, womöglich hat der Anbieter auch irgendwelche Copyright-/Urheber-Hinweise auf seiner Seite)“.
NATÜRLICH ist das einfacher für den Sucher. Er braucht weder ein Magazin zu kaufen, noch irgendwo anders hinzugehen, ABER es wird ihm sehr leicht gemacht, Urheber- und Nutzungsrechte zu ignorieren. Die gibt es aber. Ich möchte da gerne mal bei den „Selbstbedienern“ anfragen, ob die eigentlich wissen, wie teuer Kameras, Objektive und Hintergründe (Stichwort e ‚Blitzanlage‘,’Hohlkehle‘) sind.
Und an alle, die meinen, es gibt jetzt ja mehr Hinweise auf die originäre Website: Das ist oft gar nicht der Urheber. Oft sind es gekaufte=lizensierte Fotos. Oft wird der Fotograf unterhalb des Fotos mit Copyright-Vermerk genannt. Wo findet sich DAS bei der google.com Suche?
Google wird in der google.com-Suche zu einem Selbstbedienungsladen, der Urheber- und Lizenzrechte mit Füßen tritt und die Hemmschwelle für den ungesetzlichen Gebrauch der Fotos herabsetzt.
Nachtrag:
Ich gehöre nicht zu den chronischen Google-Bashern. Meistens mußte ich barrierefrei programmieren und hielt mich deshalb von Javascript fern – und freue mich umso mehr auf HTML5. Dennoch habe ich JQuery und die Möglichkeiten gesehen. Und ich habe mich immer gefragt, warum machen die das. Warum hat Google da diese Farm Programmierer , die nichts geldwertes schaffen, warum diese öffentlich zugängliche Bibliothek?
Davor gab es schon Google-Maps. Das kostet Google doch Geld. Warum kann das jeder nutzen, obwohl Google doch sicher Lizenzen an die Karten-Hersteller zahlt. Kostenfrei ist das nun nicht mehr, aber in einem durchaus adäquaten Rahmen.
Google-Fonts. Warum machen die das. Einen guten Font mit allen Zeichen herzustellen, ist richtig Arbeit. Warum stellt Google, die Fonts kostenfrei zur Verfügung? Andere Anbieter wollen dafür Geld (und das finde ich legitim).
Google ist börsennotiert. Ich glaube nicht, dass, wenn die umgreifende Abhängigkeit entstanden ist, nicht der Zahltag kommt.
Einen Punkt verstehe ich noch nicht ganz: Neben der Verletzung der Urheberrechte geht es im Wesentlichen ja um einen Verlust von Werbeeinnamen seitens der Websitebetreiber durch die neue Bildersuche. Die Werbeeinnahmen erhalten die meisten Websitebetreiber durch Google AdSense. Da Google hier kräftig mitverdient, hieße das doch, dass Google sich selbst untergräbt. Denn mit der Bildersuche verdient Google ja (noch) kein Geld?! (Zumindest sehe ich keine Werbung in den Bildersuchergebnissen.) …
Ich habe mir gerade mal auf google.co.uk die neue Suche angeschaut und muß sagen das ich begeistert bin. Und das sage ich ausdrücklich als Photograph.
Mir bringen die Zugriffe über die Bildersuche eh nur sehr bedingt was und jemand der sich für den Urheber eines gefundenen Bildes interessiert wird dann wohl auch die Seite besuchen denke ich.
Mag sein das es für die Leute bitter ist die von Adsense und Co leben, bei einem Photograph sollte das eigentlich nicht so sein und wenn doch dann macht er wohl was falsch.
@Chico, 388.
– A erlaubt B, ein Bild von A auf Bs Webseite (und nur dort, bei gleichzeitigem Hinweis auf den Urheber) zu nutzen.
– B verhindert nicht, dass das Bild direkt (also ohne Hinweis auf den Urheber) abrufbar ist.
– C ruft das Bild bei B ab und nutzt es ohne Erlaubnis.
Frage: Wer hat Schuld? Ihrer Meinung nach also D?
@389 „Warum machen die das?“
Weil Google ein technologiegetriebenes Unternehmen ist, das der Philosophie anhängt, wenn man ein Produkt hat, das geil genug ist, wird einem früher oder später schon ein Weg einfallen, wie man damit Geld verdienen kann. Die Suchmaschine hat Google als Startup auch entwickelt ohne die leiseste Idee, wie man damit Geld verdienen kann. Damals war New Economy, da war das die Regel. Irgendwann haben sie dann Sheryl Sandberg angeheuert, die Adwords erfunden hat, womit Google immer noch den Löwenanteil seines Umsatzes macht. Und genau so funktioniert Google heute noch.
P.S.: Zum Thema Adsense und Google schneidet sich doch mit der neuen Bildersuche und weniger Traffic auf den einblendenden Seiten damit ins eigene Fleisch: Glaube ich nicht. Wie bei Adwords kostet eine Adsense-Anzeige den Werbekunden nur Geld, wenn auch tatsächlich draufgeklickt wird. Und der ganze sinnlose traffic, der sich die Seite im Frame gar nicht anschaut, wähend er auf dem Google Frame Rechtsklick –> Download macht, klickt da eher nicht drauf …
Mein Einbruch auf meiner Seite liegt bislang bei etwa 6%. Irving Washington hat diese Geschichte, mit seiner Kunstfigur „Diedrich Knickerbocker,“ den Yankees, schon 1812 vorausgesehen („A history of New York City“). In dieser Geschichte war es Imperialismus oder Gegenkolonisation was von Großbritannien ausging und wovor die Holländer in New York das Weite suchten. Sie hätten nur „ja“ sagen müssen. Es war ja dann vielleicht doch alles zum Besten. Die U.S.A. wurden zur Supermacht. Die Aufrgegung setzt etwas spät ein. Die Geschichte wiederholt sich hier vielleicht und man muß womöglich noch einmal den Nachkommen dieses Kulturkreises den „Diedrich“ machen. Dann ist das Kapitel wohl endlich abgeschlossen. So, eigentlich ist es immer noch das selbe Spiel Holland-England.
Erstens finde ich es, wie oben beschrieben, aus urheberrechtlicher Sicht eine Sauerei, aber auch aus Sicht des Inhaltes. Ein Bild kann je nach Kontext eine ganz andere Bedeutung haben. Es kann einem dann ganz schnell einen falschen Ruf bescheren, wenn man ein Bild veröffentlicht, dass aber immer ohne Kontext gelesen wird…
Eine Urheberrechtsverletzung dürfte in der neuen Bildersuche nach den Thumbnail I und II – Entscheidung des BGH wohl nicht vorliegen (http://www.rechtsanwalt-metzler.de/recht/verletzt-die-neue-google-bildersuche-das-urheberrecht/).
Kein Wunder, die neue Suche in D hat ja auch keine Vorschaubilder. Wieso sollte denn das bisher zulässige jetzt unzulässig werden.
Weil ich alles andere jetzt aber schon oft genug geschrieben habe (und trotzdem noch widersprechen muss), zitiere ich mal aus ihrem Link, der das ganze dann doch im Wesentlichen korrekt wiedergibt. Da finde ich die folgenden (richtigen) Hinweise:
„Tatsächlich könnte die neue Google-Bildersuche in Deutschland schlicht illegal sein.“,
„Ob sich die Thumbnail-Regelung nun aber auch auf große Bilder ausdehnen lässt, ist mehr als fraglich.
bzw. dass es fraglich sei „ob die Wiedergabe als größeres Bild noch eine ’nach den Umständen übliche Nutzungshandlung‘ wäre“ (was ich insbesondere bei gleichzeitiger Nutzung von Thumbnails für unwahrscheinlich halte). Und als abschließenden Satz:
Eben.
Mittlerweile habe ich einmal bei Amazon einen Buchtitel gewählt und diesen dann in Google -Bildern lokalisiert und angeklickt. Google – Bilder zeigt eine blanke, leere oder weiße Seite und (rechte Spalte) den Hinweis auf Amazon als Quelle für das Bild (Buchumschlag/Titel). Somit unterbindet Amazon erfolgreich das Hotlinken und behält seine Bandbreite. Wer kann das noch so kodieren? Oder darf nur Amazon dies ungestraft? Ist das die Antwort? Oder können wir das auch? Das wäre schon einmal eine vorläufige Abhilfe. Vielleicht hat jemand dieses Ereignis ebenfalls auf anderen Seiten gefunden? Es wäre doch gut dies zu verfolgen.
@Frank Steineck/399
Sind Sie sich sicher, dass Sie die neue Bildersuche verwenden?
Dieser Link führt in meinem Chrome Browser zur neuen Bildersuche mit den Amazon.de-Bildern eingebettet.
Derselbe Link führt in meinem IE8 Browser zur alten Bildersuche, mit der von Ihnen beschriebenen Frame-Darstellung.
@Dieter/400
Ich bin absolut sicher, dass es so war, gestern.
Ich suche mir (gerade jetzt) zur Verifikation meiner oder Ihrer Beobachtung diese URL heraus …. http://www.amazon.de/Shades-Grey-Geheimes-Verlangen-Roman/dp/3442478952/ref=sr_1_2?s=books&ie=UTF8&qid=1360742904&sr=1-2
Ich notiere „Shades of Grey, Brandel“ (der Buchtitel bei Amazon)
Ich probiere (Mozilla Firefox“) Suche: „Shades of Grey, Brandel“
Bekomme das Suchergebnis im Googlekatalog erste Seite oben, einige Einträge.
Ich suche nun in Google-Bilder: „Shades of Grey, Brandel“
Ich stelle fest Sie haben recht.
Das muss ich nun untersuchen. Gestern habe ich das gemacht mit:
Selber Suchvorgang, nachdem ich im Google Katalog „Free Ride, Robert Levin“ gefunden habe.
Also noch ein Versuch: Der Google-Eintrag ist im Katalog.
Nun die Bildersuche mit dem Wortlaut: Anstatt der leeren Seite nun wie anderswo die von Google hotgelinkte Seite. Das ist was auch Sie festgestllt haben.
Ich versichere gestern war das noch nicht so.
Ich schließe daraus, daß sich dies seither geändert hat, weiß aber nicht was geschehen sein könnte.
Vermutlich ist das nun nicht ganz einfach zuverlässig nachzuvollziehen. Das ist nun eine ganz andere Situation geworden. Dazu kann ich momentan nichts weiter beitragen. Vielleicht kann doch jemand mit der Tatsache etwas anfangen, dass es so war für den Google crawler. Danke für den Hinweis
@Dieter/399
@frank Steineck/400
Wenn Sie die folgende URL benutzen, sollten Sie mit Firefox einen leeren Google Frame, wie ich gestern, bekommen:
http://www.google.de/imgres?um=1&hl=de&tbo=d&biw=1680&bih=915&tbm=isch&tbnid=n8bmH6znAKLUnM:&imgrefurl=https://twitter.com/RobertBLevine_&docid=3TkTBZjQrjD53M&imgurl=https://twimg0-a.akamaihd.net/profile_images/1407898354/Free-Ride-3D.png&w=313&h=500&ei=L1QbUffaE83csgbsx4CQBw&zoom=1&iact=hc&vpx=860&vpy=247&dur=730&hovh=284&hovw=178&tx=75&ty=163&sig=112553984069764301941&page=1&tbnh=158&tbnw=105&start=0&ndsp=44&ved=1t:429,r:14,s:0,i:121
Ich bin damit wieder auf den Frame, wie gestern, gelangt. Jetzt bin ich aber ein wenig mehr erleichtert. Vielleicht ist da doch eine vorläufige Abhilfe potentiell geblieben. Wenn ich diese URL in Google Chrome eingebe, komme ich ebenso auf den leeren Frame mit dieser Adresse:
http://www.google.de/imgres?um=1&hl=de&tbo=d&biw=1680&bih=915&tbm=isch&tbnid=n8bmH6znAKLUnM:&imgrefurl=https://twitter.com/RobertBLevine_&docid=3TkTBZjQrjD53M&imgurl=https://twimg0-a.akamaihd.net/profile_images/1407898354/Free-Ride-3D.png&w=313&h=500&ei=L1QbUffaE83csgbsx4CQBw&zoom=1&iact=hc&vpx=860&vpy=247&dur=730&hovh=284&hovw=178&tx=75&ty=163&sig=112553984069764301941&page=1&tbnh=158&tbnw=105&start=0&ndsp=44&ved=1t:429,r:14,s:0,i:121
Das verifiziert was ich fand und auf diese Weise wieder finde. Es zeigt aber auch, dass die Ergebnisse unterschiedlich zustande gebracht werden können (mit, bzw. ohne gefülltem Frame). Das scheint mir, weniger von Amazon her, dann eigenartig.
@Frank Steineck
Über google.de erreichen Sie die alte Bildersuche und über google.com die neue Bildersuche.
Siehe Kommentar #11.
@Dieter/399
Ich gehe davon aus, dass Sie den Link geklickt haben. Allerdings versucht der Sie nun anderswo hinzuleiten. Das konnte ich nicht voraussehen. Tun Sie es also bitte dennoch, denn im Weiterleitungshinweis werden Sie darauf hingewiesen, dass Sie zur vorigen Seite zurückkehren können. Javaskript müssen Sie allerdings erlauben. Haben Sie das getan, so sehen Sie einen Frame in dem der Verweis (rechte Seite) auf die „Website mit diesem Bild“ rechts oben zu sehen ist. Der Google-Frame links ist hier leer und das ist worauf ich von Anfang an hinweise. Versuchen Sie es noch einmal. Danke. Was Sie mir sagen ist auch richtig, doch meine ich, bitte korrigieren Sie, es ist nicht mein Thema. Ich will wissen wie das möglich ist und sonst nichts. Ich hoffe wir kommen nun dahin, obgleich mir scheint das Thema zu Google bilder schläft ein. Unten sehen Sie was geschieht, wenn Sie die Links klicken. Mit dem obigen Hinweis kommen Sie dann dort hin wohin ich gewiesen habe. Damit schließe ich diesen Dialog meinerseits. Als ich den Link den ich Ihnen gegeben habe nochmals (hintereinander) im Posting angeklickt habe kam ich allerdings direkt auf unterstehenden Link, der das Ziel dieser ganzen Darlegung war. Jetzt kam ich nicht mehr auf den Weiterleitungshinweis, sonders direkt auf das Ziel.Von hier aus komme ich zur Seite des Anbieters, ohne dass Google noch weiter dazwischen funkt. Ich denke es ist deutlich wovon ich spreche:
http://www.google.de/imgres?um=1&hl=de&tbo=d&biw=1680&bih=915&tbm=isch&tbnid=n8bmH6znAKLUnM:&imgrefurl=https://twitter.com/RobertBLevine_&docid=3TkTBZjQrjD53M&imgurl=https://twimg0-a.akamaihd.net/profile_images/1407898354/Free-Ride-3D.png&w=313&h=500&ei=L1QbUffaE83csgbsx4CQBw&zoom=1&iact=hc&vpx=860&vpy=247&dur=730&hovh=284&hovw=178&tx=75&ty=163&sig=112553984069764301941&page=1&tbnh=158&tbnw=105&start=0&ndsp=44&ved=1t:429,r:14,s:0,i:121
Es sieht aus wie eine Ausnahme, denn der Frame ist leer, während man das ganze Bild sonst nur zuerst so bekommt wie es derzeit ebn allgemein läuft, bevor man auf die Seite des Abieters kommen kann. Ich möchte gerne wissen wie das möglich sein kann.
@Frank Steineck
Ich befinde mich nicht in Deutschland. Daher habe ich keine Weiterleitung zwischen .com and .de. Entschuldigung, das habe vergessen. Das hat sicher zur Verwirrung beigetragen.
Die alte Google-Bildersuche verwendet Frames. Viele Webseiten (so auch twitter.com) verwenden sogenannte Framekiller um die Einbettung in fremde Webseiten zu verhindern. Es ist keine Ausnahme vonseiten Google.
@Dieter
„Framekiller“! Das ist es was ich nicht gewusst habe. Wikipedia nennt sie auch „framebuster“ und „framebreaker“ wie ich durch Ihren Link oben lerne. Nun haben wir ein verstecktes Datum mehr hervorgezogen. Danke. Diese Geschichte von „Google bilder“, bzw. „Google images“ die dieses Blog-Thema „Google dummdreist“ usw. bewirkte, ist im Bewusstsein der Öffentlichkeit noch ambivalent verankert. Google jedenfalls macht keinen Hehl daraus, soweit ich das beobachte, dass für Google die Suchmaschinenphase zu Ende ist/geht. Man merkt das auch an Suchergebnissen verbreitet. Ich höre da immer wieder etwas von Googles Positionierung mit „Knowledgeexperts“. Die gehen also auf die Verwertung dessen was sie haben über und andere Anbieter sollen gefälligst Lückenbüßer machen. Ich nenne diese Oberflächlichkeit für die Suche entsprechend „Designsuche.“ Suchen wird da eine Pseudoangelegenheit, denn es ist nicht mehr viel zu finden. Dadurch entsteht eine Verzögerung der Internetkultur, denn gleichzeitig hockt sich Google blockierend auf seine Position, bis sie Google abgerungen wird. Das erscheint mir langwierig zu werden. Ich persönlich versuche meine Sitemap anderen Crawlern verstärkt anzubieten. Allerdings muss man deren Ins & Outs lernen. Yahoo, so glaube ich beispielsweise möchte einen „urlist.txt“. Da haben außer mir wohl viel Teilnehmer ebenfalls einiges an Lernbedarf zu konfrontieren. Daneben meine ich sollte man das Publikum anregen sein Suchverhalten den Bedingungen anzupassen. Die „Abhilfen“ werden sich freilich nach und nach erst abbilden.
Apropos dreist und dumm, ganz offensichtlich muss man dem Herrn Niggemeier erklären, wie das Internet funktioniert…
Also gut: Das Internet wurde erschaffen, um den diskrimierungsfreien Austausch von Daten zu ermöglichen. Das bedeutet: Alles im Intgernet ist eine Form von Daten und kann ungehindert ausgetauscht werden. Und das ist auch gut so.
Nun gibt es Länder, die ihren Bürgern zu gestehen, sich vollkommen frei zu äußern. Dazu gehören die USA mit ihren berühmten First Amendment Rights. Dazu korrespondieren gibt es dort den Fair Use, die die Nutzung von an sich kopiergeschützten Materialien in diesem Sinne regelt. Und es gibt Länder wie Deutschland, die weder das eine noch das andere kennen. Darauf nimmt das Internet keine Rücksicht.
Lange Rede, kurzer Sinn: Wer nicht will, dass sich seine Bilder unkontrolliert verbreiten, darf sie nicht ins Internet stellen. Wer nicht will, dass sich seine Bilder in einer bestimmten Qualität unkontrolliert im Internet verbreiten, der stellt sie eben in einer schlechteren Qualität ein und bietet eine Dienstleistung an wie Hochglanzdruck o.ä. (Deviantart funktioniert beispielsweise so. http://www.deviantart.com/ )
Ein weiteres Leistungsschutzrecht für Fotografen will hoffentlich niemand. Das wäre dann wirklich dreist und dumm.
@407: Die USA kennen auch keine absolute Meinungsfreiheit. Auch dort gibt es Straftatbestände, die sich auf das Verbreiten von offenkundig Unwahrem beziehen. Vollkommene Freiheit des Wortes ist utopisch – oder dystopisch, je nachdem.
Wo genau kommt die Info her, dass das Internet zum freien Austausch von Informationen geschaffen wurde? Ja, dafür wird es (unter anderem) benutzt, aber ist das der ursprüngliche Daseinszweck? Ich meine mich zu erinnern, dass da das Militär dran beteiligt war, und freier Informationsaustausch ist eher nicht in deren Interesse.
Und nein, nur weil es im Internet verfügbar ist, heißt das nicht, dass ich als Rechteinhaber die totale Freigabe erteilt habe. Das hat absolut nichts mit einem „neuen Leistungsschutzrecht“ zu tun, sondern fällt unter das klassische Urheberrecht. Man mag zu diesem Recht stehen, wie man will, aber es ist heutzutage gültig, und wer dagegen verstößt, muss mit den Konsequenzen leben, egal, ob er/sie/whatever das online tut oder nicht.
„Fair Use“ bezieht sich ausdrücklich auf die Verwendung in Zitaten, Parodien und anderen Materialien, die der Bildung und Anregung geistiger Produktionen dienen. Was das mit dieser Sache zu tun hat, erschließt sich mir nicht so ganz.
Schließlich: Die angesprochenen Maßnahmen von Deviantart und vergleichbaren Seiten sind dem Pragmatismus geschuldet, dass man sein HQ-Artwork nicht irgendwo wiederfinden will, wo es jemand widerrechtlich ins Netz gestellt hat. Das ist eine Diebstahlschutzmaßnahme und nichts anderes.
@ 408: Das Militär wollte bei der Konzeption des Arpanet verhindern, dass im Falle eines Atomkriegs die Verbindungen zwischen den Rechnern zusammen brechen, nur weil einige Knoten ausfallen. Wird also irgendwo einen Information blockiert oder nicht weitergeleitet, wird das als Störung empfunden und umgangen.
Copyright ist Aberglaube. Oder weniger polemisch: Das Copyright nützt einigen wenigen großen Konzernen, weil sie so ein Monopol aufbauen können. Dadurch wird eine bestimmte Ware künstlich verknappt und kann zu einem überhöhten Preis verkauft werden. Allen anderen Menschen schadet es, weil sie an Informationen nicht heran kommen oder teuer dafür bezahlen müssen.
Recht, das niemand befolgt und sich nicht durchsetzen lässt, steht nur auf dem Papier, ist jedoch bedeutungslos.
Zum hundertsten Mal: Wenn ein körperlicher Gegenstand – etwa ein Fahrrad . gestohlen, dann ist er weg und der Besitzer kann ihn nicht mehr nutzen. Wenn ich im Internet ein körperloses Bild kopiere oder verlinke, dann ist es noch da und der Nutzer kann voll darüber verfügen. Und wenn er ein Wasserzeichen darin unter gebracht hat, dann mache ich sogar noch Werbung für ihn. So, what?
Ich muss feststellen, dass ich bei der Google-Bildersuche IMMER nur auf die Seite komme, auf der das Bild eingebunden ist, ist es z. B. auf der Seite der Süddeutschen Zeitung, dann kommt die ganze Seite und nie nur das Bild. Das war bei mir nie anders. Entweder wurde das längst wieder geändert oder es war nie wirklich so, wie oben beschrieben. In jedem Falle scheint die Aufregung mal wieder übertrieben zu sein.
Komischerweise macht Bing das schon seit langem genau so:
http://www.bing.com/images/search?q=trust+me+engineer
Klick auf den Thumbnail zeigt das große Bild direkt in Bing…
Verstehe ich da was falsch?
@219:
Mal angenommen, ich schreibe einen Blogeintrag über Google und möchte den mit einem schönen Bild von Eric Schmidt illustrieren. Die FAZ hat ein schönes Bild von Eric Schmidt. Darf ich zur Illustration den Satz hinzufügen „Um ein Bild von Eric Schmidt zu sehen, gehen Sie auf FAZ.de suchen dort nach Eric Schmidt, drücken auf den ersten Eintrag und scrollen drei Seiten nach unten, dort das erste Bild links.“?
Was nun, wenn es einen Browser geben würde, der diesen Satz versteht, den Anweisungen folgt und automatisch diesen Satz durch das Bild ersetzt?
Darf ich mir also eine Beschreibung, wie man sich das Bild zur Illustration besorgen kann, auf meiner Seite veröffentlichen?
Wenn nein, wie sollte es verhindert werden? Wenn ja, wieso wäre diese Technik erlaubt, jedoch andere Techniken nicht?
> Und macht es einen Unterschied, ob ich das Bild bei der FAZ runter– und hier wieder hochlade oder es einfach direkt von der externen Seite einbinde?
Ja, macht es, denn wenn es nur eingebunden wird, hat der ursprüngliche Besitzer immer noch die Möglichkeit die Resource im Nachhinein a) zu verändern b) zu löschen c) entscheiden, wer die Resource runterladen kann.
Will sagen: das Problem ist, dass es heute technische Möglichkeiten gibt, Referenzen automatisiert nachzugehen. Es kann dafür keinen effektiven Schutz geben.
Google, mit seinen eigenen kommerziellen Interessen, ist natürlich unsensibel, wenn sie das so mit der Brechstange durchsetzen wollen.
@409: „Recht, das niemand befolgt“? Woher genau will man das wissen? Führt irgendjemand Strichlisten über NICHT heruntergeladene Bilder/Lieder/sonstiges geistiges Eigentum? Es hat sich schon bei der Musik herausgestellt, dass die meisten Leute für die Lieder auch bezahlt hätten, wenn es denn zu Napster-Zeiten entsprechende Angebote gegeben hätte – heutzutage klappt es ja anscheinend, iTunes ist jedenfalls noch nicht pleite.
Natürlich sind solche Vergehen nicht mit „echtem“ Diebstahl vergleichbar, bei dem dem Bestohlenen sein Eigentum nicht mehr zur Verfügung steht. Wo habe ich das behauptet? Das war aber beim Urheberrecht noch nie wirklich das Problem – Manuskriptdiebstahl oder Raub von Mastertracks aus Musikstudios sind doch eher seltene Ereignisse, und trotzdem existiert dieses Recht nun einmal. Man darf das für überflüssig und konzerngesteuert halten, aber die Entscheidung darüber, was legal ist und was nicht, liegt nicht bei Einzelpersonen. Das nennt man einen Rechtsstaat.
[quote]Man darf das für überflüssig und konzerngesteuert halten, aber die Entscheidung darüber, was legal ist und was nicht, liegt nicht bei Einzelpersonen. Das nennt man einen Rechtsstaat.[/quote]
Ich befolge nur Gesetze, die ich moralisch und ethisch für sinnvoll halte. Gegen alle anderen verstoße ich, falls erforderlich. Das nennt man zivilen Ungehorsam. Dieser führt, wenn genügend aufgeklärte Bürger in unserem tollen Rechtsstaat mitmachen, dazu, daß die Gesetze den geänderten, oder schon immer vorherrschenden Moralvorstellungen, angepasst werden.
Mit obrigkeitshörigen Sesselfurzern allerdings ist kein Staat zu machen.
@Ospero #408:
Wo genau kommt die Info her, dass das Internet zum freien Austausch von Informationen geschaffen wurde? Ja, dafür wird es (unter anderem) benutzt, aber ist das der ursprüngliche Daseinszweck?
Das WWW, also der Hypertextteil des Internet, um den es hier ja auch geht, wurde tatsächlich für den freien Informationsaustausch, damals noch akademischer Natur, angedacht.(Daher gibt es in den ersten Versionen von HTTP auch keine großartige Zugriffssteuerung.)
Die prima Idee war schlicht, bildschirmlesbare, internetadressierbare Textdokumente mit Verweisen auf andere Textdokumente auszustatten. Eingebettete Bilder gab es damals übrigens noch nicht in der zugehörigen HyperTextMarkupLanguage.
Hat man sowas heutzutage wirklich nicht in der Schule? Geschichte etc.?
Das hat sich Herr Hoeness bestimmt auch gedacht. Aber ich möchte z.B. meine Gesundheit im Strassenverkehr eigentlich nicht davon abhängig machen wollen, ob Sie es moralisch und ethisch vertretbar finden, sich an eine Geschwindigkeitsbegrenzung zu halten.
Habe die Diskussion in den Kommentaren nur teilweise überflogen. Ich bitte um Entschuldigung, wenn der folgende Gedanke schon vorkam:
Ich würde nicht ganz so weit gehen, Google Dummheit vorzuwerfen. In den vergangenen Diskussionen zu Gema und Leistungsschutzrecht hat sich Google sehr clever verhalten und durch subtile Meinungsbeeinflussung der Nutzer viele Anhänger gefunden. Geradezu genial war es, in der „Verteidige-Dein-Netz-Kampagne“ die Nutzer an die Hand zu nehmen und zu ihrem Abgeordneten zu begleiten, wo die sich dann ausheulen sollten. Ob das geklappt hat werden wir anhand der Bildersuche sehen. Denn Google könnte jetzt die geschaffenen Strukturen erneut nutzen und die Nutzer bei den Abgeordneten jammern schicken. Das würde zeigen, ob und wie weit Google im Bereich der Gesetzgebung Deutungshoheit hat – ohne auf Lobbyismus in seiner althergebrachten Form unmittelbar angewiesen zu sein. Glücklicherweise ist die Welt nicht so schwarz-weiss, wie ich das gerade dargestellt habe, mein Ergebnis ist also sicher übertrieben. Aber während ich ansonsten mit Stefan Niggemeyers Artikel einer Meinung bin, bin ich doch sehr gespannt, wie sich Googles neuester Testballon weiter entwickelt.
[…] will Google nicht nur Verkleinerungen, sondern die kompletten Bilder im Originalformat zeigen. Voraussichtlich wird dies durch „Framing“ passieren. Das Bild wird dabei nicht auf den Google-Server kopiert. […]
Endlich wacht Google-Deutschland auf:
http://www.n-tv.de/ticker/Computer/Fotografen-Verband-klagt-gegen-neue-Google-Bildersuche-article10549896.html
„Hamburg (dpa) – Der Fotografen-Berufsverband Freelens will dem Internetriesen Google untersagen lassen, bei seinem Bildersuchdienst auch bildschirmfüllende Fotos anzuzeigen. Nachdem Google auf eine Unterlassungsabmahnung nicht reagiert habe, habe man beim Landgericht Hamburg Klage gegen Google eingereicht, erklärte der Verband.“
[…] Debatte um die neue Google Bildersuche löste im Web einen wahren Flächenbrand aus. Auch Martin Missfeld, meiner Meinung nach der Bilder-Guru in Deutschland , der erst vor […]
[…] Medienjournalist Stefan Niggemeier: Dreist und dumm: die neue Bildersuche von Google […]
[…] Neue Bildersuche bei Google […]
Hat sich was getan bei Google-Bilder?
Gestern öffnete ich einige Bilder bei Google-Bilder, von verschiedenen Websites und siehe da, Google zeigt diese nicht mehr im eigenen frame. War es das jetzt global oder nur in Deutschland? Führt Google nun die Besucher in anderen Ländern als Deutschland ebenso auf die Website der Hersteller des betroffenen contents (Bilder), wie vor der Umleitung auf Google frames, so etwa ab Februar dieses Jahres besonders heftig zu spüren? Das waren etwa – 20% bei mir. Die Statistik sollte jetzt dazu korrespondieren und es scheint bei mir auch so zu sein (ca. 20% oder mehr +).
Lösung gefunden für Google.de mit Firefox!
Hallo ich habe mich auch schon länger über dir Google Bildersuche geärgert weil ich immer erst auf die Google Seite gelinkt werde, anstatt direkt auf die Homepage woher das Bild stammt!
Hier ist ein Firefox / Mozilla Addon das dieses Problem behebt bei Google.de zumindest!
—> Mit dem Redirect Cleaner
https://addons.mozilla.org/de/firefox/addon/redirect-cleaner/
Ich finde die Bildersuche auf Google(.com) (meine Standardsuche, Google.com) sehr praktisch.
Es wird vom Autor dieses Textes gemotzt ohne Ende, dabei kann man das Indexieren der Bilder verhindern, dass ist technisch möglich und ich glaube Google erklärt es sogar in seinen Supportbereichen.
Aber nein, man will ja nicht von Google verschwinden, aber gleichzeitig will man nicht dass Google sich „zu viel“ schnappt… tja, entweder kein Google oder damit abfinden.
Kein Google würde weitaus mehr Trafficeinbruch bringen, das kannste mir glauben
Fantastic beat ! I wish to apprentice while you amend your web site,
how could i subscribe for a blog web site? The account aided me a acceptable deal.
I had been a little bit acquainted of this your broadcast offered
bright clear concept
Have a look at my web site find home repair contractors (Ciara)
Tja, lassen Sie sich doch komplett auslisten bei Google.
Dann findet Sie aber auch keiner mehr.
Einerseits bei Google gefunden werden zu wollen und andererseits Ansprüche zu stellen an die Leistungen dieses Anbieters…?
Was soll das denn sein????
Unverständlich.
Bei Bing ist es nach wie vor so, dass man beim Anklicken eines Bildes auf der Bildersuche nicht auf die Bildseite geleitet wird, sondern dass nur das Bild angezeigt wird. Warum wird also auf Google losgegangen, wenn Bing es noch viel extremer so macht?
[…] Debatte um die neue Google Bildersuche löste im Web einen wahren Flächenbrand aus. Auch Martin Missfeld, meiner Meinung nach der Bilder-Guru in Deutschland ;), der erst vor […]
Spot on with this write-up, I actually think this website needs far more attention. I’ll probably
be returning to read more, thanks for the advice!
I could not refrain rom commenting. Well written!
My blog webpage (Kristin)
Guten Tag Herr Niggemeier,
was ist hier eigentlich in letzter Zeit los? Ich hatte damals, als ich meinen Beitrag hier geschrieben hatte, diesen Thread abonniert, um informiert zu werden, wenn es Neues in der Diskussion gibt. Aber jetzt scheint es immer mehr Spam zu geben. Lässt sich nicht feststellen, woher das kommt, so dass Sie den Spammer (bzw. das Land) dann blocken können? Müsste sich doch mittels der IP feststellen lassen.
Zum Thema stelle ich im übrigen fest, dass sich nichts bei Google oder auch bei Bing verändert hat – man wird immer noch direkt zum Bild geleitet anstatt zu der Seite mit dem Bild, wie es eigentlich sein sollte. Aber da hier nur noch Spam kommt, scheint es mir auch, dass kaum noch jemand Interesse am eigentlichen Thema zu haben scheint – was ich schade finde.
Mit freundlichen Grüßen
Josef Deinlein
Kann es nicht sein, dass Google komplett scheiße ist? Die Suchergebnisse sind miserabel. Man sitzt teilweise Stunden vorm Rechner und findet nichts sinnvolles. Das ist nun seit über einem Jahr so.
Aber solange kein Wettbewerb entsteht, ist es wie mit dem Plastikessen. Die Masse frisst es ohne mucken.
Für mich wäre der Untergang dieses unsäglichen Amikonzerns ein Feiertag.
Das Thema ist noch besser. Ich habe einer Analyse meiner Logfiles durchgeführt. Dabei wunderte ich mich, daß ich nach dem Aufrufen meiner Fotos über die Google Bildersuche keine Einträge in meiner Logfile hatte. Es stellte sich heraus, daß es trotz intensivem Zugriff von mir nicht einen einzigen Eintrag gab. Was bedeutet das? Da in der Logfile alles zu sehen ist, bedeutet dies, daß google meine Webseite schon komplett kopiert hat und woanders speichert und allein auswertet inklusive der Zugriffe. Ich als Webseitenanbieter werde völlig ausgeschlossen. Google kopiert meine Webseite und nutzt eine Kopie um aktiv das Verhalten der Besucher zu analysieren und man meint, man sei in einem Frame auf der originalwebseite. – was nicht stimmt.
Google reißt von Jahr zu Jahr mehr vom Internet an sich.
Was mich wirklich wundert, ist, daß da die EU-Kommission oder Wettbewerbshüter nicht aktiv werden.
Der Mißbrauch der Monopolstellung ist ja offensichtlich.
Hallo in die Runde,
das Thema Bilder und Google beschäftigt mich schon lange. Ich finde es ist ein extrem wichtiger SEO Baustein, die Bilder ordentlich zu benennen und mit einem Atribut zu versehen. Nun aber meine Frage, ist das überhaupt noch nötig? Mir ist aufgefallen, das Google offenbar Bilder von Seiten egal ob benannt oder unbenannt in die organischen Suchergebnisse mit einspielt. Ich denke mal dieses Phänomen habe nicht nur ich beobachtet.
Freu mich auf eine Antwort.
Gruß sagt Daniel aus Magdeburg
Kann mich meinem Vorredner nur anschließen, Bilder sind wirklich ein wichtiges SEO Instrument. Das Google die Bilder für sich verwendet, ist eben so. Empören können wir uns darüber, aber ändern nichts. Wichtig ist auch, das man die Bilder von vornherein mit einem Atribut hinterlegt. Sicherlich können falsch benannte Bilder korrigiert werden, aber das dauert wiederum, bis Google diese Indexiert hat, so meine Erfahrung.
Artikel ist einfach sachlich falsch.
„Genau genommen kopiert Google übrigens die Bilder nicht, es bindet sie nur von der fremden Seite ein. Auf dieselbe Weise liegt das folgende, mutmaßlich urheberrechtlich geschützte Bild zum Beispiel nicht auf meinem Server, sondern ist einfach nur von der Quelle eingebunden“
Ich hatte ein Bild einfach mal umgeändert und ein anderes mit dem selben Dateinamen dafür verwendet.
Es zeigte in der Bildersuch noch mehrere Wochen! das alte nicht mehr auf meinem Server existierende Bild an.
Ach, „übrigens“ halt ich für ein doofes Füllwort.
Ich finde den Kommentar von Chrstian Scholz sehr interessant.
Es ist so Facebook, Google & Co beanspruchen so langsam das Internet für sich.
Für einen lokalen Anbieter ist es nun eigentlich wichtiger in Google Maps gelistet zu sein und gute Bewertungen zu haben als eigene Webseite.
Was Christian nicht erwähnt ist der Job und Industrie Verlust der Deutschen Webdeisgner & Programmierer zu denen ich gehöre. Dann heißt es entweder bei google als Webdesign oder in der Pizzeria als Lieferkraft.